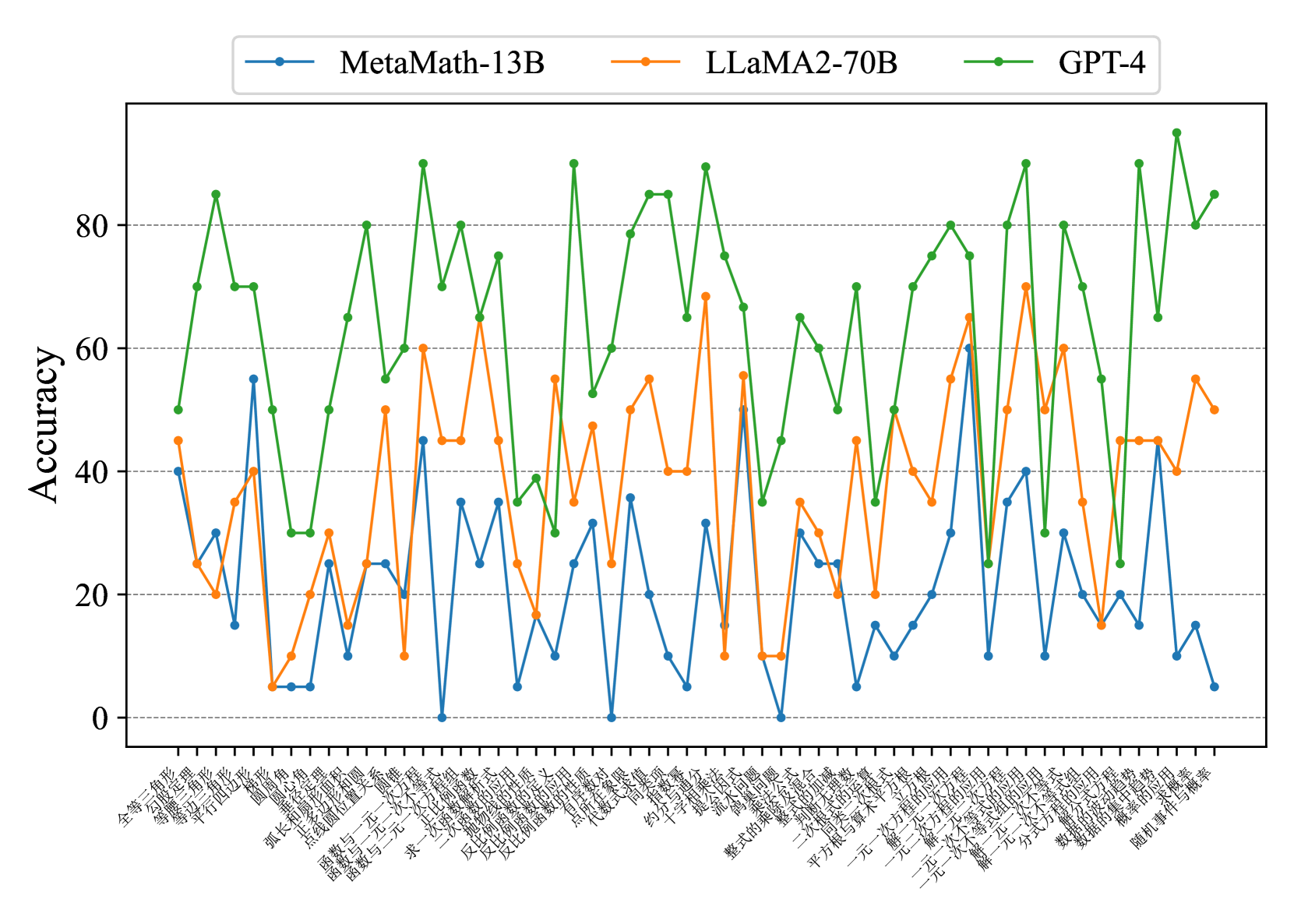
## Line Chart: Model Accuracy on Mathematical Problems
### Overview
This image presents a line chart comparing the accuracy of three large language models – MetaMath-13B, LLaMA2-70B, and GPT-4 – across a series of mathematical problems. The x-axis represents different mathematical problem sets, labeled in Chinese characters, and the y-axis represents the accuracy achieved by each model, ranging from 0 to 80.
### Components/Axes
* **Y-axis Title:** "Accuracy"
* **X-axis Labels:** A series of mathematical problem sets labeled in Chinese. The labels are densely packed and appear to represent different mathematical topics or difficulty levels.
