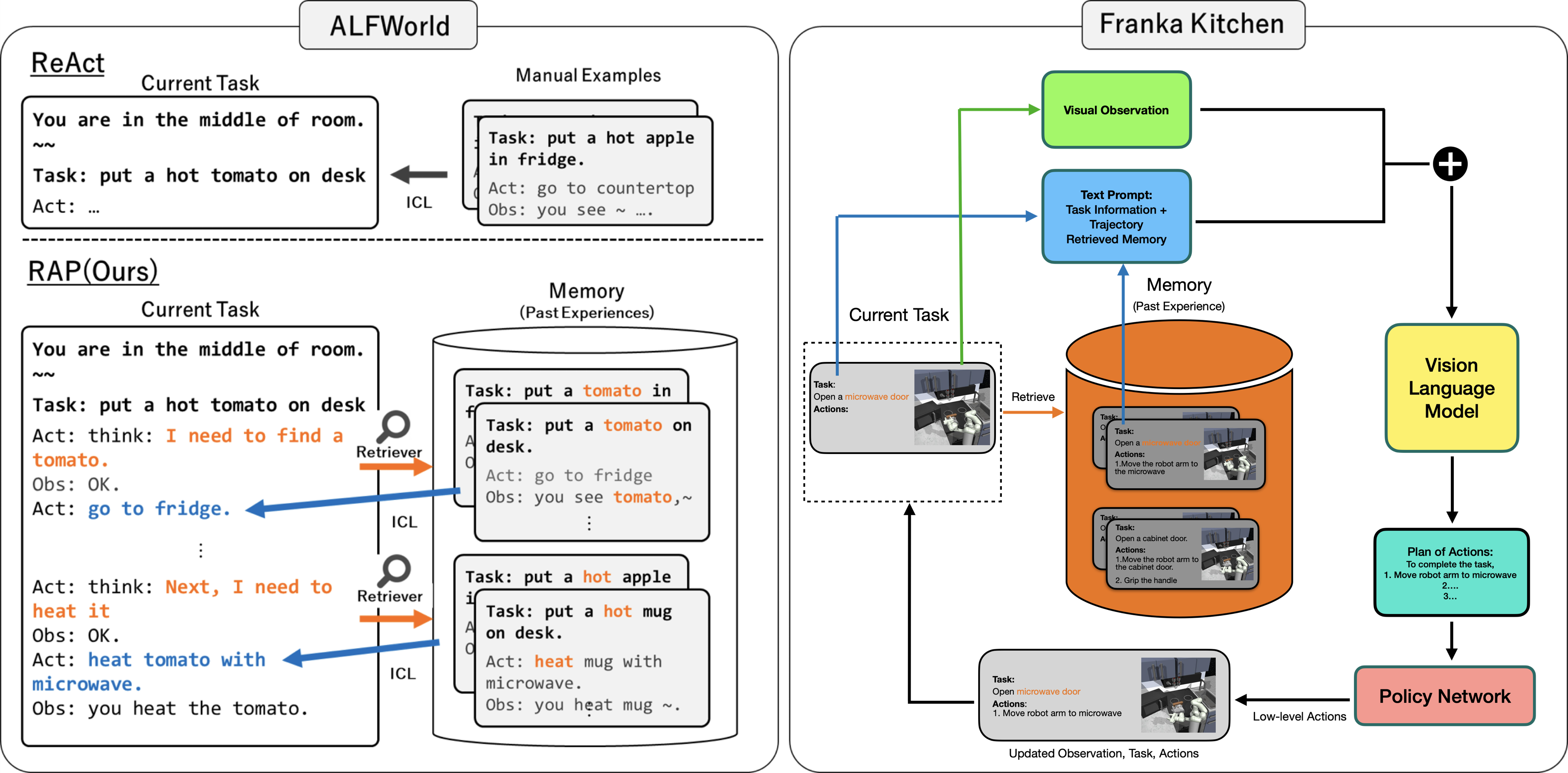
## Diagram: Task Execution Systems Comparison (ReAct vs RAP)
### Overview
The diagram compares two task execution systems: **ReAct** (left) and **RAP (Ours)** (right), focusing on their components, memory integration, and action planning workflows. Both systems operate in simulated environments (ALFWorld and Franka Kitchen) and involve task execution, memory retrieval, and action planning.
---
### Components/Axes
#### **ReAct (Left Side)**
- **Current Task**: Text box with task description ("put a hot tomato on desk").
- **Manual Examples**: Arrows pointing to ICL (In-Context Learning) with example tasks (e.g., "put a hot apple in fridge").
- **Act**: Placeholder for action generation (empty in this diagram).
#### **RAP (Right Side)**
- **Current Task**: Text box with task description ("put a hot tomato on desk").
- **Memory (Past Experiences)**: Orange cylinder containing:
- Task: "put a tomato on desk" (with action: "go to fridge").
- Task: "put a hot apple in fridge" (with action: "heat mug with microwave").
- Task: "put a hot mug on desk" (with action: "heat mug with microwave").
- **Visual Observation**: Green box with robot arm and microwave (Franka Kitchen environment).
- **Text Prompt**: Blue box combining task info, trajectory, and retrieved memory.
- **Vision Language Model**: Yellow box processing inputs.
- **Plan of Actions**: Green box with step-by-step instructions (e.g., "Move robot arm to microwave").
- **Policy Network**: Pink box generating low-level actions (e.g., "Move robot arm to microwave").
---
### Detailed Analysis
#### **ReAct Workflow**
1. **Task**: "put a hot tomato on desk".
2. **Manual Examples**: Provides ICL examples (e.g., "put a hot apple in fridge").
3. **Act**: No explicit action shown; relies on ICL for task completion.
#### **RAP Workflow**
1. **Current Task**: "put a hot tomato on desk".
2. **Memory Retrieval**: Accesses past experiences (e.g., "put a tomato on desk" → "go to fridge").
3. **Visual Observation**: Robot arm and microwave in Franka Kitchen.
4. **Text Prompt**: Combines task, memory, and observation.
5. **Vision Language Model**: Processes inputs to generate a plan.
6. **Plan of Actions**: Step-by-step instructions (e.g., "Move robot arm to microwave").
7. **Policy Network**: Executes low-level actions (e.g., "Move robot arm to microwave").
---
### Key Observations
- **Memory Integration**: RAP explicitly uses a memory cylinder to store past experiences, while ReAct relies on manual examples.
- **Action Planning**: RAP includes a structured "Plan of Actions" step, whereas ReAct skips this.
- **Environment-Specific Tasks**: Franka Kitchen tasks involve physical interactions (e.g., robot arm movements), while ALFWorld tasks are text-based.
- **Color Coding**:
- Green: Visual Observation (Franka Kitchen).
- Blue: Text Prompt (task + memory).
- Orange: Memory cylinder (past experiences).
---
### Interpretation
- **ReAct** emphasizes **In-Context Learning (ICL)** with manual examples, suitable for text-based tasks in ALFWorld.
- **RAP** integrates **vision-language models** and **memory retrieval** for complex, environment-specific tasks (e.g., Franka Kitchen). Its workflow is more systematic, with explicit steps for action planning.
- **Memory Role**: RAP’s memory cylinder acts as a knowledge base, enabling the system to reuse past experiences (e.g., heating a mug) to solve new tasks.
- **Policy Network**: The final step in RAP translates high-level plans into executable actions, highlighting its focus on robotics.
This diagram illustrates how RAP enhances task execution by combining visual inputs, memory, and structured planning, whereas ReAct relies on simpler ICL mechanisms.