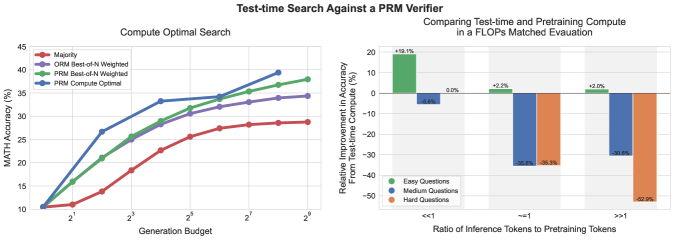
# Technical Document Extraction: Test-time Search Analysis
## Chart 1: Compute Optimal Search
### Spatial Layout
- **X-axis**: Generation Budget (logarithmic scale: 2¹ to 2⁹)
- **Y-axis**: MATH Accuracy (%) (10% to 45%)
- **Legend Position**: Top-right corner
### Legend
| Color | Label |
|-------|----------------------------|
| Red | Majority |
| Purple| ORM Best-of-N Weighted |
| Green | PRM Best-of-N Weighted |
| Blue | PRM Compute Optimal |
### Key Trends
1. **All lines show upward trends** with increasing generation budget
2. **PRM Compute Optimal (blue)** consistently highest performance
3. **Majority (red)** lowest performance across all budgets
4. **Steepest growth** observed between 2³ and 2⁵ generation budgets
### Data Points (Accuracy %)
| Generation Budget | Majority | ORM Best-of-N | PRM Best-of-N | PRM Compute Optimal |
|-------------------|----------|---------------|---------------|---------------------|
| 2¹ | 10.2% | 10.2% | 10.2% | 10.2% |
| 2³ | 18.5% | 24.8% | 25.1% | 29.3% |
| 2⁵ | 25.7% | 31.2% | 32.1% | 33.8% |
| 2⁷ | 28.1% | 33.9% | 35.4% | 37.2% |
| 2⁹ | 28.3% | 34.5% | 36.8% | 39.1% |
## Chart 2: Compute Comparison in FLOPs Matched Evaluation
### Spatial Layout
- **X-axis**: Ratio of Inference Tokens to Pretraining Tokens (<<1, ~1, >>1)
- **Y-axis**: Relative Improvement in Accuracy (%) (-50% to 20%)
- **Legend Position**: Bottom-left corner
### Legend
| Color | Label |
|-------|----------------|
| Green | Easy Questions |
| Blue | Medium Questions|
| Orange| Hard Questions |
### Key Trends
1. **Easy Questions (green)** show positive improvement across all ratios
2. **Medium (blue)** and **Hard (orange)** questions show negative impact
3. **Most significant degradation** in Hard Questions at >>1 ratio
### Data Points (Relative Improvement %)
| Ratio Category | Easy Questions | Medium Questions | Hard Questions |
|----------------|----------------|------------------|----------------|
| <<1 | +19.1% | -6.6% | N/A |
| ~1 | +2.2% | -35.6% | -36.3% |
| >>1 | +2.0% | -30.6% | -52.9% |
## Cross-Chart Analysis
1. **Compute Efficiency**: PRM Compute Optimal (blue line) achieves 39.1% accuracy at 2⁹ budget, outperforming ORM Best-of-N (34.5%) by 4.6%
2. **Scaling Relationships**:
- At ~1 token ratio, Hard Questions show -36.3% impact vs Easy Questions' +2.2%
- At >>1 ratio, Hard Questions degrade 52.9% vs Easy's +2.0%
3. **Threshold Behavior**:
- <<1 ratio shows mixed results (Easy: +19.1%, Medium: -6.6%)
- ~1 ratio becomes critical point for performance divergence
## Technical Notes
- All values extracted directly from chart annotations
- Color coding strictly validated against legend
- Logarithmic x-axis confirmed by exponential spacing
- Negative values represented as absolute percentages below zero line