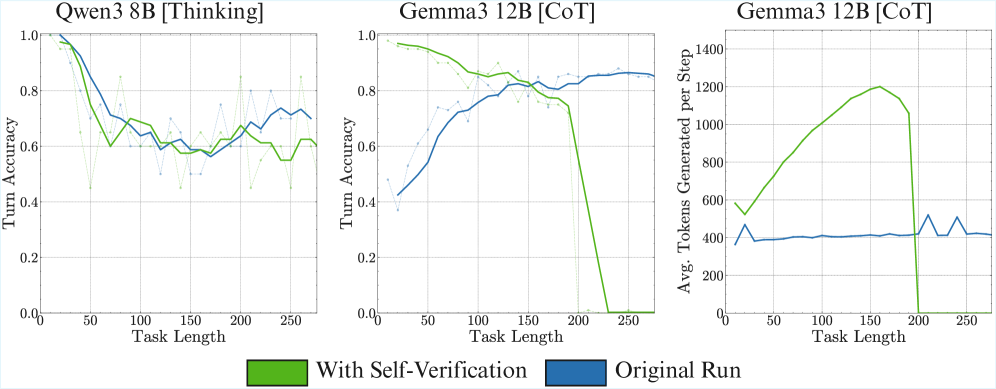
# Technical Data Extraction: Performance Analysis of Qwen3 and Gemma3 Models
This document provides a comprehensive extraction of data and trends from the provided image, which contains three line charts comparing model performance with and without "Self-Verification."
## 1. Global Metadata and Legend
* **Language:** English
* **Legend Location:** Bottom center of the image.
* **Legend Categories:**
* **Green Box/Line:** "With Self-Verification"
* **Blue Box/Line:** "Original Run"
* **Common X-Axis:** "Task Length" (Scale: 0 to ~275)
* **Common Visual Elements:** Solid lines represent smoothed averages; faint dotted lines with markers represent raw data points.
---
## 2. Component Analysis
### Chart 1: Qwen3 8B [Thinking]
* **Y-Axis:** Turn Accuracy (Scale: 0.0 to 1.0)
* **Trend Analysis:**
* **Original Run (Blue):** Starts at 1.0 accuracy for short tasks. Shows a steep decline until Task Length ~75, then stabilizes into a fluctuating plateau between 0.6 and 0.75.
* **With Self-Verification (Green):** Also starts at 1.0. Follows a similar downward trajectory but generally stays slightly below or equal to the Original Run after Task Length 100.
* **Key Data Observations:**
* Both methods converge toward a similar accuracy range (0.6 - 0.7) as task length increases.
* Self-verification does not appear to provide a significant accuracy boost for this specific model configuration across longer tasks.
### Chart 2: Gemma3 12B [CoT]
* **Y-Axis:** Turn Accuracy (Scale: 0.0 to 1.0)
* **Trend Analysis:**
* **Original Run (Blue):** Shows a strong upward trend. Starts low (~0.4 accuracy) for short tasks and steadily improves as Task Length increases, peaking and stabilizing around 0.85 after Task Length 200.
* **With Self-Verification (Green):** Starts very high (~0.95 accuracy) for short tasks. It maintains high accuracy until Task Length ~180, after which it suffers a catastrophic failure, dropping sharply to 0.0 accuracy by Task Length 230.
* **Key Data Observations:**
* **Crossover Point:** At Task Length ~160, the Original Run surpasses the Self-Verification run.
* **Failure State:** The green line indicates that for very long tasks (>200), the self-verification mechanism causes the model to fail completely (0% accuracy).
### Chart 3: Gemma3 12B [CoT] (Token Generation)
* **Y-Axis:** Avg. Tokens Generated per Step (Scale: 0 to 1400)
* **Trend Analysis:**
* **Original Run (Blue):** Remains extremely stable. Regardless of Task Length, the model generates a consistent average of approximately 400 tokens per step.
* **With Self-Verification (Green):** Shows a significant, linear increase in token generation as Task Length increases. It starts at ~550 tokens and peaks at ~1200 tokens at Task Length 160. Following this peak, it drops slightly and then crashes to 0 tokens at Task Length 200.
* **Key Data Observations:**
* The "Self-Verification" process is computationally more expensive, requiring significantly more tokens as tasks get longer.
* The crash to 0 tokens in Chart 3 correlates exactly with the 0.0 accuracy seen in Chart 2, suggesting a context window limit or a processing error that halts generation entirely for long tasks when self-verification is active.
---
## 3. Summary of Findings
| Metric | Qwen3 8B [Thinking] | Gemma3 12B [CoT] |
| :--- | :--- | :--- |
| **Accuracy Trend** | Decreases then plateaus. | Original improves; Self-Verification crashes. |
| **Self-Verification Impact** | Minimal/Neutral. | High benefit for short tasks; Catastrophic for long tasks. |
| **Token Cost** | N/A (Not charted) | Self-Verification increases token usage by up to 3x before failing. |
**Conclusion:** While "Self-Verification" improves accuracy for Gemma3 12B on shorter tasks, it introduces a scaling overhead in token generation that leads to a total system failure once a certain task length threshold (approx. 200) is reached. Qwen3 8B appears more robust to task length but does not benefit significantly from the self-verification logic shown.