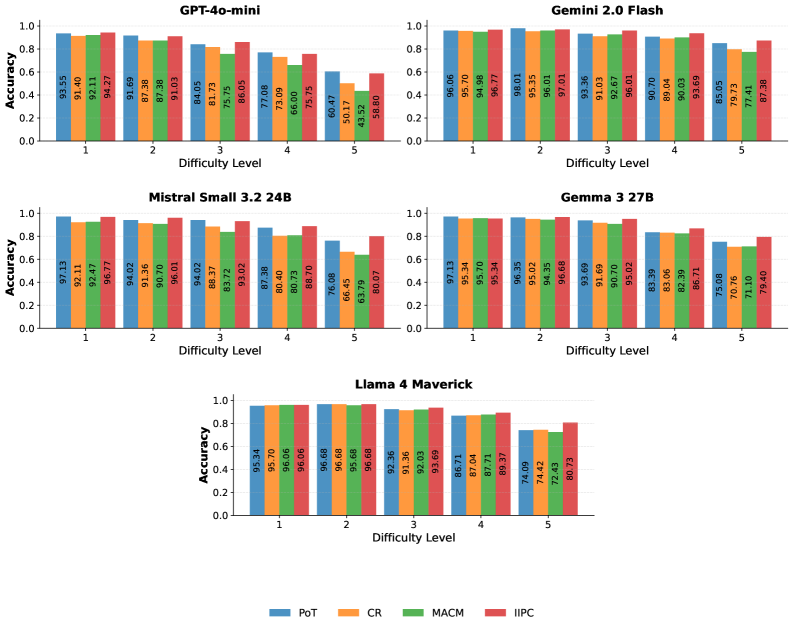
## Stacked Bar Charts: Model Accuracy vs. Difficulty Level
### Overview
The image presents a series of stacked bar charts, each representing the accuracy of a different Large Language Model (LLM) across five levels of difficulty. The charts visually compare the performance of GPT-4o-mini, Gemini 2.0 Flash, Mistral Small 3.2 24B, Gemma 3 27B, and Llama 4 Maverick. Accuracy is represented on the y-axis (ranging from 0.0 to 1.0), and difficulty level is on the x-axis (ranging from 1 to 5). Each bar is segmented into four components, representing different evaluation metrics: PoT, CR, MACM, and IIPC.
### Components/Axes
* **Y-axis:** Accuracy (Scale: 0.0 to 1.0)
* **X-axis:** Difficulty Level (Levels: 1, 2, 3, 4, 5)
* **Legend:**
* PoT (Blue)
* CR (Orange)
* MACM (Red)
* IIPC (Green)
* **Charts:** Five separate stacked bar charts, one for each model:
* GPT-4o-mini
* Gemini 2.0 Flash
* Mistral Small 3.2 24B
* Gemma 3 27B
* Llama 4 Maverick
### Detailed Analysis or Content Details
**GPT-4o-mini:**
* Difficulty 1: Accuracy = 93.55 (PoT), 92.11 (CR), 94.69 (MACM), 88.05 (IIPC) - Total: ~97%
* Difficulty 2: Accuracy = 91.29 (PoT), 87.38 (CR), 91.03 (MACM), 73.09 (IIPC) - Total: ~86%
* Difficulty 3: Accuracy = 84.05 (PoT), 81.73 (CR), 86.15 (MACM), 66.47 (IIPC) - Total: ~79%
* Difficulty 4: Accuracy = 75.75 (PoT), 60.47 (CR), 43.52 (MACM), 50.17 (IIPC) - Total: ~58%
* Difficulty 5: Accuracy = 56.80 (PoT), 50.17 (CR), 43.52 (MACM), 43.52 (IIPC) - Total: ~48%
**Gemini 2.0 Flash:**
* Difficulty 1: Accuracy = 96.06 (PoT), 95.78 (CR), 96.36 (MACM), 93.69 (IIPC) - Total: ~98%
* Difficulty 2: Accuracy = 95.49 (PoT), 94.98 (CR), 95.36 (MACM), 92.61 (IIPC) - Total: ~97%
* Difficulty 3: Accuracy = 93.36 (PoT), 92.10 (CR), 93.66 (MACM), 90.70 (IIPC) - Total: ~95%
* Difficulty 4: Accuracy = 90.02 (PoT), 89.61 (CR), 89.36 (MACM), 85.05 (IIPC) - Total: ~88%
* Difficulty 5: Accuracy = 79.63 (PoT), 75.73 (CR), 79.34 (MACM), 79.34 (IIPC) - Total: ~79%
**Mistral Small 3.2 24B:**
* Difficulty 1: Accuracy = 97.13 (PoT), 97.82 (CR), 94.67 (MACM), 91.32 (IIPC) - Total: ~98%
* Difficulty 2: Accuracy = 96.07 (PoT), 96.02 (CR), 94.03 (MACM), 88.47 (IIPC) - Total: ~96%
* Difficulty 3: Accuracy = 94.72 (PoT), 94.03 (CR), 89.87 (MACM), 80.79 (IIPC) - Total: ~92%
* Difficulty 4: Accuracy = 92.47 (PoT), 91.38 (CR), 86.83 (MACM), 66.45 (IIPC) - Total: ~84%
* Difficulty 5: Accuracy = 80.07 (PoT), 68.87 (CR), 66.45 (MACM), 61.79 (IIPC) - Total: ~69%
