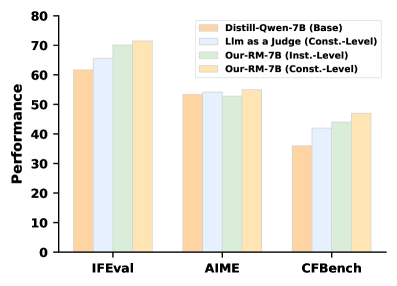
## Bar Chart: Model Performance Comparison Across Benchmarks
### Overview
The chart compares the performance of four models across three benchmarks (IFEval, AIME, CFBench). Performance is measured on a scale from 0 to 80. The models include:
- **Distill-Qwen-7B (Base)** (orange)
- **Llm as a Judge (Const.-Level)** (light blue)
- **Our-RM-7B (Inst.-Level)** (green)
- **Our-RM-7B (Const.-Level)** (yellow)
### Components/Axes
- **X-axis**: Benchmarks (IFEval, AIME, CFBench)
- **Y-axis**: Performance (0–80)
- **Legend**: Located in the top-right corner, mapping colors to models.
- **Bar Groups**: Each benchmark has four adjacent bars representing the four models.
### Detailed Analysis
- **IFEval**:
- Distill-Qwen-7B (Base): ~60
- Llm as a Judge (Const.-Level): ~65
- Our-RM-7B (Inst.-Level): ~70
- Our-RM-7B (Const.-Level): ~72
- **AIME**:
- Distill-Qwen-7B (Base): ~53
- Llm as a Judge (Const.-Level): ~54
- Our-RM-7B (Inst.-Level): ~52
- Our-RM-7B (Const.-Level): ~55
- **CFBench**:
- Distill-Qwen-7B (Base): ~36
- Llm as a Judge (Const.-Level): ~42
- Our-RM-7B (Inst.-Level): ~44
- Our-RM-7B (Const.-Level): ~47
### Key Observations
1. **Our-RM-7B (Const.-Level)** consistently outperforms other models in IFEval and AIME.
2. **Our-RM-7B (Inst.-Level)** shows slightly higher performance than its Const.-Level counterpart in CFBench.
3. **Distill-Qwen-7B (Base)** has the lowest performance across all benchmarks, particularly in CFBench.
4. **Llm as a Judge (Const.-Level)** performs comparably to the base model in IFEval but slightly better in AIME and CFBench.
### Interpretation
The data suggests that **Our-RM-7B (Const.-Level)** is the most effective model for IFEval and AIME, likely due to its constrained-level optimization. However, **Our-RM-7B (Inst.-Level)** outperforms the Const.-Level in CFBench, indicating that instruction-level tuning may be more beneficial for this specific task. The base model (Distill-Qwen-7B) underperforms across all benchmarks, highlighting the importance of specialized training (e.g., constrained or instruction-level) for improved performance. The divergence in CFBench results between Inst.-Level and Const.-Level models suggests task-specific trade-offs in model design.