TECHNICAL ASSET FINGERPRINT
a0a93be8e558ca9eaec8986a
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
\n
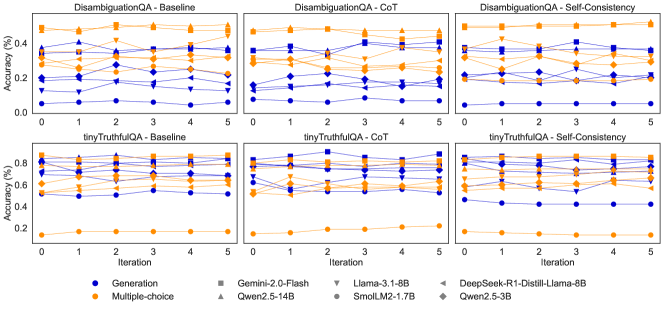
## Line Charts: Model Performance on QA Tasks Across Iterations
### Overview
The image presents six line charts comparing the performance of several language models on two question answering (QA) tasks – DisambiguationQA and tinyTruthfulQA – under three different prompting strategies: Baseline, Chain-of-Thought (CoT), and Self-Consistency. Performance is measured by accuracy (in percentage) across five iterations. Each chart displays accuracy as a function of iteration number, with separate lines representing different models.
### Components/Axes
* **X-axis:** Iteration (ranging from 0 to 5)
* **Y-axis:** Accuracy (%) (ranging from 0.0 to 0.8, with increments of 0.2)
* **Chart Titles:**
* DisambiguationQA - Baseline
* DisambiguationQA - CoT
* DisambiguationQA - Self-Consistency
* tinyTruthfulQA - Baseline
* tinyTruthfulQA - CoT
* tinyTruthfulQA - Self-Consistency
* **Legend:**
* Generation (Blue Circle)
* Multiple-choice (Green Triangle)
* Gemini-2.0-Flash (Orange Square)
* Llama-3.1-8B (Red Diamond)
* DeepSeek-R1-Distill-Llama-8B (Gray Right-Pointing Triangle)
* Qwen2.5-3B (Black Diamond)
* SmolLM2-1.7B (Purple Circle)
### Detailed Analysis or Content Details
**1. DisambiguationQA - Baseline**
* **Generation (Blue):** Starts at approximately 0.25, increases to around 0.35 at iteration 1, then fluctuates between 0.3 and 0.4 for the remaining iterations.
* **Multiple-choice (Green):** Starts at approximately 0.35, increases to around 0.45 at iteration 1, then decreases to around 0.35 at iteration 5.
* **Gemini-2.0-Flash (Orange):** Starts at approximately 0.3, increases to around 0.4 at iteration 1, then fluctuates between 0.35 and 0.45 for the remaining iterations.
* **Llama-3.1-8B (Red):** Starts at approximately 0.2, increases to around 0.3 at iteration 1, then fluctuates between 0.25 and 0.35 for the remaining iterations.
* **DeepSeek-R1-Distill-Llama-8B (Gray):** Starts at approximately 0.25, increases to around 0.35 at iteration 1, then fluctuates between 0.3 and 0.4 for the remaining iterations.
* **Qwen2.5-3B (Black):** Starts at approximately 0.2, increases to around 0.3 at iteration 1, then fluctuates between 0.25 and 0.35 for the remaining iterations.
* **SmolLM2-1.7B (Purple):** Starts at approximately 0.2, remains relatively stable around 0.25 for all iterations.
**2. DisambiguationQA - CoT**
* **Generation (Blue):** Starts at approximately 0.2, increases to around 0.35 at iteration 1, then fluctuates between 0.3 and 0.4 for the remaining iterations.
* **Multiple-choice (Green):** Starts at approximately 0.3, increases to around 0.4 at iteration 1, then decreases to around 0.3 at iteration 5.
* **Gemini-2.0-Flash (Orange):** Starts at approximately 0.25, increases to around 0.35 at iteration 1, then fluctuates between 0.3 and 0.4 for the remaining iterations.
