TECHNICAL ASSET FINGERPRINT
a0fe971a07a13d32c677d33d
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemini-2.0-flash VERSION 1
RUNTIME: nugit/gemini/gemini-2.0-flash
INTEL_VERIFIED
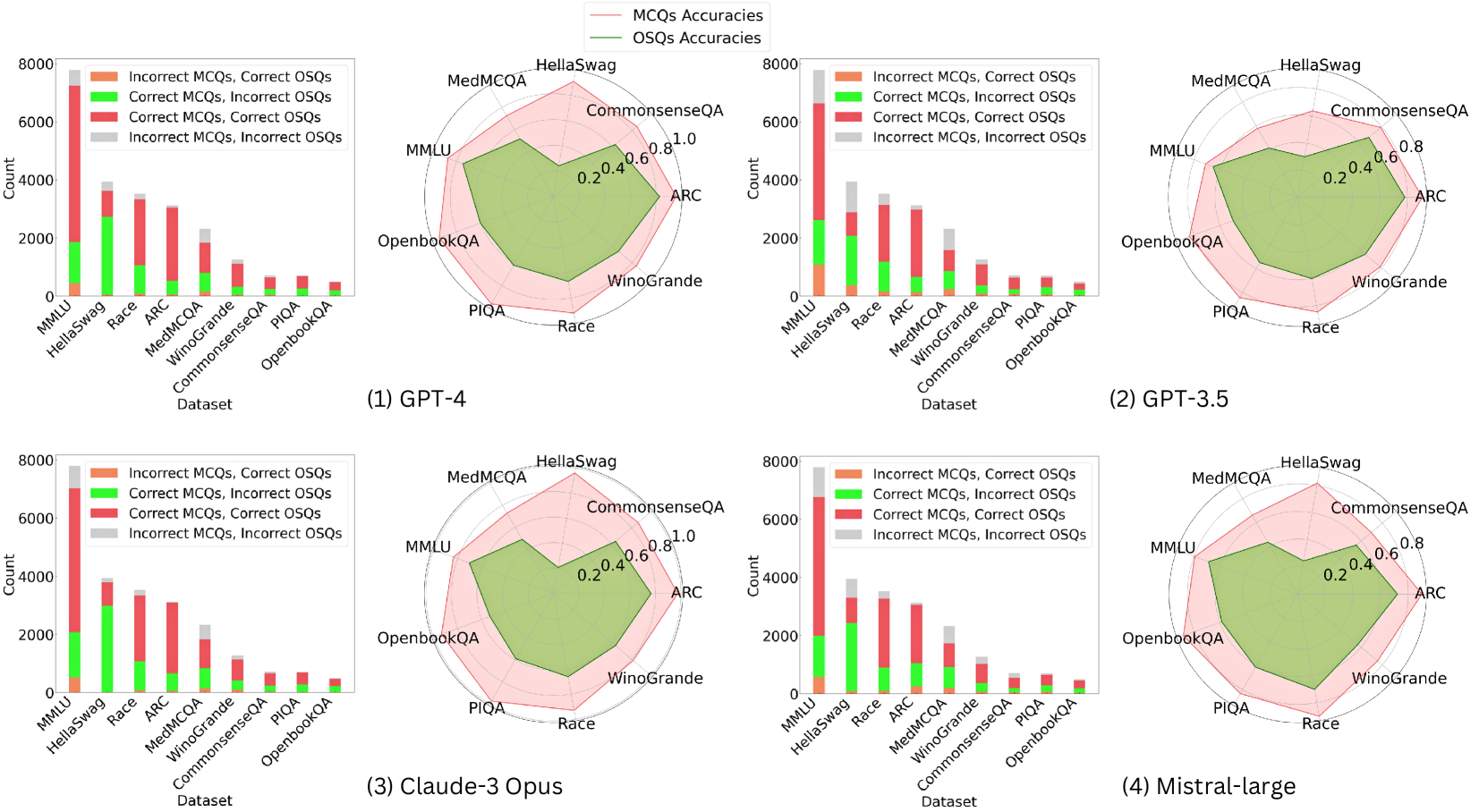
## Chart/Diagram Type: Comparative Performance Charts
### Overview
The image presents a comparative analysis of four different language models (GPT-4, GPT-3.5, Claude-3 Opus, and Mistral-large) across various datasets. The analysis is visualized using a combination of bar charts and radar charts. The bar charts show the counts of correct and incorrect Multiple Choice Questions (MCQs) and Open-ended Short Questions (OSQs) for each dataset. The radar charts display the accuracies for MCQs and OSQs across the same datasets.
