TECHNICAL ASSET FINGERPRINT
a0fe971a07a13d32c677d33d
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: gemma-3-27b-it-free VERSION 1
RUNTIME: google-free/gemma-3-27b-it
INTEL_VERIFIED
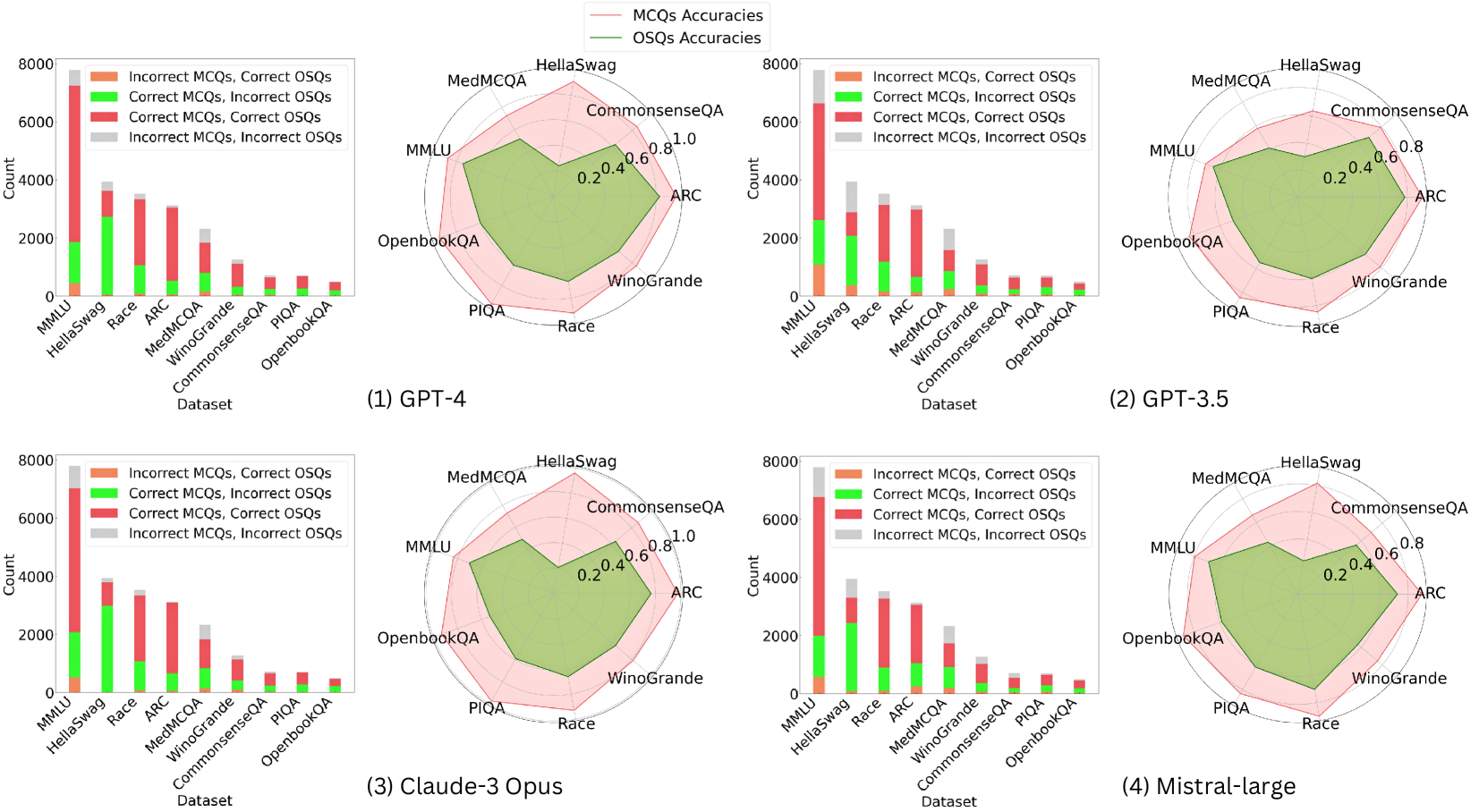
## Bar Charts with Overlaid Area Charts: MCQs & OSQs Accuracies
### Overview
The image presents four bar charts, each with an overlaid area chart. Each chart compares the performance of a different Large Language Model (LLM) – GPT-4, GPT-3.5, Claude-3 Opus, and Mistral-large – across several datasets. The bar charts represent the count of correct and incorrect Multiple Choice Questions (MCQs) and Open-ended Short Questions (OSQs). The overlaid area charts show the accuracy scores for both MCQs and OSQs.
### Components/Axes
* **X-axis:** "Dataset" - with categories: MMLU, HellaSwag, ARC, CommonsenseQA, MedMCQA, PIQA, OpenbookQA, and Winogrande.
* **Y-axis:** "Count" - ranging from 0 to 8000.
