TECHNICAL ASSET FINGERPRINT
9bfc0d5703337883bfe236bb
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
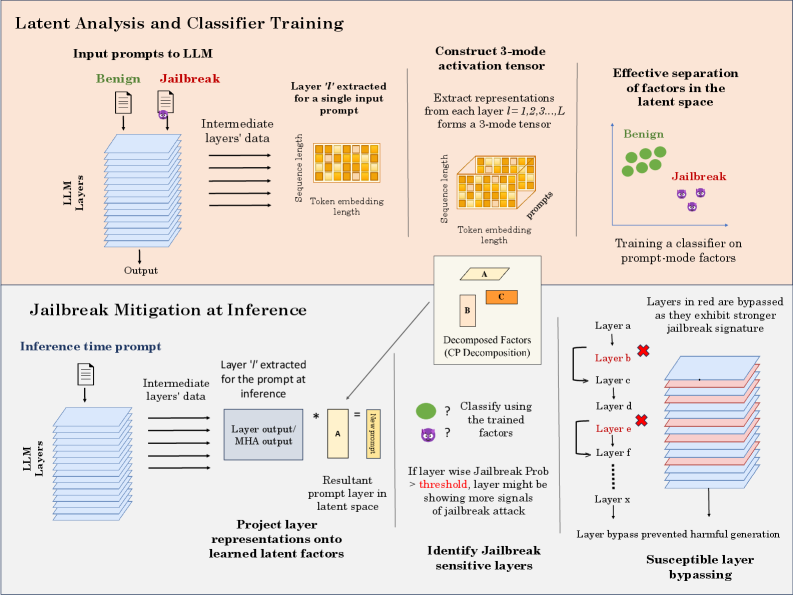
## Technical Process Diagram: Latent Analysis and Classifier Training for LLM Jailbreak Detection and Mitigation
### Overview
This diagram illustrates a two-phase technical framework for detecting and mitigating "jailbreak" attacks on Large Language Models (LLMs). The top phase focuses on **offline training** of a classifier using latent space analysis of model activations. The bottom phase describes the **inference-time application** of this classifier to identify and bypass model layers susceptible to jailbreak attacks, thereby preventing harmful output generation.
### Components/Axes & Process Flow
The diagram is divided into two primary horizontal sections:
**1. Top Section: Latent Analysis and Classifier Training (Offline Phase)**
* **Input:** "Input prompts to LLM" are shown as two document icons, labeled **"Benign"** (green) and **"Jailbreak"** (purple with a skull icon).
* **Process:**
* These prompts are fed into an "LLM Layers" stack (represented as a blue 3D block).
* "Intermediate layers' data" is extracted. A callout specifies: "Layer *T* extracted for a single input prompt," showing a 2D grid with axes "Sequence length" and "Token embedding length."
* This extraction is repeated: "Extract representations from each layer *l = 1,2,3...L* forms a 3-mode tensor." A 3D grid visualizes this tensor with axes: "Sequence length," "Token embedding length," and "prompts."
* The tensor undergoes "Decomposed Factors (CP Decomposition)," visualized as three factor matrices labeled **A**, **B**, and **C**.
* **Output/Goal:** "Effective separation of factors in the latent space." A 2D scatter plot shows green circles ("Benign") clustered separately from purple skull icons ("Jailbreak"). The final step is "Training a classifier on prompt-mode factors."
**2. Bottom Section: Jailbreak Mitigation at Inference (Deployment Phase)**
* **Input:** An "Inference time prompt" (document icon) is fed into the same "LLM Layers" stack.
* **Process:**
* "Layer *T* extracted for the prompt at inference." The extracted "Layer output/ MHA output" is multiplied (`*`) with the pre-trained factor matrix **A**.
* This results in a "Resultant prompt layer in latent space," shown as a vector labeled "latent factors."
* The system will "Project layer representations onto learned latent factors."
