\n
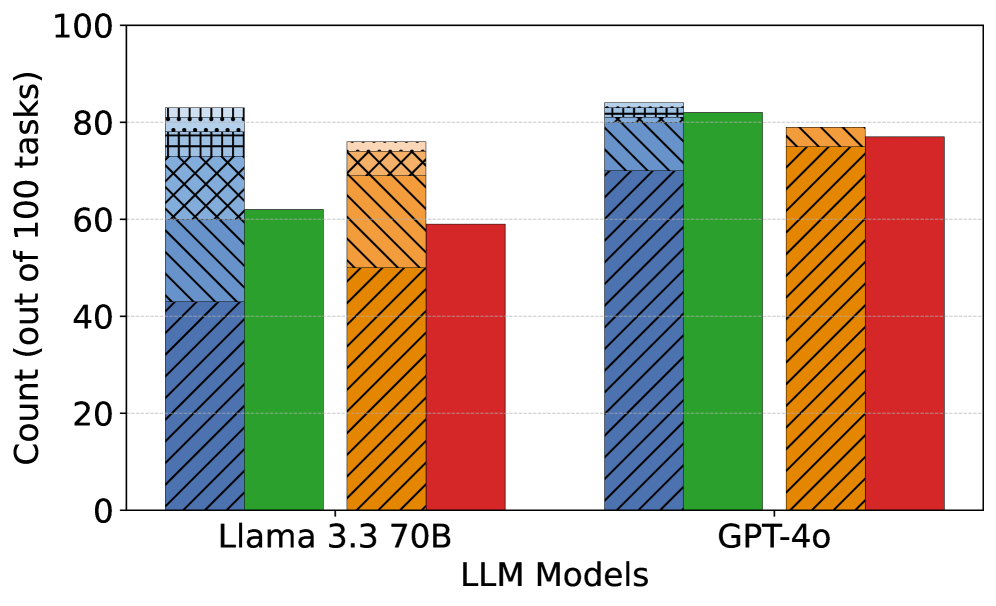
## Bar Chart: LLM Performance Comparison
### Overview
This bar chart compares the performance of three Large Language Models (LLMs) – Llama 3.3 70B, and GPT-40 – across a set of tasks. The performance is measured as the count of tasks successfully completed out of 100. Each LLM has four bars representing different performance levels, visually distinguished by color and pattern.
### Components/Axes
* **X-axis:** "LLM Models" with categories: "Llama 3.3 70B", and "GPT-40".
* **Y-axis:** "Count (out of 100 tasks)" ranging from 0 to 100, with increments of 10.
* **Bars:** Four bars per LLM, each representing a different performance level.
* **Colors/Patterns:**
* Dark Blue: Hatched with forward slashes.
* Green: Solid color.
* Orange: Hatched with backward slashes.
* Red: Solid color.
### Detailed Analysis
**Llama 3.3 70B:**
* **Dark Blue:** The bar slopes downward slightly, starting at approximately 84 and ending at approximately 78.
* **Green:** The bar is relatively flat, starting at approximately 62 and ending at approximately 60.
* **Orange:** The bar is relatively flat, starting at approximately 76 and ending at approximately 74.
* **Red:** The bar is relatively flat, starting at approximately 58 and ending at approximately 56.
**GPT-40:**
* **Dark Blue:** The bar slopes downward slightly, starting at approximately 82 and ending at approximately 79.
* **Green:** The bar is relatively flat, starting at approximately 84 and ending at approximately 82.
* **Orange:** The bar is relatively flat, starting at approximately 78 and ending at approximately 76.
* **Red:** The bar is relatively flat, starting at approximately 76 and ending at approximately 74.
### Key Observations
* GPT-40 consistently outperforms Llama 3.3 70B across all performance levels.
* The dark blue performance level is the highest for both models.
* The red performance level is the lowest for both models.
* The differences in performance between the different levels within each model are relatively small.
### Interpretation
The chart suggests that GPT-40 is a more capable LLM than Llama 3.3 70B, achieving higher counts of successful tasks across all measured performance levels. The relatively small differences between the performance levels within each model indicate that the models exhibit consistent performance across the evaluated tasks, without significant variations in success rates. The downward slope in the dark blue bars for both models could indicate a slight decrease in performance as the task complexity increases within that level. The chart provides a comparative snapshot of the LLMs' capabilities, but does not offer insights into the specific tasks or the nature of the performance differences. Further investigation would be needed to understand the underlying reasons for the observed performance variations.