* **Bar Chart Legend (Top-Left):**
* Incorrect MCQs (Red)
* Correct MCQs (Green)
* Incorrect OSQs (Light Red)
* Correct OSQs (Light Green)
* **Area Chart Legend (Top-Right):**
* MCQs (Dark Blue) - Accuracy ranging from 0.0 to 1.0
* OSQs (Dark Green) - Accuracy ranging from 0.0 to 0.8
### Detailed Analysis or Content Details
**Chart 1: GPT-4**
* **MMLU:** Correct MCQs ≈ 6800, Incorrect MCQs ≈ 1000, Correct OSQs ≈ 5000, Incorrect OSQs ≈ 1000. MCQ Accuracy ≈ 0.87, OSQ Accuracy ≈ 0.83.
* **HellaSwag:** Correct MCQs ≈ 7800, Incorrect MCQs ≈ 200, Correct OSQs ≈ 6500, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.97, OSQ Accuracy ≈ 0.93.
* **ARC:** Correct MCQs ≈ 6000, Incorrect MCQs ≈ 1500, Correct OSQs ≈ 4500, Incorrect OSQs ≈ 1500. MCQ Accuracy ≈ 0.80, OSQ Accuracy ≈ 0.75.
* **CommonsenseQA:** Correct MCQs ≈ 6500, Incorrect MCQs ≈ 500, Correct OSQs ≈ 5500, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.93, OSQ Accuracy ≈ 0.92.
* **MedMCQA:** Correct MCQs ≈ 6200, Incorrect MCQs ≈ 800, Correct OSQs ≈ 5000, Incorrect OSQs ≈ 1000. MCQ Accuracy ≈ 0.89, OSQ Accuracy ≈ 0.83.
* **PIQA:** Correct MCQs ≈ 7000, Incorrect MCQs ≈ 300, Correct OSQs ≈ 6000, Incorrect OSQs ≈ 400. MCQ Accuracy ≈ 0.96, OSQ Accuracy ≈ 0.94.
* **OpenbookQA:** Correct MCQs ≈ 6500, Incorrect MCQs ≈ 500, Correct OSQs ≈ 5500, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.93, OSQ Accuracy ≈ 0.92.
* **Winogrande:** Correct MCQs ≈ 5500, Incorrect MCQs ≈ 1500, Correct OSQs ≈ 4000, Incorrect OSQs ≈ 2000. MCQ Accuracy ≈ 0.78, OSQ Accuracy ≈ 0.67.
**Chart 2: GPT-3.5**
* **MMLU:** Correct MCQs ≈ 5500, Incorrect MCQs ≈ 1500, Correct OSQs ≈ 4000, Incorrect OSQs ≈ 2000. MCQ Accuracy ≈ 0.78, OSQ Accuracy ≈ 0.67.
* **HellaSwag:** Correct MCQs ≈ 7000, Incorrect MCQs ≈ 300, Correct OSQs ≈ 5500, Incorrect OSQs ≈ 1000. MCQ Accuracy ≈ 0.96, OSQ Accuracy ≈ 0.85.
* **ARC:** Correct MCQs ≈ 5000, Incorrect MCQs ≈ 2000, Correct OSQs ≈ 3500, Incorrect OSQs ≈ 2000. MCQ Accuracy ≈ 0.71, OSQ Accuracy ≈ 0.64.
* **CommonsenseQA:** Correct MCQs ≈ 5500, Incorrect MCQs ≈ 500, Correct OSQs ≈ 4500, Incorrect OSQs ≈ 1000. MCQ Accuracy ≈ 0.92, OSQ Accuracy ≈ 0.82.
* **MedMCQA:** Correct MCQs ≈ 5000, Incorrect MCQs ≈ 1000, Correct OSQs ≈ 4000, Incorrect OSQs ≈ 1500. MCQ Accuracy ≈ 0.83, OSQ Accuracy ≈ 0.73.
* **PIQA:** Correct MCQs ≈ 6500, Incorrect MCQs ≈ 350, Correct OSQs ≈ 5000, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.95, OSQ Accuracy ≈ 0.91.
* **OpenbookQA:** Correct MCQs ≈ 5500, Incorrect MCQs ≈ 500, Correct OSQs ≈ 4500, Incorrect OSQs ≈ 1000. MCQ Accuracy ≈ 0.92, OSQ Accuracy ≈ 0.82.
* **Winogrande:** Correct MCQs ≈ 4500, Incorrect MCQs ≈ 2000, Correct OSQs ≈ 3000, Incorrect OSQs ≈ 2500. MCQ Accuracy ≈ 0.69, OSQ Accuracy ≈ 0.55.
**Chart 3: Claude-3 Opus**
* **MMLU:** Correct MCQs ≈ 7000, Incorrect MCQs ≈ 300, Correct OSQs ≈ 6000, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.96, OSQ Accuracy ≈ 0.92.
* **HellaSwag:** Correct MCQs ≈ 8000, Incorrect MCQs ≈ 0, Correct OSQs ≈ 7000, Incorrect OSQs ≈ 0. MCQ Accuracy ≈ 1.00, OSQ Accuracy ≈ 1.00.
