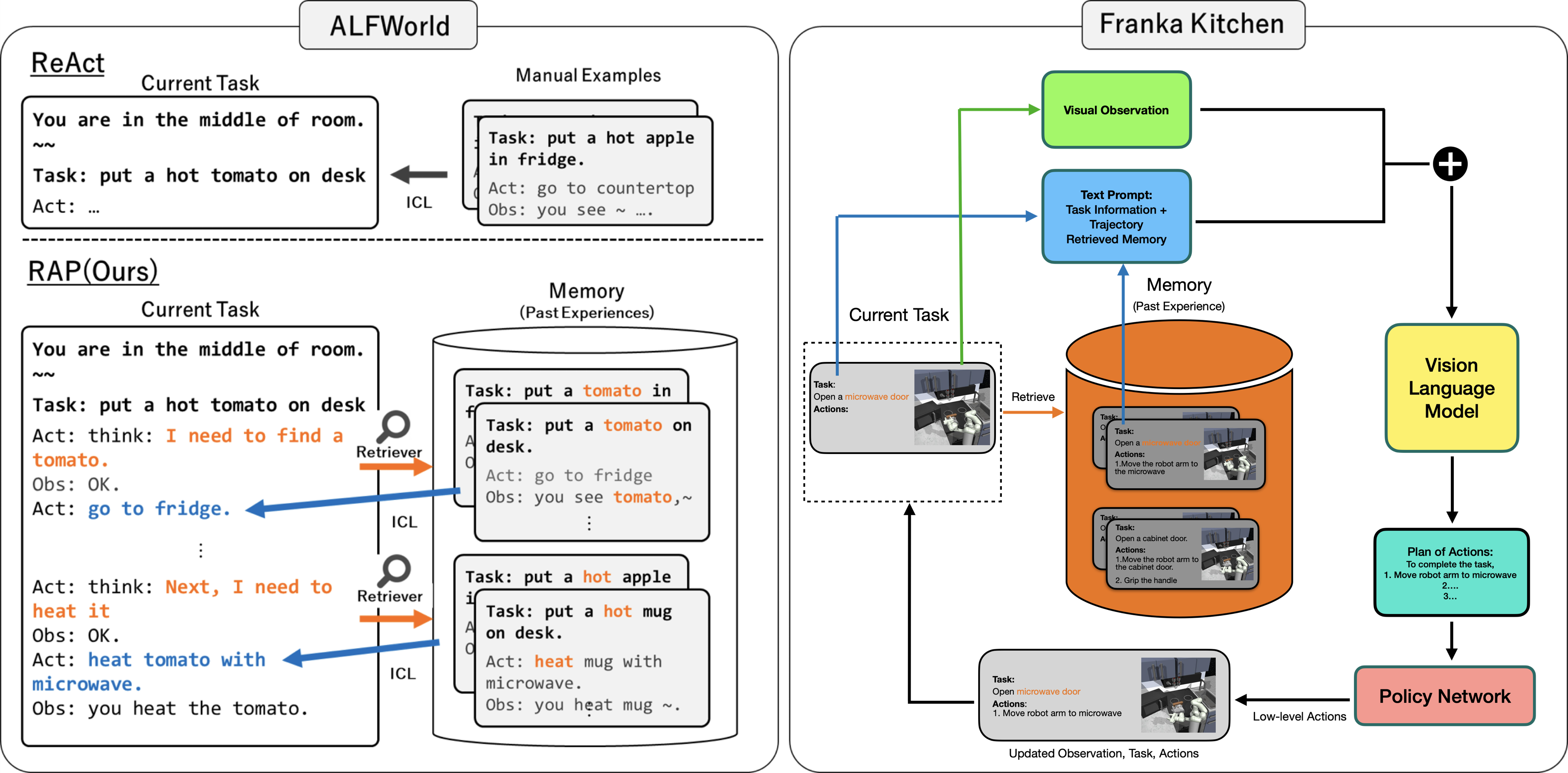
## System Diagram: ReAct vs. RAP for Task Execution in ALFWorld and Franka Kitchen
### Overview
The image presents a system diagram comparing two approaches, ReAct and RAP(Ours), for task execution in two environments: ALFWorld and Franka Kitchen. The diagram illustrates the flow of information and actions within each system, highlighting the role of memory, visual observation, language models, and policy networks.
### Components/Axes
**ALFWorld (Left Side):**
* **ReAct:**
* **Current Task:** Displays the current task description: "You are in the middle of room. Task: put a hot tomato on desk. Act: ..."
* **ICL (In-Context Learning):** An arrow points from "Manual Examples" to "ReAct" indicating the use of manual examples for in-context learning.
