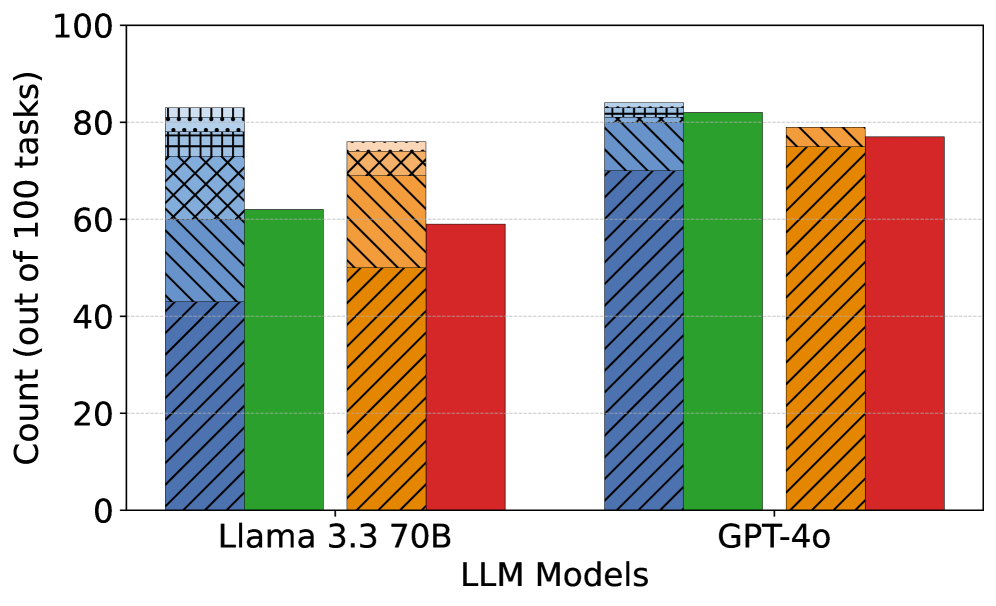
## Bar Chart: LLM Model Performance Comparison
### Overview
The image is a bar chart comparing the performance of two Large Language Models (LLMs), "Llama 3.3 70B" and "GPT-4o", across four different task categories. The y-axis represents the count (out of 100 tasks), indicating the number of tasks successfully completed by each model in each category.
### Components/Axes
* **X-axis:** "LLM Models" with two categories: "Llama 3.3 70B" and "GPT-4o".
* **Y-axis:** "Count (out of 100 tasks)" with a scale from 0 to 100, incrementing by 20.
* **Bar Colors/Categories:**
* Blue Diagonal Lines: Category 1
* Green: Category 2
* Orange Diagonal Lines: Category 3
* Red: Category 4
* **Gridlines:** Horizontal dashed lines at intervals of 20 on the y-axis.
### Detailed Analysis
**Llama 3.3 70B:**
* **Blue Diagonal Lines:** The bar extends to approximately 62 out of 100 tasks.
* **Green:** The bar extends to approximately 62 out of 100 tasks.
* **Orange Diagonal Lines:** The bar extends to approximately 75 out of 100 tasks.
* **Red:** The bar extends to approximately 60 out of 100 tasks.
**GPT-4o:**
* **Blue Diagonal Lines:** The bar extends to approximately 83 out of 100 tasks.
* **Green:** The bar extends to approximately 82 out of 100 tasks.
* **Orange Diagonal Lines:** The bar extends to approximately 79 out of 100 tasks.
* **Red:** The bar extends to approximately 77 out of 100 tasks.
### Key Observations
* GPT-4o generally outperforms Llama 3.3 70B across all four task categories.
* The largest performance difference between the two models is in the first category (Blue Diagonal Lines), where GPT-4o scores significantly higher.
* Llama 3.3 70B has a relatively lower score in the fourth category (Red) compared to its performance in the other categories.
### Interpretation
The bar chart provides a direct comparison of the performance of Llama 3.3 70B and GPT-4o on a set of 100 tasks, categorized into four distinct types. The data suggests that GPT-4o is the superior model, demonstrating higher success rates across all task categories. The specific nature of these task categories is not defined in the image, but the visual representation clearly indicates a performance gap between the two models. The consistent outperformance of GPT-4o suggests it may have a more robust architecture or a more effective training regime for the types of tasks evaluated.