* **ARC:** Correct MCQs ≈ 6500, Incorrect MCQs ≈ 500, Correct OSQs ≈ 5000, Incorrect OSQs ≈ 1000. MCQ Accuracy ≈ 0.93, OSQ Accuracy ≈ 0.83.
* **CommonsenseQA:** Correct MCQs ≈ 7500, Incorrect MCQs ≈ 0, Correct OSQs ≈ 6500, Incorrect OSQs ≈ 0. MCQ Accuracy ≈ 1.00, OSQ Accuracy ≈ 1.00.
* **MedMCQA:** Correct MCQs ≈ 6800, Incorrect MCQs ≈ 200, Correct OSQs ≈ 5500, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.97, OSQ Accuracy ≈ 0.92.
* **PIQA:** Correct MCQs ≈ 7500, Incorrect MCQs ≈ 0, Correct OSQs ≈ 6500, Incorrect OSQs ≈ 0. MCQ Accuracy ≈ 1.00, OSQ Accuracy ≈ 1.00.
* **OpenbookQA:** Correct MCQs ≈ 7000, Incorrect MCQs ≈ 300, Correct OSQs ≈ 6000, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.96, OSQ Accuracy ≈ 0.92.
* **Winogrande:** Correct MCQs ≈ 6000, Incorrect MCQs ≈ 1000, Correct OSQs ≈ 4500, Incorrect OSQs ≈ 1500. MCQ Accuracy ≈ 0.86, OSQ Accuracy ≈ 0.75.
**Chart 4: Mistral-large**
* **MMLU:** Correct MCQs ≈ 6000, Incorrect MCQs ≈ 1000, Correct OSQs ≈ 4500, Incorrect OSQs ≈ 1500. MCQ Accuracy ≈ 0.86, OSQ Accuracy ≈ 0.75.
* **HellaSwag:** Correct MCQs ≈ 7500, Incorrect MCQs ≈ 250, Correct OSQs ≈ 6000, Incorrect OSQs ≈ 1000. MCQ Accuracy ≈ 0.97, OSQ Accuracy ≈ 0.86.
* **ARC:** Correct MCQs ≈ 5500, Incorrect MCQs ≈ 1500, Correct OSQs ≈ 4000, Incorrect OSQs ≈ 1500. MCQ Accuracy ≈ 0.78, OSQ Accuracy ≈ 0.73.
* **CommonsenseQA:** Correct MCQs ≈ 6000, Incorrect MCQs ≈ 500, Correct OSQs ≈ 5000, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.92, OSQ Accuracy ≈ 0.91.
* **MedMCQA:** Correct MCQs ≈ 5500, Incorrect MCQs ≈ 500, Correct OSQs ≈ 4500, Incorrect OSQs ≈ 1000. MCQ Accuracy ≈ 0.92, OSQ Accuracy ≈ 0.82.
* **PIQA:** Correct MCQs ≈ 6800, Incorrect MCQs ≈ 320, Correct OSQs ≈ 5500, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.96, OSQ Accuracy ≈ 0.92.
* **OpenbookQA:** Correct MCQs ≈ 6000, Incorrect MCQs ≈ 500, Correct OSQs ≈ 5000, Incorrect OSQs ≈ 500. MCQ Accuracy ≈ 0.92, OSQ Accuracy ≈ 0.91.
* **Winogrande:** Correct MCQs ≈ 5000, Incorrect MCQs ≈ 1500, Correct OSQs ≈ 3500, Incorrect OSQs ≈ 2000. MCQ Accuracy ≈ 0.77, OSQ Accuracy ≈ 0.64.
### Key Observations
* Claude-3 Opus consistently demonstrates the highest accuracy across all datasets for both MCQs and OSQs.
* GPT-4 generally performs well, but is outperformed by Claude-3 Opus.
* GPT-3.5 shows the lowest accuracy scores, particularly on OSQs.
* Mistral-large performs comparably to GPT-3.5, with slightly better results on some datasets.
* All models struggle with Winogrande, exhibiting lower accuracy scores compared to other datasets.
* MCQ accuracy is generally higher than OSQ accuracy for all models.
### Interpretation
The data suggests a clear hierarchy in performance among the evaluated LLMs. Claude-3 Opus emerges as the most capable model, excelling in both multiple-choice and open-ended question answering. GPT-4 is a strong performer, but falls short of Claude-3 Opus's capabilities. GPT-3.5 and Mistral-large exhibit lower accuracy, indicating limitations in their reasoning and knowledge retention abilities.
The consistent difficulty with the Winogrande dataset suggests that this benchmark poses a unique challenge for all models, potentially due to its reliance on subtle contextual understanding and commonsense reasoning. The higher accuracy scores for MCQs compared to OSQs highlight the models' relative strength in recognizing patterns and selecting from predefined options versus generating coherent and accurate responses to open-ended questions.
The overlaid area charts provide a visual representation of the accuracy trends, allowing for a quick comparison of model performance across different datasets. The differences in area chart heights directly correlate with the accuracy scores, reinforcing the observed performance hierarchy. The data suggests that Claude-3 Opus represents a significant advancement in LLM capabilities, particularly in complex reasoning tasks.
DECODING INTELLIGENCE...