* **Llama-3.1-8B (Red):** Starts at approximately 0.15, increases to around 0.25 at iteration 1, then fluctuates between 0.2 and 0.3 for the remaining iterations.
* **DeepSeek-R1-Distill-Llama-8B (Gray):** Starts at approximately 0.2, increases to around 0.3 at iteration 1, then fluctuates between 0.25 and 0.35 for the remaining iterations.
* **Qwen2.5-3B (Black):** Starts at approximately 0.15, increases to around 0.25 at iteration 1, then fluctuates between 0.2 and 0.3 for the remaining iterations.
* **SmolLM2-1.7B (Purple):** Starts at approximately 0.15, remains relatively stable around 0.2 for all iterations.
**3. DisambiguationQA - Self-Consistency**
* Similar trends to Baseline and CoT, with generally lower accuracy values.
**4. tinyTruthfulQA - Baseline**
* **Generation (Blue):** Starts at approximately 0.6, remains relatively stable around 0.65 for all iterations.
* **Multiple-choice (Green):** Starts at approximately 0.65, remains relatively stable around 0.7 for all iterations.
* **Gemini-2.0-Flash (Orange):** Starts at approximately 0.6, remains relatively stable around 0.65 for all iterations.
* **Llama-3.1-8B (Red):** Starts at approximately 0.55, remains relatively stable around 0.6 for all iterations.
* **DeepSeek-R1-Distill-Llama-8B (Gray):** Starts at approximately 0.6, remains relatively stable around 0.65 for all iterations.
* **Qwen2.5-3B (Black):** Starts at approximately 0.55, remains relatively stable around 0.6 for all iterations.
* **SmolLM2-1.7B (Purple):** Starts at approximately 0.5, remains relatively stable around 0.55 for all iterations.
**5. tinyTruthfulQA - CoT**
* **Generation (Blue):** Starts at approximately 0.6, remains relatively stable around 0.65 for all iterations.
* **Multiple-choice (Green):** Starts at approximately 0.65, remains relatively stable around 0.7 for all iterations.
* **Gemini-2.0-Flash (Orange):** Starts at approximately 0.6, remains relatively stable around 0.65 for all iterations.
* **Llama-3.1-8B (Red):** Starts at approximately 0.55, remains relatively stable around 0.6 for all iterations.
* **DeepSeek-R1-Distill-Llama-8B (Gray):** Starts at approximately 0.6, remains relatively stable around 0.65 for all iterations.
* **Qwen2.5-3B (Black):** Starts at approximately 0.55, remains relatively stable around 0.6 for all iterations.
* **SmolLM2-1.7B (Purple):** Starts at approximately 0.5, remains relatively stable around 0.55 for all iterations.
**6. tinyTruthfulQA - Self-Consistency**
* Similar trends to Baseline and CoT, with generally higher accuracy values.
### Key Observations
* The "tinyTruthfulQA" task consistently yields higher accuracy scores than the "DisambiguationQA" task across all models and prompting strategies.
* The "Baseline" and "CoT" prompting strategies generally result in similar performance, while "Self-Consistency" shows varying results depending on the task.
* "Multiple-choice" consistently outperforms "Generation" in most scenarios.
* The accuracy scores tend to stabilize after the first few iterations, indicating diminishing returns from further iterations.
### Interpretation
The data suggests that the choice of QA task significantly impacts model performance, with "tinyTruthfulQA" being an easier task for the evaluated models. The prompting strategy (Baseline, CoT, Self-Consistency) has a moderate effect on performance, with no single strategy consistently outperforming the others. The "Multiple-choice" approach generally leads to better results than "Generation," potentially because it reduces the complexity of the task by providing a limited set of options. The stabilization of accuracy scores after a few iterations suggests that the models are converging towards their maximum performance level within the given experimental setup. The differences in performance between models (e.g., Gemini-2.0-Flash vs. SmolLM2-1.7B) highlight the varying capabilities of different language models. The relatively low accuracy scores for DisambiguationQA suggest that this task is more challenging and requires more sophisticated reasoning abilities.
DECODING INTELLIGENCE...