### Components/Axes
**General Components:**
* Four subplots, each representing a different language model.
* Each subplot contains a bar chart and a radar chart.
* The datasets used are: MMLU, HellaSwag, Race, ARC, MedMCQA, WinoGrande, CommonsenseQA, PIQA, and OpenbookQA.
**Bar Chart Components:**
* **Y-axis:** "Count", ranging from 0 to 8000, with increments of 2000.
* **X-axis:** "Dataset", listing the datasets mentioned above.
* **Legend (Top):**
* Orange: "Incorrect MCQs, Correct OSQs"
* Green: "Correct MCQs, Incorrect OSQs"
* Red: "Correct MCQs, Correct OSQs"
* Gray: "Incorrect MCQs, Incorrect OSQs"
**Radar Chart Components:**
* The radar charts display accuracies ranging from 0.2 to 1.0, with increments of 0.2.
* The datasets are arranged around the perimeter of the radar chart.
* **Legend (Top):**
* Pink Line: "MCQs Accuracies"
* Green Line: "OSQs Accuracies"
### Detailed Analysis
#### (1) GPT-4
* **Bar Chart:**
* MMLU: Red bar ~2800, Green bar ~100, Gray bar ~3800, Orange bar ~1000
* HellaSwag: Red bar ~2000, Green bar ~1800, Gray bar ~100, Orange bar ~3800
* Race: Red bar ~2200, Green bar ~1000, Gray bar ~100, Orange bar ~3000
* ARC: Red bar ~2000, Green bar ~1000, Gray bar ~100, Orange bar ~2800
* MedMCQA: Red bar ~1800, Green bar ~100, Gray bar ~100, Orange bar ~1200
* WinoGrande: Red bar ~800, Green bar ~100, Gray bar ~100, Orange bar ~1000
* CommonsenseQA: Red bar ~800, Green bar ~100, Gray bar ~100, Orange bar ~800
* PIQA: Red bar ~600, Green bar ~100, Gray bar ~100, Orange bar ~600
* OpenbookQA: Red bar ~600, Green bar ~100, Gray bar ~100, Orange bar ~600
* **Radar Chart:**
* MCQs Accuracies (Pink): Ranges from approximately 0.5 (PIQA) to 0.9 (HellaSwag).
* OSQs Accuracies (Green): Ranges from approximately 0.4 (PIQA) to 0.8 (HellaSwag).
#### (2) GPT-3.5
* **Bar Chart:**
* MMLU: Red bar ~2000, Green bar ~100, Gray bar ~4800, Orange bar ~1000
* HellaSwag: Red bar ~1800, Green bar ~1000, Gray bar ~100, Orange bar ~3000
* Race: Red bar ~1800, Green bar ~800, Gray bar ~100, Orange bar ~2200
* ARC: Red bar ~1600, Green bar ~800, Gray bar ~100, Orange bar ~2000
* MedMCQA: Red bar ~1400, Green bar ~100, Gray bar ~100, Orange bar ~1000
* WinoGrande: Red bar ~600, Green bar ~100, Gray bar ~100, Orange bar ~800
* CommonsenseQA: Red bar ~600, Green bar ~100, Gray bar ~100, Orange bar ~600
* PIQA: Red bar ~400, Green bar ~100, Gray bar ~100, Orange bar ~400
* OpenbookQA: Red bar ~400, Green bar ~100, Gray bar ~100, Orange bar ~400
* **Radar Chart:**
* MCQs Accuracies (Pink): Ranges from approximately 0.4 (PIQA) to 0.8 (HellaSwag).
* OSQs Accuracies (Green): Ranges from approximately 0.3 (PIQA) to 0.7 (HellaSwag).