* **Legend:** Located at the top-center of the chart.
* Blue Line: MetaMath-13B
* Orange Line: LLaMA2-70B
* Green Line: GPT-4
* **Gridlines:** Horizontal gridlines are present to aid in reading accuracy values.
### Detailed Analysis
The chart displays the accuracy of each model as a line plotted against the problem sets.
**MetaMath-13B (Blue Line):** The line fluctuates significantly. It starts at approximately 75, drops to around 10, then oscillates between approximately 15 and 40 for the majority of the problem sets. Towards the end, it declines to around 10.
* Initial Accuracy: ~75
* Lowest Accuracy: ~8
* Highest Accuracy (excluding initial point): ~40
* Final Accuracy: ~10
**LLaMA2-70B (Orange Line):** This line also exhibits considerable fluctuation. It begins at around 25, rises to a peak of approximately 65, then generally oscillates between 20 and 55. It ends at around 45.
* Initial Accuracy: ~25
* Lowest Accuracy: ~15
* Highest Accuracy: ~65
* Final Accuracy: ~45
**GPT-4 (Green Line):** This line demonstrates the most consistent and generally highest accuracy. It starts at approximately 45, rises to a peak of around 85, and remains largely above 60 throughout the chart. It ends at approximately 85.
* Initial Accuracy: ~45
* Lowest Accuracy: ~60
* Highest Accuracy: ~85
* Final Accuracy: ~85
**X-Axis Labels (Chinese):**
The x-axis labels are in Chinese. A rough transliteration and potential meaning (based on common mathematical terms) is provided below. Note that this is an approximation.
1. 全面微积分 (Quánmiàn wēijífēn) - Comprehensive Calculus
2. 初等代数 (Chūděng dàishù) - Elementary Algebra
3. 高等代数 (Gāoděng dàishù) - Advanced Algebra
4. 三角学 (Sānjiǎoxué) - Trigonometry
5. 概率与统计 (Gàilǜ yǔ tǒngjì) - Probability and Statistics
6. 求和 (Qiúhé) - Summation
7. 反常积分 (Fǎncháng jīfēn) - Improper Integral
8. 反三角函数 (Fǎn sānjiǎo hánshù) - Inverse Trigonometric Functions
9. 极限 (Jìxiàn) - Limits
10. 导数 (Dǎoshù) - Derivatives
11. 积分 (Jīfēn) - Integrals
12. 级数 (Jíshù) - Series
13. 微分方程 (Wēifēn fāngchéng) - Differential Equations
14. 线性代数 (Xiànxìng dàishù) - Linear Algebra
15. 平面几何 (Píngmiàn jǐhè) - Plane Geometry
16. 立体几何 (Lìtǐ jǐhè) - Solid Geometry
17. 一元二次方程 (Yīyuán èrcì fāngchéng) - Quadratic Equation
18. 一元三次方程 (Yīyuán sān cì fāngchéng) - Cubic Equation
19. 概率 (Gàilǜ) - Probability
20. 期望 (Qīwàng) - Expectation
21. 方差 (Fāngchā) - Variance
22. 偏导数 (Piāndǎoshù) - Partial Derivatives
23. 向量 (Xiàngliàng) - Vectors
### Key Observations
* GPT-4 consistently outperforms both MetaMath-13B and LLaMA2-70B across all problem sets.
* MetaMath-13B exhibits the most volatile performance, with large swings in accuracy.
* LLaMA2-70B shows moderate performance, generally falling between MetaMath-13B and GPT-4.
* The problem sets appear to vary in difficulty, as evidenced by the fluctuations in accuracy for all models.
### Interpretation
The data strongly suggests that GPT-4 possesses superior mathematical reasoning capabilities compared to MetaMath-13B and LLaMA2-70B. The consistent high accuracy of GPT-4 indicates a robust understanding of mathematical concepts and problem-solving skills. The significant fluctuations in accuracy for MetaMath-13B suggest that its performance is highly sensitive to the specific type of mathematical problem presented. LLaMA2-70B provides a middle ground, demonstrating better performance than MetaMath-13B but still lagging behind GPT-4.
The Chinese labels on the x-axis indicate that the models were evaluated on a diverse range of mathematical topics, including calculus, algebra, trigonometry, probability, and geometry. The varying accuracy levels across these topics suggest that the models may have different strengths and weaknesses in specific areas of mathematics. The chart provides valuable insights into the mathematical reasoning abilities of these large language models and highlights the potential for further research and development in this field.