## Violin Plot Grid: F1 Score Distribution Across Sentence Training and Bias Conditions
### Overview
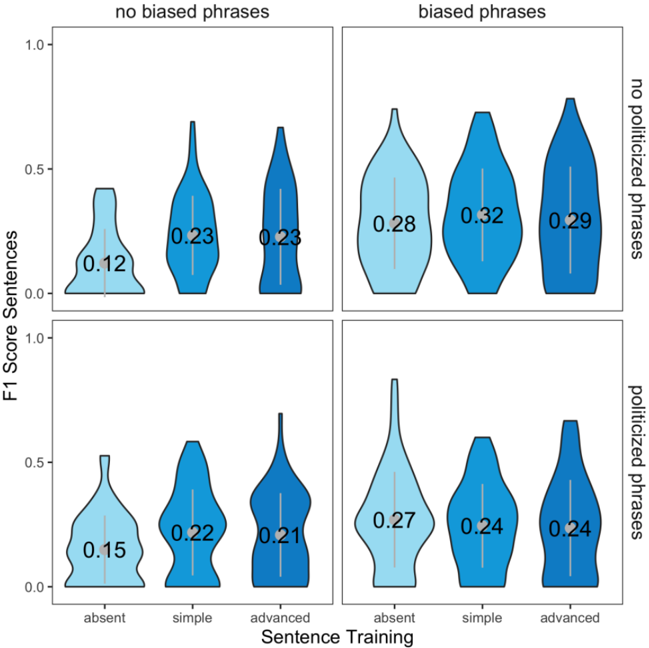
The image is a 2x2 grid of violin plots comparing F1 scores under different conditions: "no biased phrases" vs. "biased phrases" (top row) and "no politicized phrases" vs. "politicized phrases" (bottom row). Each quadrant contains three subplots labeled "absent," "simple," and "advanced" under the x-axis "Sentence Training." The y-axis represents F1 scores (0.0–1.0).
---
### Components/Axes
- **X-axis (Sentence Training)**:
- Categories: "absent," "simple," "advanced" (left to right).
- **Y-axis (F1 Score)**:
- Scale: 0.0 to 1.0.
- **Top Row Labels**:
- "no biased phrases" (left) and "biased phrases" (right).
- **Bottom Row Labels**:
- "no politicized phrases" (left) and "politicized phrases" (right).
- **Violin Plot Colors**:
- Shades of blue (lighter to darker) for each quadrant.
- No explicit legend is visible, but colors likely differentiate conditions (e.g., "no biased" vs. "biased").
---
### Detailed Analysis
#### Top Row: Biased Phrases
1. **No Biased Phrases (Left)**:
- **Absent**: F1 = 0.12 (mean).
- **Simple**: F1 = 0.23 (mean).
- **Advanced**: F1 = 0.23 (mean).
- **Trend**: F1 scores increase from "absent" to "simple" and "advanced," with no significant difference between "simple" and "advanced."
2. **Biased Phrases (Right)**:
- **Absent**: F1 = 0.28 (mean).
- **Simple**: F1 = 0.32 (mean).
- **Advanced**: F1 = 0.29 (mean).
- **Trend**: F1 scores peak at "simple" (0.32), then slightly decrease at "advanced" (0.29).
#### Bottom Row: Politicized Phrases
1. **No Politicized Phrases (Left)**:
- **Absent**: F1 = 0.15 (mean).
- **Simple**: F1 = 0.22 (mean).
- **Advanced**: F1 = 0.21 (mean).
- **Trend**: F1 scores rise from "absent" to "simple," then slightly drop at "advanced."
2. **Politicized Phrases (Right)**:
- **Absent**: F1 = 0.27 (mean).
- **Simple**: F1 = 0.24 (mean).
- **Advanced**: F1 = 0.24 (mean).
- **Trend**: F1 scores are highest at "absent" (0.27), then stabilize at "simple" and "advanced" (0.24).
---
### Key Observations
1. **Bias Impact**:
- "Biased phrases" consistently yield higher F1 scores than "no biased phrases" (e.g., 0.32 vs. 0.23 for "simple").
- "Politicized phrases" also outperform "no politicized phrases" (e.g., 0.27 vs. 0.15 for "absent").
2. **Training Level Effects**:
- "Simple" and "advanced" training levels show similar F1 scores in most cases, suggesting diminishing returns for increased complexity.
- "Absent" conditions often have the lowest scores, except in the "politicized phrases" group, where "absent" outperforms "simple" and "advanced."
3. **Anomalies**:
- In the "biased phrases" group, "simple" training achieves the highest F1 (0.32), while "advanced" drops slightly (0.29).
- In the "politicized phrases" group, "absent" has the highest F1 (0.27), contradicting the trend seen in other groups.
---
### Interpretation
The data suggests that the presence of **biased or politicized phrases** improves model performance (higher F1 scores) compared to their absence. This could indicate that models trained on biased or politicized data learn patterns that enhance their ability to handle such content. However, the "simple" and "advanced" training levels show minimal differences, implying that increasing training complexity does not significantly improve performance in these scenarios.
Notably, the "politicized phrases" group exhibits an inverse relationship: "absent" conditions outperform "simple" and "advanced" training. This might reflect that the absence of politicized phrases allows the model to focus on more generalizable features, whereas training on politicized data introduces noise or overfitting.
The results highlight the complex interplay between data bias, training complexity, and model performance, emphasizing the need for careful consideration of bias in training data.