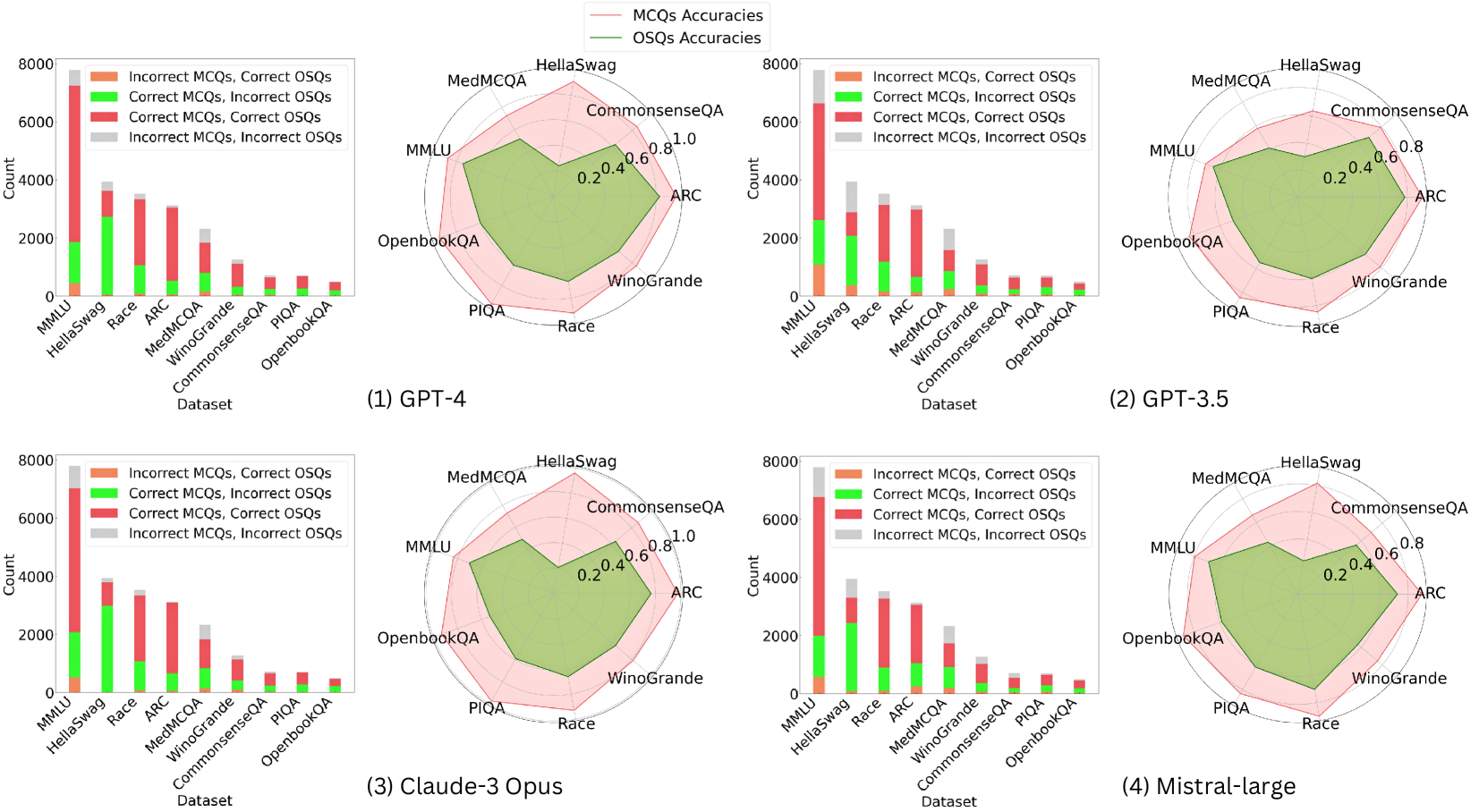
## Radar Charts and Bar Charts: Model Performance Comparison
### Overview
The image contains four radar charts and four bar charts comparing the performance of different AI models (GPT-4, GPT-3.5, Claude-3 Opus, Mistral-large) across multiple datasets. The radar charts visualize accuracy metrics for multiple-choice questions (MCQs) and open-ended short questions (OSQs), while the bar charts show counts of correct/incorrect combinations for each dataset.
