TECHNICAL ASSET FINGERPRINT
9ebbb3292559f42c1408227a
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
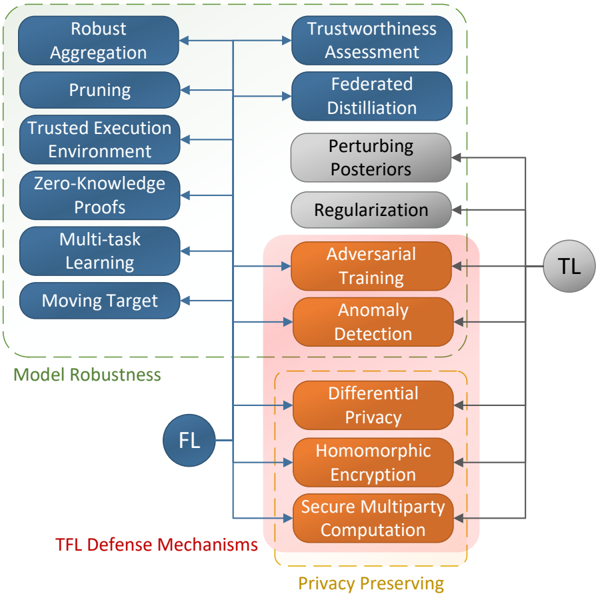
## Diagram: TFL Defense Mechanisms Taxonomy
### Overview
The image is a technical diagram illustrating a taxonomy of defense mechanisms for Trustworthy Federated Learning (TFL). It categorizes various techniques into two primary groups—"Model Robustness" and "Privacy Preserving"—and shows their relationship to Federated Learning (FL) and Transfer Learning (TL) paradigms. The diagram uses color-coded boxes, directional arrows, and grouping containers to depict relationships and applicability.
### Components/Elements
**1. Primary Learning Paradigms (Circles):**
* **FL** (Blue circle, center-left): Represents Federated Learning.
* **TL** (Gray circle, center-right): Represents Transfer Learning.
**2. Defense Mechanism Categories (Dashed Boxes & Labels):**
* **Model Robustness** (Green dashed box, left side): Encloses a column of six blue rectangular boxes.
* **Privacy Preserving** (Yellow dashed box, bottom-right): Encloses a group of three orange rectangular boxes.
* **TFL Defense Mechanisms** (Red text, bottom-left): The overarching title for the entire diagram.
**3. Individual Defense Mechanisms (Rectangular Boxes):**
* **Left Column (Blue boxes, within "Model Robustness"):**
* Robust Aggregation
* Pruning
* Trusted Execution Environment
* Zero-Knowledge Proofs
* Multi-task Learning
* Moving Target
* **Right Column (Mixed colors):**
* Trustworthiness Assessment (Blue)
* Federated Distillation (Blue)
* Perturbing Posteriors (Gray)
* Regularization (Gray)
* Adversarial Training (Orange)
* Anomaly Detection (Orange)
* Differential Privacy (Orange, within "Privacy Preserving")
* Homomorphic Encryption (Orange, within "Privacy Preserving")
* Secure Multiparty Computation (Orange, within "Privacy Preserving")
**4. Grouping & Shading:**
* A light pink shaded background encompasses the lower-right cluster of mechanisms, from "Adversarial Training" down to "Secure Multiparty Computation," indicating a related subgroup.
**5. Flow & Relationships (Arrows):**
* A central vertical line connects the **FL** circle to arrows pointing to every mechanism in the left "Model Robustness" column and to "Adversarial Training" and "Anomaly Detection" in the right column.
* A line from the **TL** circle points to the cluster of orange boxes: "Adversarial Training," "Anomaly Detection," "Differential Privacy," "Homomorphic Encryption," and "Secure Multiparty Computation."
* Horizontal arrows connect mechanisms between the left and right columns at corresponding vertical levels (e.g., "Robust Aggregation" ↔ "Trustworthiness Assessment").
### Detailed Analysis
The diagram systematically maps defense strategies:
* **Model Robustness Techniques (Left):** All six are directly linked to the **FL** paradigm. They focus on improving the resilience and reliability of the federated model itself (e.g., through aggregation methods, pruning, secure hardware, cryptographic proofs).
* **Right Column Techniques:** These have varied associations.
* "Trustworthiness Assessment" and "Federated Distillation" are linked only to **FL**.
* "Perturbing Posteriors" and "Regularization" (gray boxes) have no direct incoming arrow from FL or TL in this diagram, suggesting they might be general techniques or their primary association is not depicted.
* The orange-boxed cluster ("Adversarial Training" through "Secure Multiparty Computation") is linked to both **FL** (via the central line) and **TL** (via a direct arrow from the TL circle). This indicates these methods are considered relevant for both federated and transfer learning contexts.
* **Privacy Preserving Subset:** The three mechanisms at the bottom right ("Differential Privacy," "Homomorphic Encryption," "Secure Multiparty Computation") are explicitly grouped under the "Privacy Preserving" label, highlighting their specific purpose of protecting data confidentiality.
### Key Observations
1. **Dual Applicability:** The most notable pattern is that the entire "Privacy Preserving" group and two other mechanisms ("Adversarial Training," "Anomaly Detection") are shown as applicable to both Federated Learning (FL) and Transfer Learning (TL).
2. **Categorical Overlap:** The "Privacy Preserving" category is a subset of the larger group of mechanisms that are relevant to TL, but not all TL-relevant mechanisms are privacy-preserving (e.g., Adversarial Training is for robustness).
3. **Visual Hierarchy:** The diagram uses color (blue for general/robustness, orange for privacy/TL-shared, gray for unassociated), containment (dashed boxes), and spatial grouping to create a clear visual taxonomy.
4. **Unconnected Elements:** The gray boxes ("Perturbing Posteriors," "Regularization") are visually isolated from the primary FL and TL flows, which may imply they are auxiliary, foundational, or belong to a different category not fully elaborated in this view.
### Interpretation
This diagram serves as a conceptual map for designing or analyzing trustworthy machine learning systems, particularly in distributed (federated) or knowledge-transfer scenarios. It argues that a comprehensive defense strategy requires a combination of techniques targeting different threat models:
* **Model Robustness** defenses (left column) are presented as core to **Federated Learning**, aiming to ensure the aggregated model is accurate and resilient to poisoned or low-quality updates from participants.
* **Privacy Preserving** defenses (bottom-right) are crucial when sensitive data cannot be shared, and are shown to be equally important in **Transfer Learning** contexts where data privacy or intellectual property protection is a concern.
* The linkage of **Adversarial Training** and **Anomaly Detection** to both FL and TL suggests these are viewed as fundamental robustness techniques applicable across different learning paradigms that involve model training on distributed or external data.
The absence of connections for "Perturbing Posteriors" and "Regularization" is a significant visual cue. It may indicate they are considered general regularization techniques not specific to the FL/TL threat model, or that their role in this specific taxonomy of "TFL Defense Mechanisms" is secondary or implicit. The diagram effectively communicates that building trustworthy AI systems is not about a single solution but about selecting and combining appropriate mechanisms from this taxonomy based on the specific learning framework (FL, TL) and primary concerns (robustness vs. privacy).
DECODING INTELLIGENCE...