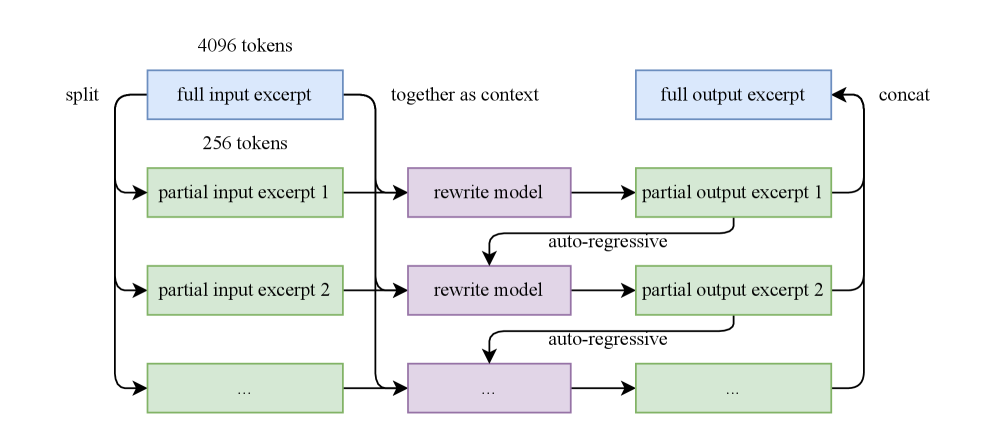
## Flowchart: Text Processing Pipeline with Auto-Regressive Rewrite Model
### Overview
The diagram illustrates a multi-stage text processing workflow involving input splitting, iterative rewriting via an auto-regressive model, and output concatenation. The process handles 4096 tokens of input text, splitting it into smaller partial excerpts (256 tokens each) for sequential processing through a rewrite model. The final output combines partial results into a full output excerpt.
### Components/Axes
- **Input Stage**:
- **Full Input Excerpt**: 4096 tokens (blue box)
- **Split Operation**: Divides input into 256-token partial excerpts
- **Partial Input Excerpts**: Labeled 1, 2, ... (green boxes)
- **Processing Stage**:
- **Rewrite Model**: Central purple box with "auto-regressive" annotation
- **Partial Output Excerpts**: Generated sequentially (green boxes)
- **Output Stage**:
- **Concat Operation**: Combines partial outputs
- **Full Output Excerpt**: Final result (blue box)
### Detailed Analysis
1. **Input Splitting**:
- 4096 tokens → 16 partial excerpts (4096 ÷ 256 = 16)
- Each partial input excerpt (256 tokens) is processed independently
2. **Rewrite Model**:
- Auto-regressive processing indicated by bidirectional arrows
- Suggests iterative refinement of partial outputs
3. **Output Concatenation**:
- Partial outputs (1, 2, ...) combined sequentially
- Final output matches original input size (4096 tokens)
### Key Observations
- **Token Consistency**: Input/output token counts match (4096), suggesting lossless processing
- **Modular Design**: Auto-regressive model processes discrete chunks rather than full text
- **Sequential Dependency**: Partial outputs are ordered (1 → 2 → ...) before concatenation
- **Color Coding**: Blue for input/output, green for partial stages, purple for model
### Interpretation
This architecture demonstrates a divide-and-conquer approach to text processing:
1. **Efficiency**: Splitting large inputs into manageable chunks (256 tokens) enables parallelizable processing
2. **Quality Control**: Auto-regressive refinement suggests iterative improvement of partial outputs
3. **Reconstructability**: Final output maintains original token count through precise concatenation
4. **Potential Applications**: Could represent text summarization, translation, or content generation pipelines where context preservation is critical
The auto-regressive annotation implies the model generates outputs token-by-token with contextual awareness, likely improving coherence in partial outputs before final combination.