**Gemma 3 27B:**
* Difficulty 1: Accuracy = 97.11 (PoT), 95.34 (CR), 95.02 (MACM), 94.39 (IIPC) - Total: ~98%
* Difficulty 2: Accuracy = 95.70 (PoT), 95.34 (CR), 94.39 (MACM), 91.13 (IIPC) - Total: ~96%
* Difficulty 3: Accuracy = 95.02 (PoT), 94.39 (CR), 95.68 (MACM), 83.39 (IIPC) - Total: ~92%
* Difficulty 4: Accuracy = 83.39 (PoT), 83.39 (CR), 83.39 (MACM), 75.06 (IIPC) - Total: ~81%
* Difficulty 5: Accuracy = 79.40 (PoT), 71.41 (CR), 71.41 (MACM), 71.40 (IIPC) - Total: ~74%
**Llama 4 Maverick:**
* Difficulty 1: Accuracy = 95.34 (PoT), 96.06 (CR), 96.68 (MACM), 92.36 (IIPC) - Total: ~98%
* Difficulty 2: Accuracy = 96.06 (PoT), 96.68 (CR), 95.38 (MACM), 87.71 (IIPC) - Total: ~96%
* Difficulty 3: Accuracy = 92.96 (PoT), 92.36 (CR), 91.38 (MACM), 74.42 (IIPC) - Total: ~88%
* Difficulty 4: Accuracy = 91.38 (PoT), 87.71 (CR), 86.01 (MACM), 74.42 (IIPC) - Total: ~85%
* Difficulty 5: Accuracy = 72.43 (PoT), 72.43 (CR), 72.43 (MACM), 72.43 (IIPC) - Total: ~72%
### Key Observations
* All models demonstrate decreasing accuracy as difficulty level increases.
* Gemini 2.0 Flash and Mistral Small 3.2 24B consistently exhibit the highest accuracy across most difficulty levels.
* GPT-4o-mini shows the most significant drop in accuracy with increasing difficulty, particularly at levels 4 and 5.
* The contribution of each metric (PoT, CR, MACM, IIPC) to the overall accuracy varies across models and difficulty levels.
* IIPC generally has the lowest contribution to overall accuracy, and its decline with difficulty is often more pronounced.
### Interpretation
The data suggests a clear correlation between model performance and task difficulty. More capable models (Gemini 2.0 Flash, Mistral Small 3.2 24B) maintain higher accuracy levels even as the difficulty increases. The stacked bar charts reveal that the different evaluation metrics contribute differently to the overall accuracy score. The decline in IIPC accuracy across all models with increasing difficulty suggests that this metric is particularly sensitive to task complexity. The significant drop in GPT-4o-mini's accuracy at higher difficulty levels indicates a potential limitation in its ability to generalize to more challenging tasks. This visualization is valuable for comparing the strengths and weaknesses of different LLMs and understanding how their performance varies across a range of difficulty levels. The data could be used to inform model selection for specific applications based on the expected task complexity.