\n
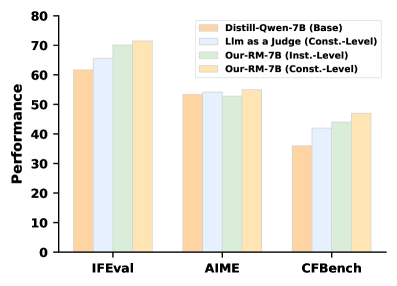
## Bar Chart: Performance Comparison of Language Models
### Overview
This bar chart compares the performance of four different language models – Distill-Qwen-7B (Base), Lim as a judge (Const.-Level), Our-RM-7B (Inst.-Level), and Our-RM-7B (Const.-Level) – across three evaluation benchmarks: IFEval, AIME, and CFBench. Performance is measured on the y-axis, while the x-axis represents the benchmarks.
### Components/Axes
* **X-axis:** Benchmarks - IFEval, AIME, CFBench
* **Y-axis:** Performance (Scale from 0 to 80)
* **Legend:**
* Distill-Qwen-7B (Base) - Light Orange
* Lim as a judge (Const.-Level) - Light Blue
* Our-RM-7B (Inst.-Level) - Light Green
* Our-RM-7B (Const.-Level) - Pale Yellow
* **Chart Type:** Bar Chart
* **Legend Position:** Top-right corner
### Detailed Analysis
The chart consists of three groups of four bars, one group for each benchmark.
**IFEval:**
* Distill-Qwen-7B (Base): Approximately 62.
* Lim as a judge (Const.-Level): Approximately 64.
* Our-RM-7B (Inst.-Level): Approximately 68.
* Our-RM-7B (Const.-Level): Approximately 70.
**AIME:**
* Distill-Qwen-7B (Base): Approximately 55.
* Lim as a judge (Const.-Level): Approximately 56.
* Our-RM-7B (Inst.-Level): Approximately 56.
* Our-RM-7B (Const.-Level): Approximately 55.
**CFBench:**
* Distill-Qwen-7B (Base): Approximately 38.
* Lim as a judge (Const.-Level): Approximately 43.
* Our-RM-7B (Inst.-Level): Approximately 44.
* Our-RM-7B (Const.-Level): Approximately 47.
### Key Observations
* **Our-RM-7B (Const.-Level)** consistently performs the best across all three benchmarks, although the difference is most pronounced in IFEval.
* **Distill-Qwen-7B (Base)** generally exhibits the lowest performance across all benchmarks.
* **Lim as a judge (Const.-Level)** and **Our-RM-7B (Inst.-Level)** show similar performance in AIME.
* The performance differences between the models are more significant in IFEval and CFBench than in AIME.
### Interpretation
The data suggests that the "Our-RM-7B" model, particularly when trained with a "Const.-Level" approach, outperforms the "Distill-Qwen-7B" baseline and the "Lim as a judge" model across the evaluated benchmarks. This indicates that the training methodology and model architecture of "Our-RM-7B" are more effective for these specific tasks. The relatively consistent performance of "Lim as a judge" and "Our-RM-7B (Inst.-Level)" in AIME suggests that the "Inst.-Level" training approach may be particularly suited for that benchmark. The lower performance of all models on CFBench could indicate that this benchmark presents a greater challenge or requires different capabilities than IFEval and AIME. The consistent ranking of the models across benchmarks suggests a general trend in their relative performance, rather than benchmark-specific anomalies.