## Line Graphs: Lichess Puzzle Accuracy vs. Training Step for Qwen2.5-7B and Llama3.1-8B
### Overview
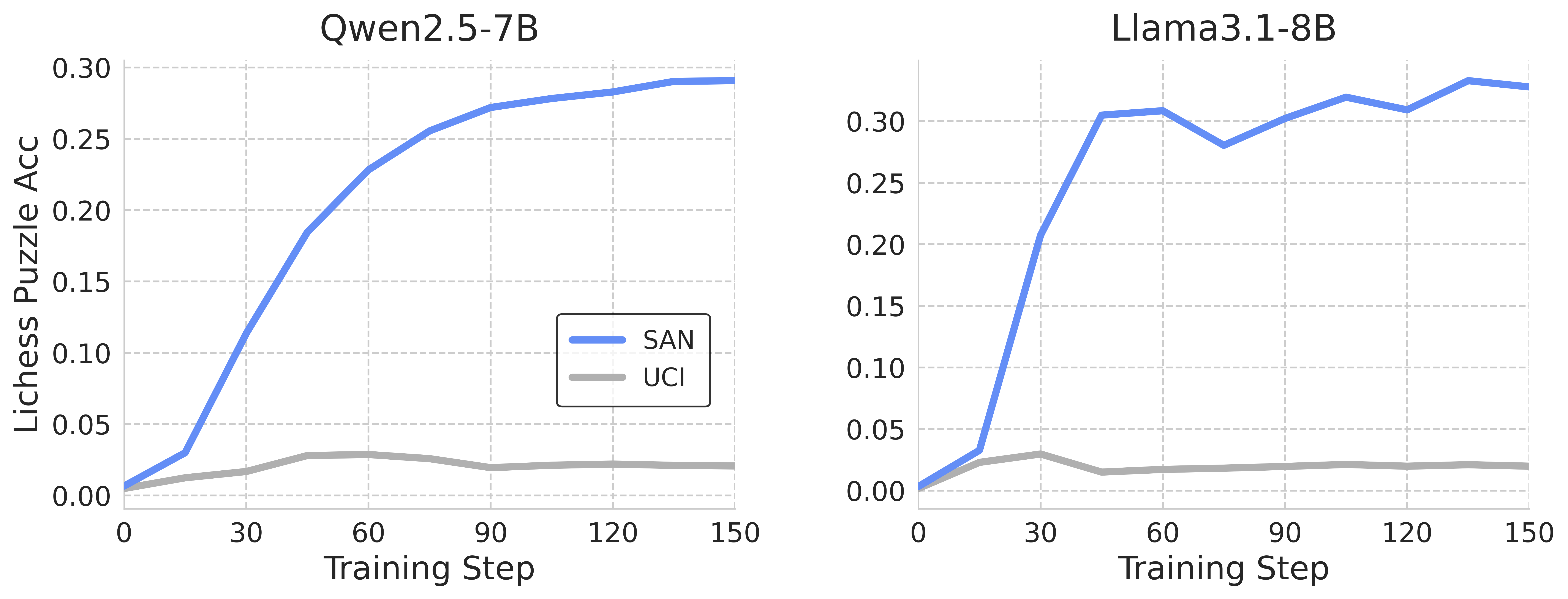
The image contains two line graphs comparing the Lichess Puzzle Accuracy of two language models, Qwen2.5-7B and Llama3.1-8B, over training steps. Each graph plots the accuracy of two methods, SAN and UCI, against the training step.
### Components/Axes
**Left Graph (Qwen2.5-7B):**
* **Title:** Qwen2.5-7B
* **Y-axis:** Lichess Puzzle Acc, ranging from 0.00 to 0.30 in increments of 0.05.
* **X-axis:** Training Step, ranging from 0 to 150 in increments of 30.
* **Legend:** Located in the center-right of the left graph.
* SAN: Blue line
* UCI: Gray line
**Right Graph (Llama3.1-8B):**
* **Title:** Llama3.1-8B
* **Y-axis:** Lichess Puzzle Acc, ranging from 0.00 to 0.30 in increments of 0.05.
* **X-axis:** Training Step, ranging from 0 to 150 in increments of 30.
* **Legend:** (Same as left graph)
* SAN: Blue line
* UCI: Gray line
### Detailed Analysis
**Left Graph (Qwen2.5-7B):**
* **SAN (Blue):** The line starts at approximately 0.00 at training step 0, increases rapidly to approximately 0.18 at step 30, continues to increase to approximately 0.24 at step 60, reaches approximately 0.27 at step 90, and plateaus around 0.29 from step 120 to 150.
* **UCI (Gray):** The line starts at approximately 0.00 at training step 0, increases slightly to approximately 0.02 at step 30, and then remains relatively flat around 0.02-0.03 from step 60 to 150.
**Right Graph (Llama3.1-8B):**
* **SAN (Blue):** The line starts at approximately 0.00 at training step 0, increases rapidly to approximately 0.30 at step 30, dips slightly to approximately 0.28 at step 60, increases to approximately 0.32 at step 90, dips to approximately 0.31 at step 120, and plateaus around 0.29 from step 150.
* **UCI (Gray):** The line starts at approximately 0.00 at training step 0, increases slightly to approximately 0.03 at step 30, and then remains relatively flat around 0.02 from step 60 to 150.
### Key Observations
* In both graphs, the SAN method (blue line) shows a significantly higher Lichess Puzzle Accuracy compared to the UCI method (gray line).
* For Qwen2.5-7B, the SAN accuracy increases steadily and plateaus, while for Llama3.1-8B, the SAN accuracy increases rapidly and then fluctuates slightly around a high value.
* The UCI accuracy remains consistently low for both models.
### Interpretation
The data suggests that the SAN method is significantly more effective than the UCI method for improving Lichess Puzzle Accuracy in both Qwen2.5-7B and Llama3.1-8B language models. The Llama3.1-8B model reaches a higher accuracy faster than the Qwen2.5-7B model, but its accuracy fluctuates more. The UCI method appears to have minimal impact on the Lichess Puzzle Accuracy for both models. The rapid increase in accuracy for the SAN method in both models indicates a strong learning curve in the initial training steps.