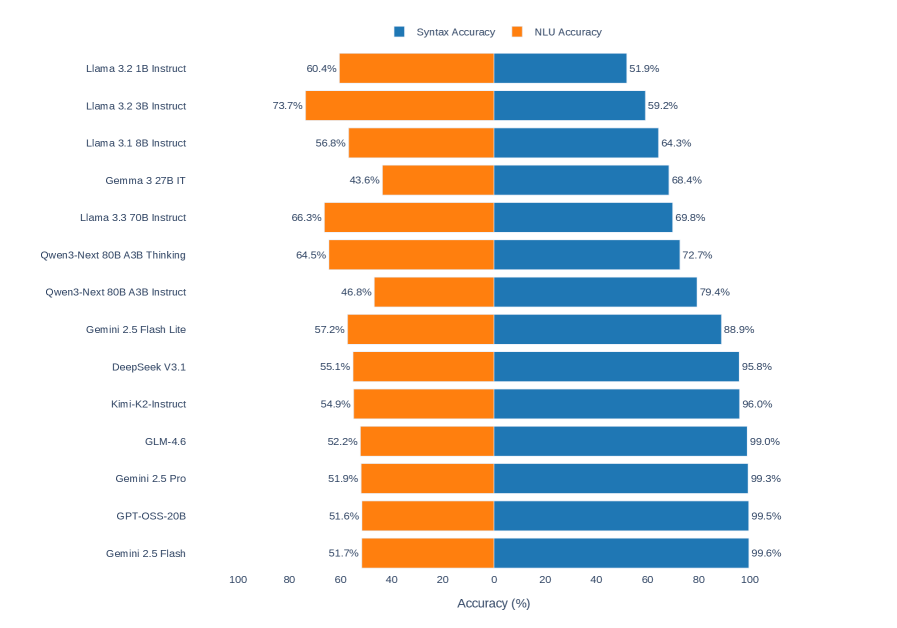
## Horizontal Bar Chart: Syntax Accuracy vs. NLU Accuracy of Various Language Models
### Overview
The image is a horizontal bar chart comparing the Syntax Accuracy and NLU (Natural Language Understanding) Accuracy of various language models. The chart displays two horizontal bars for each model, one representing Syntax Accuracy (blue) and the other representing NLU Accuracy (orange). The models are listed on the vertical axis, and the accuracy percentages are displayed on the horizontal axis.
### Components/Axes
* **Title:** There is no explicit title on the chart.
* **X-Axis:** "Accuracy (%)" ranging from 0 to 100, with tick marks at intervals of 20.
* **Y-Axis:** List of language models:
* Llama 3.2 1B Instruct
* Llama 3.2 3B Instruct
* Llama 3.1 8B Instruct
* Gemma 3 27B IT
* Llama 3.3 70B Instruct
* Qwen3-Next 80B A3B Thinking
* Qwen3-Next 80B A3B Instruct
* Gemini 2.5 Flash Lite
* DeepSeek V3.1
* Kimi-K2-Instruct
* GLM-4.6
* Gemini 2.5 Pro
* GPT-OSS-20B
* Gemini 2.5 Flash
* **Legend:** Located at the top of the chart.
* Blue: Syntax Accuracy
* Orange: NLU Accuracy
### Detailed Analysis
Here's a breakdown of the accuracy scores for each model:
* **Llama 3.2 1B Instruct:**
* Syntax Accuracy (Blue): 51.9%
* NLU Accuracy (Orange): 60.4%
* **Llama 3.2 3B Instruct:**
* Syntax Accuracy (Blue): 59.2%
* NLU Accuracy (Orange): 73.7%
* **Llama 3.1 8B Instruct:**
* Syntax Accuracy (Blue): 64.3%
* NLU Accuracy (Orange): 56.8%
* **Gemma 3 27B IT:**
* Syntax Accuracy (Blue): 68.4%
* NLU Accuracy (Orange): 43.6%
* **Llama 3.3 70B Instruct:**
* Syntax Accuracy (Blue): 69.8%
* NLU Accuracy (Orange): 66.3%
* **Qwen3-Next 80B A3B Thinking:**
* Syntax Accuracy (Blue): 72.7%
* NLU Accuracy (Orange): 64.5%
* **Qwen3-Next 80B A3B Instruct:**
* Syntax Accuracy (Blue): 79.4%
* NLU Accuracy (Orange): 46.8%
* **Gemini 2.5 Flash Lite:**
* Syntax Accuracy (Blue): 88.9%
* NLU Accuracy (Orange): 57.2%
* **DeepSeek V3.1:**
* Syntax Accuracy (Blue): 95.8%
* NLU Accuracy (Orange): 55.1%
* **Kimi-K2-Instruct:**
* Syntax Accuracy (Blue): 96.0%
* NLU Accuracy (Orange): 54.9%
* **GLM-4.6:**
* Syntax Accuracy (Blue): 99.0%
* NLU Accuracy (Orange): 52.2%
* **Gemini 2.5 Pro:**
* Syntax Accuracy (Blue): 99.3%
* NLU Accuracy (Orange): 51.9%
* **GPT-OSS-20B:**
* Syntax Accuracy (Blue): 99.5%
* NLU Accuracy (Orange): 51.6%
* **Gemini 2.5 Flash:**
* Syntax Accuracy (Blue): 99.6%
* NLU Accuracy (Orange): 51.7%
### Key Observations
* Syntax Accuracy (blue bars) generally increases as you move down the list of models.
* NLU Accuracy (orange bars) varies more and does not show a clear trend.
* The Gemini models (Gemini 2.5 Flash Lite, Gemini 2.5 Pro, Gemini 2.5 Flash) and DeepSeek V3.1, Kimi-K2-Instruct, GLM-4.6, GPT-OSS-20B have significantly higher Syntax Accuracy compared to the other models.
* For most models, Syntax Accuracy is higher than NLU Accuracy.
### Interpretation
The chart suggests that while some language models excel in syntax understanding, their natural language understanding capabilities may lag behind. The Gemini models, DeepSeek V3.1, Kimi-K2-Instruct, GLM-4.6, and GPT-OSS-20B demonstrate a strong ability to process syntax, but their NLU performance is relatively lower compared to their syntax accuracy. This could indicate a trade-off in model design or training, where emphasis is placed on syntax over semantic understanding. The varying NLU accuracy across different models highlights the complexity of natural language understanding and the challenges in achieving high performance across both syntax and semantics.