\n
## Multi-Series Line Chart: Accuracy vs. Max Allowed Turns
### Overview
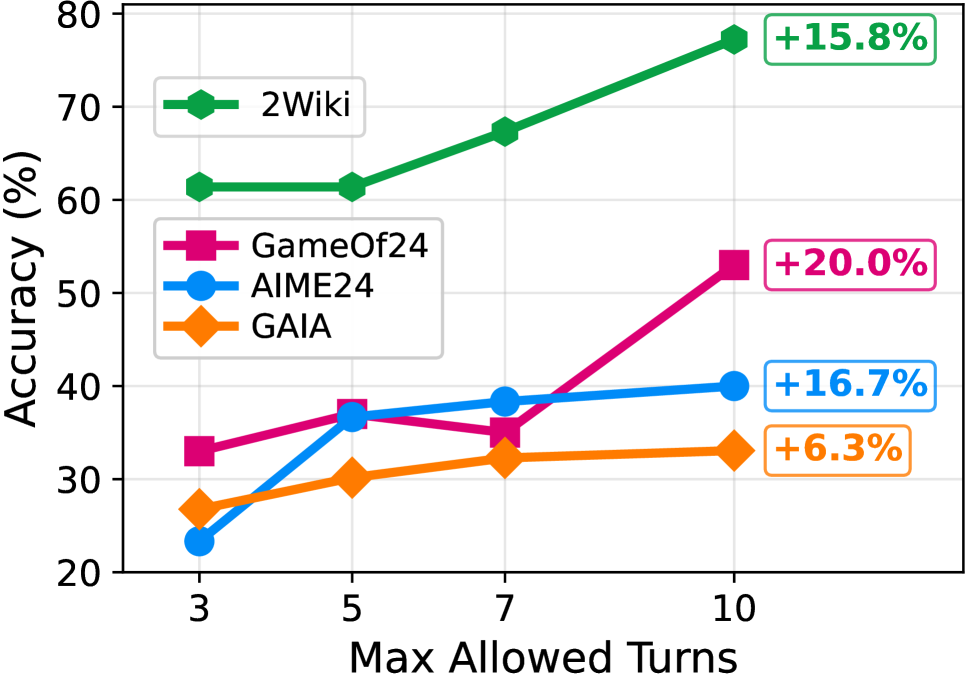
This is a line chart comparing the performance (accuracy) of four different models or datasets—2Wiki, GameOf24, AIME24, and GAIA—as a function of the maximum number of conversational turns allowed. The chart demonstrates how accuracy changes for each series as the turn limit increases from 3 to 10.
### Components/Axes
* **Chart Type:** Multi-series line chart with markers.
* **X-Axis (Horizontal):**
* **Label:** "Max Allowed Turns"
* **Scale:** Discrete values at 3, 5, 7, and 10.
* **Y-Axis (Vertical):**
* **Label:** "Accuracy (%)"
* **Scale:** Linear scale from 20 to 80, with major gridlines at intervals of 10.
* **Legend:** Positioned in the top-left quadrant of the chart area.
* **2Wiki:** Green line with diamond markers.
* **GameOf24:** Pink/magenta line with square markers.
* **AIME24:** Blue line with circle markers.
* **GAIA:** Orange line with diamond markers.
* **Data Point Annotations:** Percentage values in colored boxes are placed to the right of the final data point (at 10 turns) for each series, indicating the total improvement from the starting point (3 turns).
### Detailed Analysis
**Data Series and Trends:**
1. **2Wiki (Green, Diamonds):**
* **Trend:** Consistently upward-sloping line, showing steady improvement.
* **Data Points (Approximate):**
* At 3 Turns: ~61%
* At 5 Turns: ~61% (plateau)
* At 7 Turns: ~67%
* At 10 Turns: ~77%
* **Annotated Improvement:** +15.8%
2. **GameOf24 (Pink, Squares):**
* **Trend:** Overall upward trend with a slight dip at 7 turns before a sharp final increase.
* **Data Points (Approximate):**
* At 3 Turns: ~33%
* At 5 Turns: ~37%
* At 7 Turns: ~35% (dip)
* At 10 Turns: ~53%
* **Annotated Improvement:** +20.0%
3. **AIME24 (Blue, Circles):**
* **Trend:** Increases sharply initially, then the rate of improvement slows, nearly plateauing after 7 turns.
* **Data Points (Approximate):**
* At 3 Turns: ~23%
* At 5 Turns: ~37%
* At 7 Turns: ~38%
* At 10 Turns: ~40%
* **Annotated Improvement:** +16.7%
4. **GAIA (Orange, Diamonds):**
* **Trend:** Gentle, steady upward slope with the smallest overall gain.
* **Data Points (Approximate):**
* At 3 Turns: ~27%
* At 5 Turns: ~30%
* At 7 Turns: ~32%
* At 10 Turns: ~33%
* **Annotated Improvement:** +6.3%
### Key Observations
* **Universal Improvement:** All four series show higher accuracy at 10 turns compared to 3 turns.
* **Performance Hierarchy:** 2Wiki maintains the highest accuracy at every measured point. GAIA consistently has the lowest accuracy after the initial point.
* **Greatest Gainer:** GameOf24 shows the largest absolute improvement (+20.0%), despite a mid-chart dip.
* **Diminishing Returns:** AIME24's curve flattens significantly after 5 turns, suggesting limited benefit from turns beyond that point for this specific task.
* **Anomaly:** GameOf24 is the only series to exhibit a decrease in accuracy at an intermediate point (7 turns) before recovering strongly.
### Interpretation
The data suggests a strong positive correlation between the allowed number of conversational turns and task accuracy for these benchmarks. This implies that granting a model more opportunities to "think" or interact generally leads to better outcomes.
However, the **nature of the task** critically mediates this benefit:
* **2Wiki** (likely a knowledge-intensive QA task) benefits consistently, suggesting complex information synthesis requires more iterative processing.
* **GameOf24** (a mathematical puzzle) shows high volatility and the greatest potential gain, indicating it may be particularly sensitive to the number of reasoning steps allowed, with a possible "confusion point" at 7 turns.
* **AIME24** (another math benchmark) shows rapid early gains that quickly saturate, hinting that its problems may be solvable within a shorter reasoning horizon.
* **GAIA** (a complex real-world reasoning benchmark) shows only modest gains, suggesting its challenges may be less about the number of turns and more about other capabilities like tool use or grounding, which are not unlocked simply by adding more conversational steps.
In summary, while more turns are generally beneficial, the chart reveals that the **task's inherent structure** determines both the baseline performance and the marginal utility of additional computational "thinking time." The annotated percentages highlight the potential upside of scaling this particular resource.