* Next, it will "Classify using the trained factors" (green circle and purple skull icons with question marks).
* A decision rule is stated: "If layer wise Jailbreak Prob > threshold, layer might be showing more signals of jailbreak attack."
* This leads to "Identify Jailbreak sensitive layers." A list shows layers `a` through `x`. Layers **b** and **e** are highlighted in red with a red 'X', indicating they are "bypassed as they exhibit stronger jailbreak signature."
* The final step is "Susceptible layer bypassing," showing the LLM layer stack with layers `b` and `e` visually skipped (red lines bypass them), leading to "Layer bypass prevented harmful generation."
### Detailed Analysis / Content Details
* **Key Technical Terms:** LLM (Large Language Model), MHA (Multi-Head Attention), CP Decomposition (CANDECOMP/PARAFAC), Latent Space, 3-mode Tensor, Jailbreak Attack.
* **Data Flow:** The process is a pipeline: Raw Prompts -> Layer-wise Activation Extraction -> Tensor Construction -> Decomposition -> Classifier Training -> Inference-time Projection -> Classification -> Layer Identification -> Conditional Bypassing.
* **Visual Coding:**
* **Color:** Green consistently represents "Benign" data/behavior. Purple represents "Jailbreak" data/behavior. Red is used for layers identified as sensitive/bypassed.
* **Icons:** Document icons for prompts. Skull icon for jailbreak. 'X' marks for bypassed layers.
* **Spatial Layout:** The training phase flows left-to-right on top. The inference phase flows left-to-right on the bottom, with a central connection showing the use of the pre-trained factor matrix **A**.
### Key Observations
1. **Layer-Specific Analysis:** The method does not treat the LLM as a black box. It analyzes activations at *each intermediate layer* (`l = 1,2,3...L`) to find granular attack signatures.
2. **Factor Decomposition:** The core innovation is using tensor decomposition (CP) on the 3-mode activation tensor (sequence × embedding × prompt) to disentangle the underlying factors that distinguish benign from jailbreak prompts.
3. **Dynamic Bypassing:** Mitigation is not a static filter. It dynamically identifies which specific layers in the model are most activated by a given suspicious prompt at inference time and bypasses only those layers.
4. **Threshold-Based Decision:** The system uses a probabilistic threshold ("Jailbreak Prob > threshold") to decide on layer bypassing, introducing a tunable sensitivity parameter.
### Interpretation
This diagram outlines a sophisticated, **proactive defense mechanism** against adversarial attacks on LLMs. The underlying premise is that jailbreak prompts cause the model's internal representations (activations) to deviate from a "benign" manifold in a predictable way that can be captured in the latent space of layer activations.
* **What it demonstrates:** It shows a complete pipeline from offline analysis to real-time defense. The key insight is that jailbreak attacks leave a "signature" not just in the final output, but in the *process* of computation across specific layers. By learning this signature via tensor factorization, the system can detect it early.
* **How elements relate:** The top section (training) creates the "detector" (the classifier and factor matrices). The bottom section (inference) is the "deployment" where this detector is applied to new prompts. The critical link is the projection of new layer outputs onto the learned latent factors (**A**), allowing for comparison with the trained classifier.
* **Notable Implications:**
* **Efficiency:** Bypassing only sensitive layers could be more computationally efficient than re-running the prompt or using a separate large classifier model.
* **Adaptability:** The classifier can be retrained as new jailbreak techniques emerge, updating the latent factor understanding.
* **Transparency:** This method provides some interpretability—by identifying *which* layers are sensitive, developers might gain insight into *how* the model is being manipulated.
* **Potential Limitation:** The effectiveness hinges on the assumption that future jailbreak attacks will project onto the same latent factors learned during training. Novel attacks might evade detection. The threshold setting also presents a trade-off between false positives (blocking benign prompts) and false negatives (missing jailbreaks).
DECODING INTELLIGENCE...