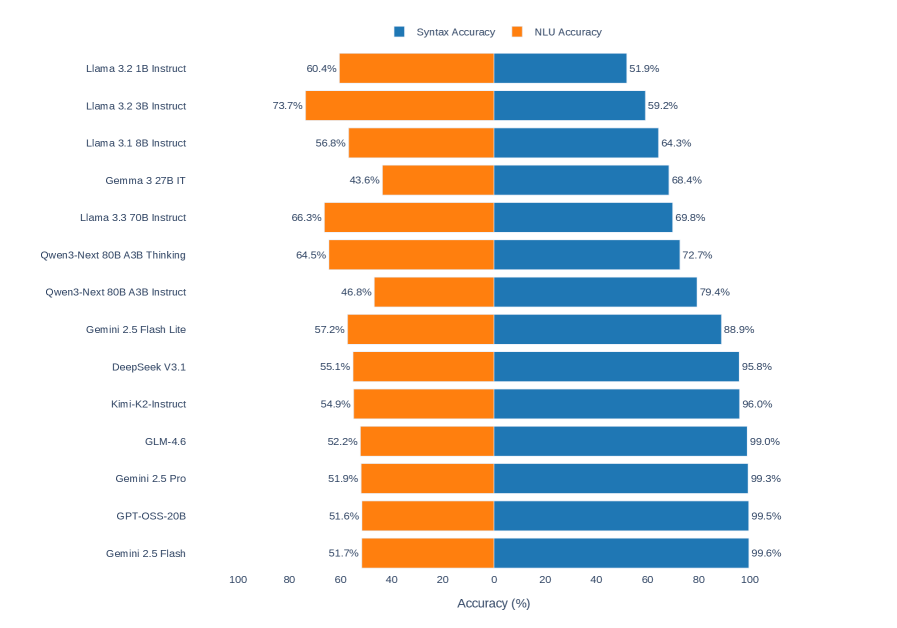
## Bar Chart: AI Model Performance Comparison (Syntax vs NLU Accuracy)
### Overview
The chart compares the performance of various AI language models across two metrics: **Syntax Accuracy** (blue bars) and **NLU Accuracy** (orange bars). Models are listed vertically on the y-axis, with accuracy percentages on the x-axis (0–100%). The legend at the top distinguishes the two metrics by color.
### Components/Axes
- **y-axis**: AI models (listed top-to-bottom):
- Llama 3.2 1B Instruct
- Llama 3.2 3B Instruct
- Llama 3.1 8B Instruct
- Gemma 3 27B IT
- Llama 3.3 70B Instruct
- Qwen3-Next 80B A3B Thinking
- Qwen3-Next 80B A3B Instruct
- Gemini 2.5 Flash Lite
- DeepSeek V3.1
- Kimi-K2-Instruct
- GLM-4.6
- Gemini 2.5 Pro
- GPT-OSS-20B
- Gemini 2.5 Flash
- **x-axis**: Accuracy (%) (0–100, labeled "Accuracy (%)").
- **Legend**:
- Blue = Syntax Accuracy
- Orange = NLU Accuracy
### Detailed Analysis
1. **Llama 3.2 1B Instruct**: NLU 60.4% (orange), Syntax 51.9% (blue).
2. **Llama 3.2 3B Instruct**: NLU 73.7% (orange), Syntax 59.2% (blue).
3. **Llama 3.1 8B Instruct**: NLU 56.8% (orange), Syntax 64.3% (blue).
4. **Gemma 3 27B IT**: NLU 43.6% (orange), Syntax 68.4% (blue).
5. **Llama 3.3 70B Instruct**: NLU 66.3% (orange), Syntax 69.8% (blue).
6. **Qwen3-Next 80B A3B Thinking**: NLU 64.5% (orange), Syntax 72.7% (blue).
7. **Qwen3-Next 80B A3B Instruct**: NLU 46.8% (orange), Syntax 79.4% (blue).
8. **Gemini 2.5 Flash Lite**: NLU 57.2% (orange), Syntax 88.9% (blue).
9. **DeepSeek V3.1**: NLU 55.1% (orange), Syntax 95.8% (blue).
10. **Kimi-K2-Instruct**: NLU 54.9% (orange), Syntax 96.0% (blue).
11. **GLM-4.6**: NLU 52.2% (orange), Syntax 99.0% (blue).
12. **Gemini 2.5 Pro**: NLU 51.9% (orange), Syntax 99.3% (blue).
13. **GPT-OSS-20B**: NLU 51.6% (orange), Syntax 99.5% (blue).
14. **Gemini 2.5 Flash**: NLU 51.7% (orange), Syntax 99.6% (blue).
### Key Observations
- **Syntax Dominance**: Most models (e.g., Gemini 2.5 Flash, GPT-OSS-20B) achieve near-perfect Syntax Accuracy (99%+), suggesting robust grammatical understanding.
- **NLU Variability**: NLU Accuracy ranges widely (43.6%–73.7%), with Llama 3.2 3B Instruct leading (73.7%) and Gemma 3 27B IT lagging (43.6%).
- **Trade-offs**: Models like Qwen3-Next 80B A3B Instruct (NLU 46.8%, Syntax 79.4%) and Gemini 2.5 Flash (NLU 51.7%, Syntax 99.6%) highlight a common trend: high Syntax often correlates with lower NLU.
- **Outliers**:
- **Gemma 3 27B IT**: Lowest NLU (43.6%) but mid-tier Syntax (68.4%).
- **Llama 3.2 3B Instruct**: Highest NLU (73.7%) but lowest Syntax among top NLU performers (59.2%).
### Interpretation
The data suggests a **trade-off between syntactic precision and natural language understanding** across models. Larger models (e.g., Gemini 2.5 Flash, GPT-OSS-20B) prioritize syntactic accuracy, possibly due to extensive training on grammatically diverse datasets. Conversely, models like Llama 3.2 3B Instruct excel in NLU, indicating specialized training for contextual comprehension. The Qwen3-Next series shows balanced performance but lags behind in both metrics compared to Gemini and GPT-OSS variants. This divergence may reflect differences in training objectives, data quality, or architectural design. Notably, the Gemini 2.5 Flash series achieves near-human Syntax Accuracy (99.3–99.6%) but struggles with NLU (51.7–57.2%), highlighting a potential limitation in real-world applicability despite grammatical mastery.