#### (3) Claude-3 Opus
* **Bar Chart:**
* MMLU: Red bar ~5800, Green bar ~100, Gray bar ~1000, Orange bar ~1000
* HellaSwag: Red bar ~3000, Green bar ~800, Gray bar ~100, Orange bar ~3800
* Race: Red bar ~2800, Green bar ~800, Gray bar ~100, Orange bar ~2200
* ARC: Red bar ~2600, Green bar ~800, Gray bar ~100, Orange bar ~2000
* MedMCQA: Red bar ~2000, Green bar ~100, Gray bar ~100, Orange bar ~1000
* WinoGrande: Red bar ~800, Green bar ~100, Gray bar ~100, Orange bar ~800
* CommonsenseQA: Red bar ~800, Green bar ~100, Gray bar ~100, Orange bar ~600
* PIQA: Red bar ~600, Green bar ~100, Gray bar ~100, Orange bar ~400
* OpenbookQA: Red bar ~600, Green bar ~100, Gray bar ~100, Orange bar ~400
* **Radar Chart:**
* MCQs Accuracies (Pink): Ranges from approximately 0.5 (PIQA) to 0.9 (HellaSwag).
* OSQs Accuracies (Green): Ranges from approximately 0.4 (PIQA) to 0.8 (HellaSwag).
#### (4) Mistral-large
* **Bar Chart:**
* MMLU: Red bar ~6000, Green bar ~100, Gray bar ~800, Orange bar ~1000
* HellaSwag: Red bar ~3000, Green bar ~800, Gray bar ~100, Orange bar ~3800
* Race: Red bar ~2800, Green bar ~800, Gray bar ~100, Orange bar ~2200
* ARC: Red bar ~2600, Green bar ~800, Gray bar ~100, Orange bar ~2000
* MedMCQA: Red bar ~2000, Green bar ~100, Gray bar ~100, Orange bar ~1000
* WinoGrande: Red bar ~800, Green bar ~100, Gray bar ~100, Orange bar ~800
* CommonsenseQA: Red bar ~800, Green bar ~100, Gray bar ~100, Orange bar ~600
* PIQA: Red bar ~600, Green bar ~100, Gray bar ~100, Orange bar ~400
* OpenbookQA: Red bar ~600, Green bar ~100, Gray bar ~100, Orange bar ~400
* **Radar Chart:**
* MCQs Accuracies (Pink): Ranges from approximately 0.5 (PIQA) to 0.9 (HellaSwag).
* OSQs Accuracies (Green): Ranges from approximately 0.4 (PIQA) to 0.8 (HellaSwag).
### Key Observations
* **MMLU Performance:** All models show a significant number of incorrect MCQs and incorrect OSQs on the MMLU dataset, as indicated by the large gray bars.
* **HellaSwag Performance:** All models perform relatively well on the HellaSwag dataset, with a high number of correct MCQs and incorrect OSQs, as indicated by the large orange bars.
* **Accuracy Range:** The radar charts indicate that the accuracy for both MCQs and OSQs varies across datasets, with HellaSwag generally showing the highest accuracy and PIQA showing the lowest.
* **Model Comparison:** Claude-3 Opus and Mistral-large appear to have similar performance profiles, with slightly better performance on MMLU compared to GPT-3.5 and GPT-4.
### Interpretation
The data suggests that the performance of language models varies significantly depending on the dataset. The MMLU dataset appears to be particularly challenging for all models, while HellaSwag is relatively easier. The radar charts highlight the differences in accuracy across datasets, providing a visual representation of the models' strengths and weaknesses. The bar charts offer a more granular view, showing the counts of correct and incorrect answers for both MCQs and OSQs.
The models' performance on different datasets likely reflects the nature of the tasks and the types of knowledge required. For example, MMLU may require more complex reasoning or specialized knowledge, while HellaSwag may be more reliant on common sense or pattern recognition.
The comparison between models reveals that Claude-3 Opus and Mistral-large have similar performance profiles, and they outperform GPT-3.5 and GPT-4 on the MMLU dataset. This suggests that these models may have improved capabilities in certain areas, such as complex reasoning or knowledge retrieval.
DECODING INTELLIGENCE...