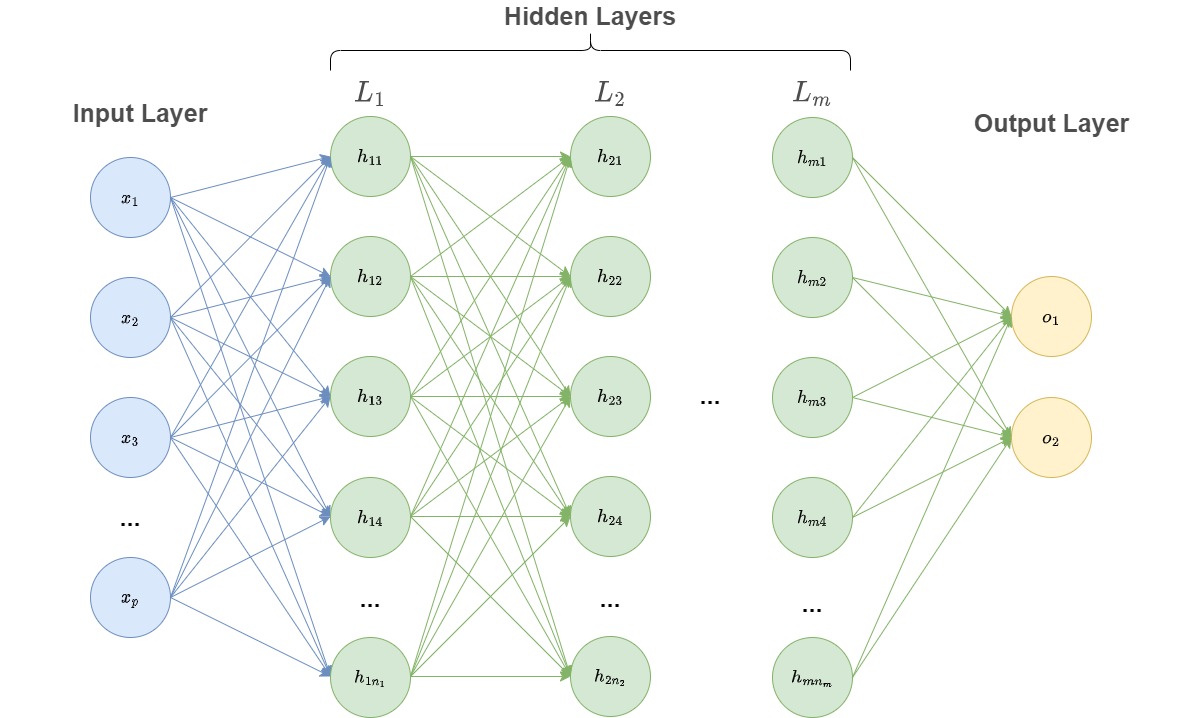
## Diagram: Neural Network Architecture
### Overview
The image is a diagram illustrating the architecture of a neural network. It shows the flow of information from the input layer through multiple hidden layers to the output layer. The diagram highlights the connections between neurons in adjacent layers.
### Components/Axes
* **Layers:**
* Input Layer: Labeled "Input Layer" on the left. Contains nodes x1, x2, x3, ..., xp. Nodes are colored blue.
* Hidden Layers: Labeled "Hidden Layers" at the top. Contains multiple layers labeled L1, L2, ..., Lm. Each hidden layer contains nodes h11, h12, h13, h14, ..., h1n1 for L1; h21, h22, h23, h24, ..., h2n2 for L2; and hm1, hm2, hm3, hm4, ..., hmnm for Lm. Nodes are colored green.
* Output Layer: Labeled "Output Layer" on the right. Contains nodes o1, o2. Nodes are colored yellow.
* **Connections:**
* Connections between the input layer and the first hidden layer (L1) are blue.
* Connections between hidden layers (L1 to L2, L2 to Lm) are green.
* Connections between the last hidden layer (Lm) and the output layer are green.
### Detailed Analysis
* **Input Layer:**
* Nodes: x1, x2, x3, ..., xp.
* Color: Blue.
* Arrangement: Vertically stacked.
* **Hidden Layer L1:**
* Nodes: h11, h12, h13, h14, ..., h1n1.
* Color: Green.
* Arrangement: Vertically stacked.
* **Hidden Layer L2:**
* Nodes: h21, h22, h23, h24, ..., h2n2.
* Color: Green.
* Arrangement: Vertically stacked.
* **Hidden Layer Lm:**
* Nodes: hm1, hm2, hm3, hm4, ..., hmnm.
* Color: Green.
* Arrangement: Vertically stacked.
* **Output Layer:**
* Nodes: o1, o2.
* Color: Yellow.
* Arrangement: Vertically stacked.
* **Connections:**
* Each node in the input layer is connected to every node in the first hidden layer (L1).
* Each node in each hidden layer is connected to every node in the subsequent hidden layer.
* Each node in the last hidden layer (Lm) is connected to every node in the output layer.
### Key Observations
* The diagram illustrates a fully connected neural network.
* The number of nodes in each layer can vary.
* The diagram uses color to differentiate the layers and connections.
### Interpretation
The diagram represents a standard feedforward neural network architecture. The input layer receives the initial data, which is then processed through multiple hidden layers. Each hidden layer applies a series of transformations to the data, and the final output is produced by the output layer. The connections between the nodes represent the weights of the network, which are learned during the training process. The diagram highlights the flow of information and the interconnectedness of the network's components. The "..." notation indicates that the number of nodes in each layer can be variable and potentially large.