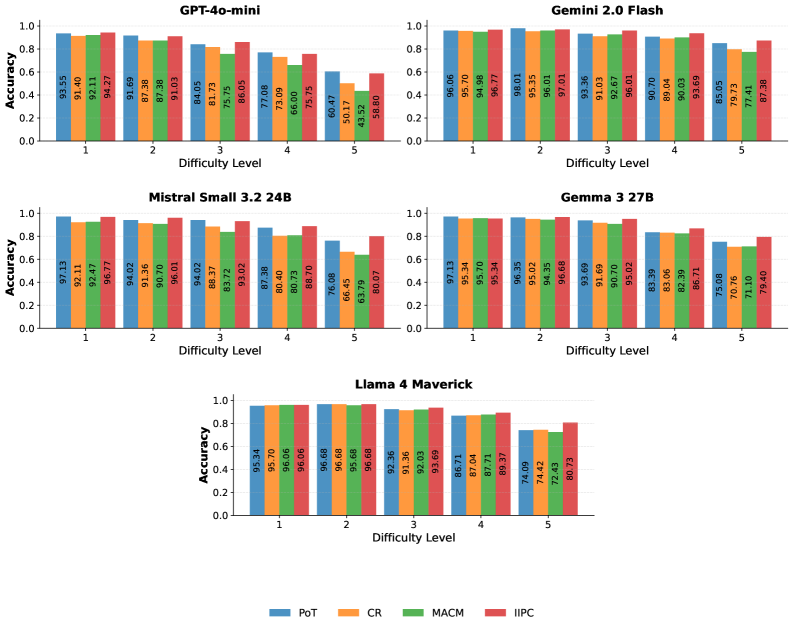
## Bar Chart: Model Accuracy Across Difficulty Levels
### Overview
The chart compares the accuracy of four AI models (GPT-4o-mini, Gemini 2.0 Flash, Mistral Small 3.2 24B, Llama 4 Maverick) across five difficulty levels (1–5). Four evaluation methods are tested: PoT (blue), CR (orange), MACM (green), and IIPC (red). Accuracy is measured on a 0–1.0 scale.
### Components/Axes
- **X-axis**: Difficulty Level (1–5, categorical)
- **Y-axis**: Accuracy (0–1.0, linear scale)
- **Legend**: Located at the bottom, mapping colors to methods:
- Blue = PoT
- Orange = CR
- Green = MACM
- Red = IIPC
- **Models**: Grouped by model name (top to bottom: GPT-4o-mini, Gemini 2.0 Flash, Mistral Small 3.2 24B, Llama 4 Maverick)
### Detailed Analysis
#### GPT-4o-mini
- **Difficulty 1**:
- PoT: 93.55 (blue)
- CR: 91.40 (orange)
- MACM: 92.11 (green)
- IIPC: 94.27 (red)
- **Difficulty 2**:
- PoT: 91.69
- CR: 87.38
- MACM: 87.38
- IIPC: 91.03
- **Difficulty 3**:
- PoT: 84.05
- CR: 81.73
- MACM: 75.75
- IIPC: 86.05
- **Difficulty 4**:
- PoT: 77.08
- CR: 73.09
- MACM: 66.00
- IIPC: 75.75
- **Difficulty 5**:
- PoT: 60.47
- CR: 50.17
- MACM: 43.52
- IIPC: 58.80
#### Gemini 2.0 Flash
- **Difficulty 1**:
- PoT: 96.06
- CR: 95.70
- MACM: 94.98
- IIPC: 96.77
- **Difficulty 2**:
- PoT: 98.01
- CR: 95.35
- MACM: 96.01
- IIPC: 97.01
- **Difficulty 3**:
- PoT: 93.36
- CR: 91.03
- MACM: 92.67
- IIPC: 96.01
- **Difficulty 4**:
- PoT: 90.70
- CR: 89.04
- MACM: 90.03
- IIPC: 93.69
- **Difficulty 5**:
- PoT: 85.05
- CR: 79.73
- MACM: 77.41
- IIPC: 87.38
#### Mistral Small 3.2 24B
- **Difficulty 1**:
- PoT: 97.13
- CR: 92.11
- MACM: 92.47
- IIPC: 96.77
- **Difficulty 2**:
- PoT: 94.02
- CR: 91.36
- MACM: 90.70
- IIPC: 96.01
- **Difficulty 3**:
- PoT: 94.02
- CR: 88.37
- MACM: 83.72
- IIPC: 93.02
- **Difficulty 4**:
- PoT: 87.38
- CR: 80.40
- MACM: 80.73
- IIPC: 88.70
- **Difficulty 5**:
- PoT: 76.08
- CR: 66.45
- MACM: 63.79
- IIPC: 80.07
#### Llama 4 Maverick
- **Difficulty 1**:
- PoT: 95.34
- CR: 95.70
- MACM: 96.06
- IIPC: 96.68
- **Difficulty 2**:
- PoT: 96.68
- CR: 95.68
- MACM: 95.68
- IIPC: 96.68
- **Difficulty 3**:
- PoT: 92.36
- CR: 91.36
- MACM: 92.03
- IIPC: 93.69
- **Difficulty 4**:
- PoT: 86.71
- CR: 87.04
- MACM: 87.71
- IIPC: 89.37
- **Difficulty 5**:
- PoT: 74.09
- CR: 74.42
- MACM: 72.43
- IIPC: 80.73
### Key Observations
1. **Accuracy Degradation**: All models show declining accuracy with increasing difficulty, but Gemini 2.0 Flash and Llama 4 Maverick maintain higher performance at Difficulty 5 compared to GPT-4o-mini and Mistral.
2. **Method Performance**:
- **PoT** (blue) generally underperforms other methods across most models and difficulties.
- **IIPC** (red) often achieves the highest accuracy, particularly for Gemini 2.0 Flash and Llama 4 Maverick.
- **MACM** (green) shows the steepest drop in accuracy at higher difficulties for GPT-4o-mini and Mistral.
3. **Outliers**:
- GPT-4o-mini’s MACM method drops to 43.52 at Difficulty 5, the lowest observed value.
- Llama 4 Maverick’s IIPC method maintains 80.73 accuracy at Difficulty 5, the highest among all models at this level.
### Interpretation
The data suggests that **IIPC** is the most robust method across models, maintaining higher accuracy even at extreme difficulty levels. **PoT** consistently underperforms, indicating potential limitations in its approach. Models like **Gemini 2.0 Flash** and **Llama 4 Maverick** demonstrate superior scalability to higher difficulties, possibly due to architectural advantages or training data quality. The divergence in MACM performance highlights sensitivity to task complexity, suggesting it may rely on specific patterns that degrade under challenging conditions. These findings underscore the importance of method selection based on expected task difficulty in real-world applications.