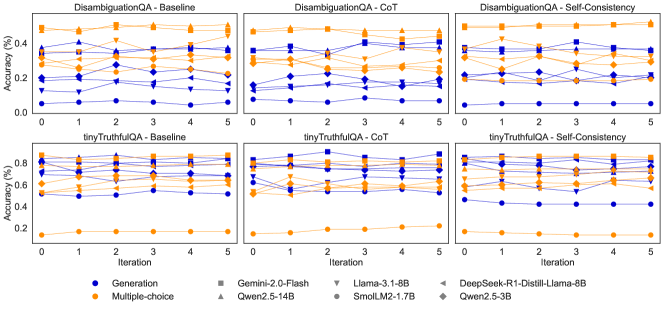
## Line Graphs: Model Performance Across Prompting Methods
### Overview
The image contains six line graphs arranged in a 2x3 grid, comparing model accuracy across iterations (0-5) for two QA tasks: **DisambiguationQA** (top row) and **tinyTruthfulQA** (bottom row). Each graph evaluates three prompting methods: **Baseline**, **CoT (Chain-of-Thought)**, and **Self-Consistency**. Accuracy (%) is plotted on the y-axis, while iterations (0-5) are on the x-axis. Models are differentiated by color and marker type in the legend.
---
### Components/Axes
- **X-axis**: Iteration (0 to 5, integer steps).
- **Y-axis**: Accuracy (%) (0% to 80%, with increments of ~20%).
- **Legend**: Located at the bottom of all graphs. Models include:
- **Generation** (blue circles)
- **Multiple-choice** (orange squares)
- **Gemini 2.0-Flash** (gray squares)
- **Llama 3.1-8B** (gray triangles)
- **DeepSeek-R1-Distill-Llama-8B** (gray diamonds)
- **Qwen2.5-14B** (orange triangles)
- **SmolLM2-1.7B** (orange diamonds)
- **Qwen2.5-3B** (blue triangles)
---
### Detailed Analysis
#### DisambiguationQA - Baseline
- **Generation** (blue circles): Starts at ~0.3%, peaks at iteration 2 (~0.4%), then declines to ~0.2% by iteration 5.
- **Multiple-choice** (orange squares): Starts at ~0.1%, peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **Gemini 2.0-Flash** (gray squares): Stable at ~0.4% across all iterations.
- **Llama 3.1-8B** (gray triangles): Peaks at iteration 1 (~0.5%), then declines to ~0.3%.
- **DeepSeek-R1-Distill-Llama-8B** (gray diamonds): Stable at ~0.4%.
- **Qwen2.5-14B** (orange triangles): Starts at ~0.2%, peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **SmolLM2-1.7B** (orange diamonds): Stable at ~0.3%.
- **Qwen2.5-3B** (blue triangles): Stable at ~0.3%.
#### DisambiguationQA - CoT
- **Generation**: Peaks at iteration 2 (~0.4%), then declines to ~0.2%.
- **Multiple-choice**: Peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **Gemini 2.0-Flash**: Stable at ~0.4%.
- **Llama 3.1-8B**: Peaks at iteration 1 (~0.5%), then declines to ~0.3%.
- **DeepSeek-R1-Distill-Llama-8B**: Stable at ~0.4%.
- **Qwen2.5-14B**: Peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **SmolLM2-1.7B**: Stable at ~0.3%.
- **Qwen2.5-3B**: Stable at ~0.3%.
#### DisambiguationQA - Self-Consistency
- **Generation**: Peaks at iteration 2 (~0.4%), then declines to ~0.2%.
- **Multiple-choice**: Peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **Gemini 2.0-Flash**: Stable at ~0.4%.
- **Llama 3.1-8B**: Peaks at iteration 1 (~0.5%), then declines to ~0.3%.
- **DeepSeek-R1-Distill-Llama-8B**: Stable at ~0.4%.
- **Qwen2.5-14B**: Peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **SmolLM2-1.7B**: Stable at ~0.3%.
- **Qwen2.5-3B**: Stable at ~0.3%.
#### tinyTruthfulQA - Baseline
- **Generation**: Starts at ~0.5%, peaks at iteration 2 (~0.6%), then declines to ~0.4%.
- **Multiple-choice**: Starts at ~0.2%, peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **Gemini 2.0-Flash**: Stable at ~0.6%.
- **Llama 3.1-8B**: Peaks at iteration 1 (~0.7%), then declines to ~0.5%.
- **DeepSeek-R1-Distill-Llama-8B**: Stable at ~0.6%.
- **Qwen2.5-14B**: Peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **SmolLM2-1.7B**: Stable at ~0.3%.
- **Qwen2.5-3B**: Stable at ~0.3%.
#### tinyTruthfulQA - CoT
- **Generation**: Peaks at iteration 2 (~0.6%), then declines to ~0.4%.
- **Multiple-choice**: Peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **Gemini 2.0-Flash**: Stable at ~0.6%.
- **Llama 3.1-8B**: Peaks at iteration 1 (~0.7%), then declines to ~0.5%.
- **DeepSeek-R1-Distill-Llama-8B**: Stable at ~0.6%.
- **Qwen2.5-14B**: Peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **SmolLM2-1.7B**: Stable at ~0.3%.
- **Qwen2.5-3B**: Stable at ~0.3%.
#### tinyTruthfulQA - Self-Consistency
- **Generation**: Peaks at iteration 2 (~0.6%), then declines to ~0.4%.
- **Multiple-choice**: Peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **Gemini 2.0-Flash**: Stable at ~0.6%.
- **Llama 3.1-8B**: Peaks at iteration 1 (~0.7%), then declines to ~0.5%.
- **DeepSeek-R1-Distill-Llama-8B**: Stable at ~0.6%.
- **Qwen2.5-14B**: Peaks at iteration 3 (~0.3%), then drops to ~0.2%.
- **SmolLM2-1.7B**: Stable at ~0.3%.
- **Qwen2.5-3B**: Stable at ~0.3%.
---
### Key Observations
1. **CoT and Self-Consistency** generally outperform **Baseline** in both tasks, with higher accuracy and stability.
2. **Gemini 2.0-Flash** and **DeepSeek-R1-Distill-Llama-8B** consistently achieve the highest accuracy (~0.6% in tinyTruthfulQA).
3. **Llama 3.1-8B** shows strong initial performance but declines over iterations.
4. **Multiple-choice** and **Qwen2.5-14B** exhibit the lowest accuracy, with minimal improvement across iterations.
5. **tinyTruthfulQA** graphs show higher baseline accuracy (~0.5-0.7%) compared to DisambiguationQA (~0.2-0.5%).
---
### Interpretation
The data suggests that **prompting methods** significantly impact model performance. **CoT** and **Self-Consistency** improve accuracy over **Baseline**, likely by encouraging structured reasoning. **Gemini 2.0-Flash** and **DeepSeek-R1-Distill-Llama-8B** outperform other models, indicating superior architecture or training for these tasks. The decline in accuracy for some models (e.g., Llama 3.1-8B) over iterations may reflect overfitting or sensitivity to input variations. **tinyTruthfulQA** tasks are inherently more challenging, as evidenced by lower overall accuracy compared to DisambiguationQA. The stability of certain models (e.g., Gemini 2.0-Flash) highlights their robustness to iterative changes.