### Components/Axes
**Radar Charts**:
- **Axes**: Labeled with datasets (MMLU, HellaSwag, Race, ARC, MedMCQA, WinoGrande, CommonsenseQA, PIQA, OpenbookQA, Race)
- **Legend**:
- Pink: MCQs Accuracies
- Green: OSQs Accuracies
- **Positioning**: Legends in top-right corner; datasets arranged clockwise
**Bar Charts**:
- **X-axis**: Datasets (MMLU, HellaSwag, Race, ARC, MedMCQA, WinoGrande, CommonsenseQA, PIQA, OpenbookQA)
- **Y-axis**: Count (0–8000)
- **Legend**:
- Orange: Incorrect MCQs, Correct OSQs
- Green: Correct MCQs, Incorrect OSQs
- Red: Correct MCQs, Correct OSQs
- Gray: Incorrect MCQs, Incorrect OSQs
- **Positioning**: Legends in top-left corner
### Detailed Analysis
**Radar Charts**:
1. **GPT-4**:
- MCQs (pink) consistently outperform OSQs (green) across all datasets.
- Highest accuracy in CommonsenseQA (MCQs ~0.9, OSQs ~0.7).
- Lowest accuracy in OpenbookQA (MCQs ~0.6, OSQs ~0.4).
2. **GPT-3.5**:
- Similar trend to GPT-4 but with lower overall accuracy.
- MCQs ~0.8–0.9, OSQs ~0.5–0.7 across datasets.
3. **Claude-3 Opus**:
- MCQs ~0.8–0.9, OSQs ~0.6–0.8.
- Strongest performance in ARC (MCQs ~0.9, OSQs ~0.7).
4. **Mistral-large**:
- Highest MCQ accuracy in CommonsenseQA (~0.95).
- OSQs accuracy peaks at ~0.8 in CommonsenseQA.
**Bar Charts**:
1. **GPT-4**:
- MMLU dominates with ~7000 total counts.
- "Correct MCQs, Correct OSQs" (red) is largest segment (~5000).
- "Incorrect MCQs, Correct OSQs" (orange) is smallest (~500).
2. **GPT-3.5**:
- MMLU ~6000 total counts.
- "Correct MCQs, Correct OSQs" ~4500.
- "Incorrect MCQs, Incorrect OSQs" (gray) ~1000.
3. **Claude-3 Opus**:
- MMLU ~5500 total counts.
- "Correct MCQs, Correct OSQs" ~4000.
- "Incorrect MCQs, Correct OSQs" ~800.
4. **Mistral-large**:
- MMLU ~5000 total counts.
- "Correct MCQs, Correct OSQs" ~3500.
- "Incorrect MCQs, Correct OSQs" ~700.
### Key Observations
1. **MCQs vs. OSQs**: MCQs consistently show higher accuracy than OSQs in radar charts (e.g., GPT-4: MCQs ~0.85 vs. OSQs ~0.65).
2. **Dataset Variance**:
- MMLU has the highest counts but lower accuracy in OSQs.
- CommonsenseQA shows the highest accuracy for both MCQs and OSQs.
3. **Model Performance**:
- Mistral-large leads in MCQ accuracy (CommonsenseQA ~0.95).
- GPT-4 has the highest OSQ accuracy (CommonsenseQA ~0.75).
### Interpretation
The data demonstrates that AI models perform better on structured MCQs than open-ended OSQs, likely due to the latter's ambiguity. Mistral-large excels in MCQ accuracy, suggesting specialized training for factual recall, while GPT-4 balances both question types. The bar charts reveal that even "correct" combinations dominate, but OSQs have significant incorrect answers (e.g., GPT-3.5: ~1000 "Incorrect MCQs, Incorrect OSQs" in MMLU). This highlights challenges in handling unstructured tasks across models.