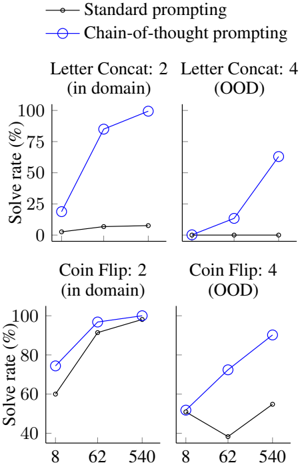
## Chart: Solve Rate vs. Context Length for Different Prompting Methods
### Overview
The image presents four line charts comparing the "Solve rate (%)" against context length (8, 62, 540) for two prompting methods: "Standard prompting" and "Chain-of-thought prompting." The charts are organized in a 2x2 grid, with rows representing different tasks ("Letter Concat" and "Coin Flip") and columns representing in-domain vs. out-of-domain (OOD) performance.
### Components/Axes
* **Y-axis (Solve rate (%)):** Ranges from 0 to 100, with tick marks at 25, 50, 75, and 100.
* **X-axis (Context Length):** Discrete values of 8, 62, and 540.
* **Legend (Top):**
* "Standard prompting" - represented by a solid gray line with filled gray circle markers.
* "Chain-of-thought prompting" - represented by a solid blue line with open blue circle markers.
* **Chart Titles:**
* Top-left: "Letter Concat: 2 (in domain)"
* Top-right: "Letter Concat: 4 (OOD)"
* Bottom-left: "Coin Flip: 2 (in domain)"
* Bottom-right: "Coin Flip: 4 (OOD)"
### Detailed Analysis
**1. Letter Concat: 2 (in domain)**
* **Standard prompting (gray):** The solve rate is relatively flat, hovering around 5-10%.
* At 8: ~5%
* At 62: ~7%
* At 540: ~8%
* **Chain-of-thought prompting (blue):** The solve rate increases significantly with context length.
* At 8: ~20%
* At 62: ~85%
* At 540: ~100%
**2. Letter Concat: 4 (OOD)**
* **Standard prompting (gray):** The solve rate remains very low, close to 0%.
* At 8: ~1%
* At 62: ~1%
* At 540: ~1%
* **Chain-of-thought prompting (blue):** The solve rate increases with context length, but not as dramatically as in the in-domain case.
* At 8: ~2%
* At 62: ~15%
* At 540: ~65%
**3. Coin Flip: 2 (in domain)**
* **Standard prompting (gray):** The solve rate increases with context length.
* At 8: ~60%
* At 62: ~90%
* At 540: ~100%
* **Chain-of-thought prompting (blue):** The solve rate also increases with context length, and is slightly higher than standard prompting at lower context lengths.
* At 8: ~75%
* At 62: ~95%
* At 540: ~100%
**4. Coin Flip: 4 (OOD)**
* **Standard prompting (gray):** The solve rate initially decreases and then increases with context length.
* At 8: ~50%
* At 62: ~35%
* At 540: ~55%
* **Chain-of-thought prompting (blue):** The solve rate increases with context length.
* At 8: ~50%
* At 62: ~75%
* At 540: ~90%
### Key Observations
* Chain-of-thought prompting generally outperforms standard prompting, especially for the "Letter Concat" task.
* The performance gap between the two prompting methods is more pronounced in the "Letter Concat" task than in the "Coin Flip" task.
* Increasing the context length generally improves the solve rate, but the effect varies depending on the task, prompting method, and domain (in-domain vs. OOD).
* For the "Coin Flip" task, the standard prompting method shows a slight dip in performance at a context length of 62 in the out-of-domain setting.
### Interpretation
The data suggests that chain-of-thought prompting is more effective than standard prompting, particularly when dealing with tasks that require more complex reasoning, as indicated by the "Letter Concat" task. The improvement is especially noticeable in the in-domain scenarios. The "Coin Flip" task, being potentially simpler, shows less of a performance difference between the two methods. The out-of-domain (OOD) performance highlights the robustness of chain-of-thought prompting, as it generally maintains a higher solve rate compared to standard prompting when faced with unfamiliar data. The context length plays a crucial role, as increasing it tends to improve the solve rate for both methods, although the extent of improvement varies. The dip in standard prompting performance for "Coin Flip: 4 (OOD)" at a context length of 62 could indicate some sensitivity to specific context lengths in out-of-domain scenarios.