* **RAP(Ours):**
* **Current Task:** Displays the current task description: "You are in the middle of room. Task: put a hot tomato on desk. Act: think: I need to find a tomato. Obs: OK. Act: go to fridge. ... Act: think: Next, I need to heat it. Obs: OK. Act: heat tomato with microwave. Obs: you heat the tomato."
* **Retriever:** A magnifying glass icon labeled "Retriever" points from the "Current Task" to the "Memory (Past Experiences)" cylinder.
* **Memory (Past Experiences):** A cylinder containing examples of past tasks and observations, such as "Task: put a tomato in fridge. Task: put a tomato on desk. Act: go to fridge. Obs: you see tomato, ~ ..." and "Task: put a hot apple on desk. Task: put a hot mug on desk. Act: heat mug with microwave. Obs: you heat mug ~."
* **ICL (In-Context Learning):** An arrow points from "Memory (Past Experiences)" to "RAP(Ours)" indicating the use of memory for in-context learning.
* **Manual Examples:** Contains examples of manual tasks, such as "Task: put a hot apple in fridge. Act: go to countertop. Obs: you see ~ ..."
**Franka Kitchen (Right Side):**
* **Visual Observation:** A green rectangle labeled "Visual Observation" at the top.
* **Text Prompt:** A blue rectangle labeled "Text Prompt: Task Information + Trajectory Retrieved Memory".
* **Memory (Past Experience):** An orange cylinder labeled "Memory (Past Experience)".
* Contains examples of past tasks and actions, such as "Task: Open a microwave door. Actions: 1. Move the robot arm to the microwave" and "Task: Open a cabinet door. Actions: 1. Move the robot arm to the cabinet door. 2. Grip the handle".
* **Current Task:** A dotted rectangle labeled "Current Task" containing the current task and actions, such as "Task: Open a microwave door. Actions:". It also contains a small image of a robot arm in a kitchen environment.
* **Vision Language Model:** A yellow rectangle labeled "Vision Language Model".
* **Plan of Actions:** A teal rectangle labeled "Plan of Actions: To complete the task, 1. Move robot arm to microwave 2... 3...".
* **Policy Network:** A pink rectangle labeled "Policy Network".
* **Arrows:** Arrows indicate the flow of information between components:
* Green arrow from "Visual Observation" to the "+" symbol.
* Blue arrow from "Text Prompt" to the "+" symbol.
* Black arrow from the "+" symbol to "Vision Language Model".
* Black arrow from "Vision Language Model" to "Plan of Actions".
* Black arrow from "Plan of Actions" to "Policy Network".
* Black arrow from "Policy Network" to "Current Task" labeled "Low-level Actions".
* Green arrow from "Current Task" to "Visual Observation".
* Blue arrow from "Current Task" to "Text Prompt".
* Orange arrow from "Memory (Past Experience)" to "Text Prompt".
* Orange arrow from "Memory (Past Experience)" to "Current Task" labeled "Retrieve".
* Black arrow from "Current Task" to "Updated Observation, Task, Actions".
### Detailed Analysis or Content Details
* **ReAct in ALFWorld:** The system starts with a current task and uses in-context learning (ICL) from manual examples to determine the next action.
* **RAP(Ours) in ALFWorld:** The system starts with a current task and uses a retriever to access relevant past experiences from memory. It then uses ICL to determine the next action.
* **Franka Kitchen System:** The system integrates visual observation and text prompts, combines them, and feeds them into a vision language model. The model generates a plan of actions, which is then executed by a policy network. The policy network's low-level actions update the current task and observation.
### Key Observations
* **ALFWorld:** ReAct relies on manual examples, while RAP(Ours) uses a retriever to access past experiences.
* **Franka Kitchen:** The system integrates visual and textual information to generate a plan of actions.
* **Memory:** Both systems utilize memory to inform decision-making.
* **Vision Language Model:** The Franka Kitchen system uses a vision language model to bridge the gap between visual and textual information.
### Interpretation
The diagram illustrates two different approaches to task execution. ReAct relies on manual examples for in-context learning, while RAP(Ours) uses a retriever to access past experiences. The Franka Kitchen system integrates visual and textual information to generate a plan of actions, which is then executed by a policy network.
The diagram suggests that RAP(Ours) may be more adaptable to new situations, as it can leverage past experiences to inform decision-making. The Franka Kitchen system may be more robust to noisy or incomplete information, as it integrates visual and textual information.
The use of a vision language model in the Franka Kitchen system highlights the importance of bridging the gap between visual and textual information in robotics.