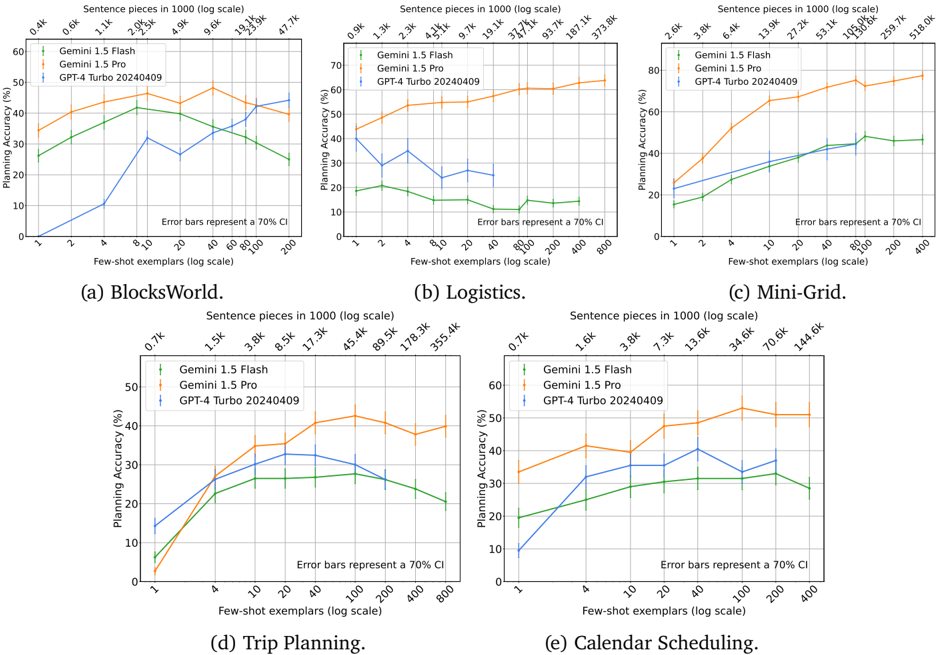
## Chart: Planning Accuracy vs. Few-Shot Exemplars for Different Tasks
### Overview
The image presents a series of five line charts comparing the planning accuracy of three different models (Gemini 1.5 Flash, Gemini 1.5 Pro, and GPT-4 Turbo 20240409) across five different tasks: BlocksWorld, Logistics, Mini-Grid, Trip Planning, and Calendar Scheduling. The x-axis represents the number of few-shot exemplars (log scale), and the y-axis represents the planning accuracy in percentage. Error bars representing a 70% confidence interval are included for each data point.
### Components/Axes
* **Title:** Planning Accuracy vs. Few-Shot Exemplars for Different Tasks
* **X-axis:** Few-shot exemplars (log scale)
* Values: 1, 2, 4, 10, 20, 40, 100, 200, 400, 800
* **Y-axis:** Planning Accuracy (%)
* Values: 0, 10, 20, 30, 40, 50, 60, 70, 80
* **Legend:** Located within each subplot.
* Gemini 1.5 Flash (Green)
* Gemini 1.5 Pro (Blue)
* GPT-4 Turbo 20240409 (Orange)
* **Error Bars:** Represent a 70% Confidence Interval (CI).
* **Subplot Titles:** (a) BlocksWorld, (b) Logistics, (c) Mini-Grid, (d) Trip Planning, (e) Calendar Scheduling
* **Sentence Pieces (log scale):** Displayed above the x-axis on each subplot. The values vary depending on the subplot.
### Detailed Analysis
#### (a) BlocksWorld
* **Sentence pieces in 1000 (log scale):** 0.4k, 0.6k, 1.1k, 2.0k, 2.5k, 4.9k, 9.6k, 19.1k, 23.3k, 47.7k
* **Gemini 1.5 Flash (Green):** Starts at approximately 30% accuracy, dips to around 25% at 10 exemplars, then rises to approximately 40% at 40 exemplars, and decreases to around 30% at 200 exemplars.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 10% accuracy, rises sharply to approximately 35% at 10 exemplars, then decreases to approximately 25% at 200 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 40% accuracy, increases slightly to approximately 45% at 10 exemplars, and remains relatively stable around 45% until 200 exemplars.
