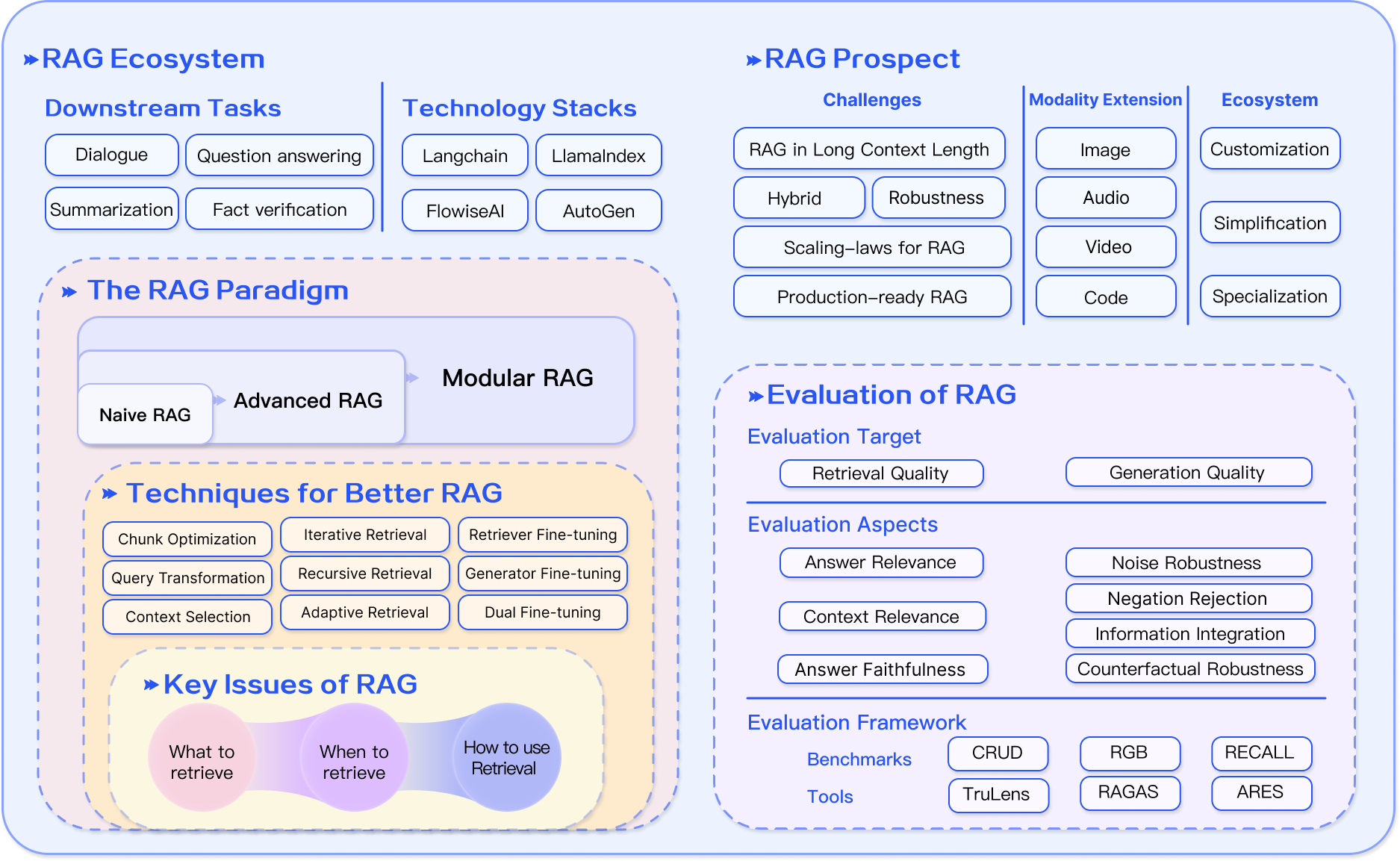
# RAG Ecosystem and Paradigm Analysis
## RAG Ecosystem
### Downstream Tasks
- Dialogue
- Question answering
- Summarization
- Fact verification
### Technology Stacks
- Langchain
- LlamaIndex
- FlowiseAI
- AutoGen
## RAG Prospect
### Challenges
- RAG in Long Context Length
- Hybrid
- Robustness
- Scaling-laws for RAG
- Production-ready RAG
### Modality Extension
- Image
- Audio
- Video
- Code
### Ecosystem
- Customization
- Simplification
- Specialization
## The RAG Paradigm
### Progression
1. Naive RAG
2. Advanced RAG
3. Modular RAG
## Techniques for Better RAG
### Retrieval Techniques
- Chunk Optimization
- Iterative Retrieval
- Retriever Fine-tuning
- Query Transformation
- Recursive Retrieval
- Generator Fine-tuning
- Context Selection
- Adaptive Retrieval
- Dual Fine-tuning
## Key Issues of RAG
- What to retrieve
- When to retrieve
- How to use Retrieval
## Evaluation of RAG
### Evaluation Target
- Retrieval Quality
- Generation Quality
### Evaluation Aspects
- Answer Relevance
- Context Relevance
- Answer Faithfulness
- Noise Robustness
- Negation Rejection
- Information Integration
- Counterfactual Robustness
### Evaluation Framework
#### Benchmarks
- CRUD
- RGB
- RECALL
#### Tools
- TruLens
- RAGAS
- ARES