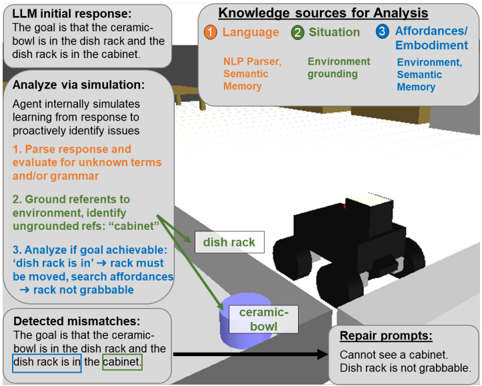
## Diagram: LLM Goal Analysis and Simulation Workflow
### Overview
This diagram illustrates a workflow for analyzing and simulating a goal-oriented task involving a robotic agent. The process includes parsing language, grounding references in an environment, evaluating goal achievability, detecting mismatches, and generating repair prompts. A visual representation of a robotic agent interacting with objects (ceramic bowl, dish rack, cabinet) is included.
### Components/Axes
#### Textual Elements
1. **LLM Initial Response** (Top-left):
- Text: "The goal is that the ceramic-bowl is in the dish rack and the dish rack is in the cabinet."
- Color: Gray background with black text.
2. **Analyze via Simulation** (Middle-left):
- Subcomponents:
- **1. Parse response and evaluate for unknown terms/grammar** (Orange text).
- **2. Ground refers to environment, identify ungrounded refs: "cabinet"** (Green text).
- **3. Analyze if goal achievable: 'dish rack is in' → rack must be moved, search affordances → rack not grabbable** (Blue text).
- Color: Gray background with orange, green, and blue text.
3. **Detected Mismatches** (Bottom-left):
- Text: "The goal is that the ceramic-bowl is in the dish rack and the dish rack is in the cabinet."
- Highlighted phrases:
- "dish rack is in the cabinet" (Blue box).
- "dish rack is in the cabinet" (Green box).
- Color: Gray background with blue and green highlights.
4. **Repair Prompts** (Bottom-right):
- Text: "Cannot see a cabinet. Dish rack is not grabbable."
- Color: Gray background with black text.
5. **Knowledge Sources for Analysis** (Top-right):
- Color-coded sections:
- **1. Language** (Orange): "NLP Parser, Semantic Memory."
- **2. Situation** (Green): "Environment grounding."
- **3. Affordances/Embodiment** (Blue): "Environment, Semantic Memory."
- Visual: Circular icons with numbers (1, 2, 3) and labels.
#### Visual Elements
- **Robot**: Black robotic agent positioned near a dish rack and cabinet.
- **Objects**:
- **Ceramic Bowl**: Purple object on the floor.
- **Dish Rack**: Black structure near the robot.
- **Cabinet**: Implied by text but not visually depicted.
- **Arrows**: Green arrows connect text boxes to visual elements (e.g., "dish rack" label).
### Detailed Analysis
#### Workflow Steps
1. **LLM Initial Response**:
- Defines the goal: Ceramic bowl in dish rack, dish rack in cabinet.
2. **Analyze via Simulation**:
- **Parsing**: Checks for unknown terms/grammar in the LLM’s response.
- **Grounding**: Identifies ungrounded references (e.g., "cabinet" not visible in the environment).
- **Achievability Analysis**: Determines if the goal is feasible (e.g., dish rack must be moved but is not grabbable).
3. **Detected Mismatches**:
- Highlights contradictions between the LLM’s goal and the environment (e.g., cabinet not visible, dish rack not grabbable).
4. **Repair Prompts**:
- Suggests adjustments to resolve mismatches (e.g., "Cannot see a cabinet," "Dish rack is not grabbable").
#### Knowledge Sources
- **Language**: NLP Parser and Semantic Memory for text analysis.
- **Situation**: Environment grounding to link text to physical objects.
- **Affordances/Embodiment**: Environment and Semantic Memory for action feasibility.
### Key Observations
- The workflow emphasizes **environmental grounding** as critical for aligning language-based goals with physical reality.
- The **detected mismatch** reveals a disconnect between the LLM’s assumption (dish rack in cabinet) and the simulated environment (cabinet not visible).
- **Repair prompts** address both perceptual (unseen cabinet) and actional (ungrabbable dish rack) limitations.
### Interpretation
This diagram demonstrates a closed-loop system where an LLM’s goal is validated through simulation, leveraging language parsing, environmental grounding, and affordance analysis. The mismatch detection and repair prompts highlight the importance of **situational awareness** in robotic tasks. The absence of a visible cabinet in the environment underscores the need for robust grounding mechanisms to prevent hallucinations. The workflow bridges abstract language goals with concrete physical constraints, emphasizing the interplay between **semantic memory** (knowledge of objects) and **embodied action** (robot capabilities).
**Notable Anomalies**:
- The cabinet is referenced in text but not depicted visually, creating ambiguity.
- The dish rack’s ungrabbable state suggests limitations in the robot’s current capabilities.
**Note**: No numerical data or charts are present; the diagram focuses on textual and visual workflow components.