#### (b) Logistics
* **Sentence pieces in 1000 (log scale):** 0.9k, 1.3k, 2.3k, 4.2k, 5.1k, 9.7k, 19.1k, 37.7k, 93.7k, 187.1k, 373.8k
* **Gemini 1.5 Flash (Green):** Starts at approximately 20% accuracy and remains relatively flat around 20% across all exemplar values.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 35% accuracy, decreases to approximately 25% at 4 exemplars, then decreases further to approximately 15% at 40 exemplars, and rises slightly to approximately 25% at 400 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 50% accuracy, increases to approximately 60% at 4 exemplars, and remains relatively stable around 60% across all exemplar values.
#### (c) Mini-Grid
* **Sentence pieces in 1000 (log scale):** 2.6k, 3.8k, 6.4k, 13.9k, 27.2k, 53.1k, 105.0k, 130.6k, 259.7k, 518.0k
* **Gemini 1.5 Flash (Green):** Starts at approximately 20% accuracy, increases to approximately 45% at 100 exemplars, and remains relatively stable around 45% until 400 exemplars.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 20% accuracy, increases to approximately 40% at 100 exemplars, and remains relatively stable around 40% until 400 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 60% accuracy, increases to approximately 80% at 10 exemplars, and remains relatively stable around 80% across all exemplar values.
#### (d) Trip Planning
* **Sentence pieces in 1000 (log scale):** 0.7k, 1.5k, 3.8k, 8.5k, 17.3k, 45.4k, 89.5k, 178.3k, 355.4k
* **Gemini 1.5 Flash (Green):** Starts at approximately 5% accuracy, increases to approximately 30% at 20 exemplars, and remains relatively stable around 30% until 400 exemplars.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 5% accuracy, increases to approximately 30% at 20 exemplars, and remains relatively stable around 30% until 400 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 10% accuracy, increases to approximately 40% at 40 exemplars, and remains relatively stable around 40% until 400 exemplars.
#### (e) Calendar Scheduling
* **Sentence pieces in 1000 (log scale):** 0.7k, 1.6k, 3.8k, 7.3k, 13.6k, 34.6k, 70.6k, 144.6k
* **Gemini 1.5 Flash (Green):** Starts at approximately 10% accuracy, increases to approximately 40% at 20 exemplars, and remains relatively stable around 40% until 400 exemplars.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 10% accuracy, increases to approximately 40% at 20 exemplars, and remains relatively stable around 40% until 400 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 20% accuracy, increases to approximately 50% at 20 exemplars, and remains relatively stable around 50% until 400 exemplars.
### Key Observations
* GPT-4 Turbo 20240409 generally outperforms Gemini 1.5 Flash and Gemini 1.5 Pro across all tasks.
* The performance of Gemini 1.5 Flash and Gemini 1.5 Pro is often similar, especially in tasks like Trip Planning and Calendar Scheduling.
* The impact of increasing the number of few-shot exemplars varies across tasks. In some tasks (e.g., Mini-Grid), performance plateaus after a certain number of exemplars, while in others (e.g., Logistics), performance may even decrease with more exemplars for Gemini 1.5 Pro.
* The error bars indicate the variability in performance, with some data points having wider confidence intervals than others.
### Interpretation
The data suggests that GPT-4 Turbo 20240409 is a more robust and accurate model for planning tasks compared to Gemini 1.5 Flash and Gemini 1.5 Pro. The effectiveness of few-shot learning appears to be task-dependent, with some tasks benefiting more from increased exemplars than others. The decrease in performance for Gemini 1.5 Pro in the Logistics task with more exemplars could indicate overfitting or the introduction of noise with additional examples. The error bars highlight the uncertainty in the performance estimates, suggesting that further experimentation may be needed to draw more definitive conclusions. The sentence pieces in 1000 (log scale) likely represent the number of tokens or sub-word units used in the input prompts or training data, providing context for the complexity of each task.