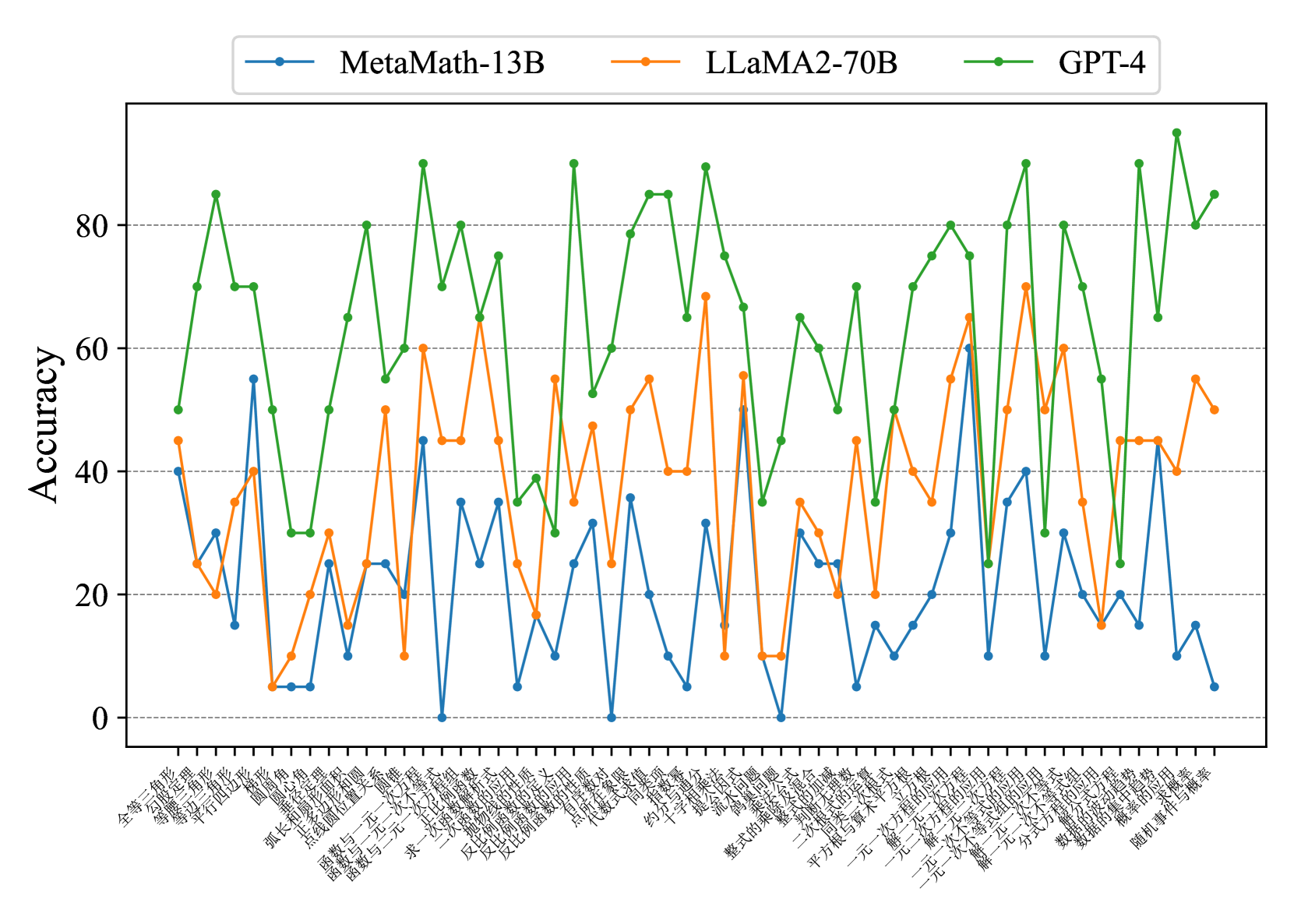
## Line Chart: Accuracy Comparison of AI Models on Math Problems
### Overview
The chart compares the accuracy of three AI models (MetaMath-13B, LLaMA2-70B, GPT-4) across 40+ math problems. Accuracy is measured on a 0-100% scale, with jagged lines indicating variability. GPT-4 consistently performs best, while MetaMath-13B shows the most erratic results.
### Components/Axes
- **Y-Axis**: Accuracy (0-100%, labeled "Accuracy")
- **X-Axis**: Math problems (Chinese text, 40+ categories)
- **Legend**:
- Blue: MetaMath-13B
- Orange: LLaMA2-70B
- Green: GPT-4
- **Legend Position**: Top-center
- **Data Series**: Three colored lines (blue, orange, green)
### Detailed Analysis
1. **GPT-4 (Green Line)**:
- **Trend**: Dominates with peaks near 90% and troughs above 60%.
- **Key Values**:
- Highest accuracy: ~95% (multiple problems)
- Lowest accuracy: ~65% (e.g., "反比例函数" problem)
- **Stability**: Minimal dips below 60%.
2. **LLaMA2-70B (Orange Line)**:
- **Trend**: Volatile, with sharp rises/falling. Matches GPT-4 in ~20% of problems.
- **Key Values**:
- Peaks: ~70-80% (e.g., "多项式方程")
- Troughs: ~10-30% (e.g., "函数与一元一次方程")
- **Inconsistency**: Wide swings (e.g., 90% drop from 80% to 10%).
3. **MetaMath-13B (Blue Line)**:
- **Trend**: Most erratic, with extreme lows (near 0%) and moderate highs (~60%).
- **Key Values**:
- Peaks: ~60% (e.g., "函数的单调性")
- Troughs: ~0-5% (e.g., "反比例函数", "函数的反演")
- **Unpredictability**: Frequent drops to near-zero accuracy.
### Key Observations
- **GPT-4 Superiority**: Consistently outperforms others across all problems.
- **LLaMA2-70B Variability**: Strong in specific areas (e.g., polynomial equations) but fails catastrophically on others.
- **MetaMath-13B Fragility**: Struggles with foundational concepts (e.g., inverse proportionality, function inversion).
### Interpretation
The data suggests GPT-4 has robust, generalizable math-solving capabilities, while LLaMA2-70B excels in niche areas but lacks consistency. MetaMath-13B’s performance indicates significant gaps in handling core mathematical principles. The jagged lines for all models imply sensitivity to problem phrasing or complexity. Notably, LLaMA2-70B’s ability to match GPT-4 in select problems hints at potential for targeted improvements, whereas MetaMath-13B requires foundational retraining. The Chinese problem labels (e.g., "反比例函数" = inverse proportionality functions) highlight domain-specific challenges, with MetaMath-13B failing most frequently on advanced topics.