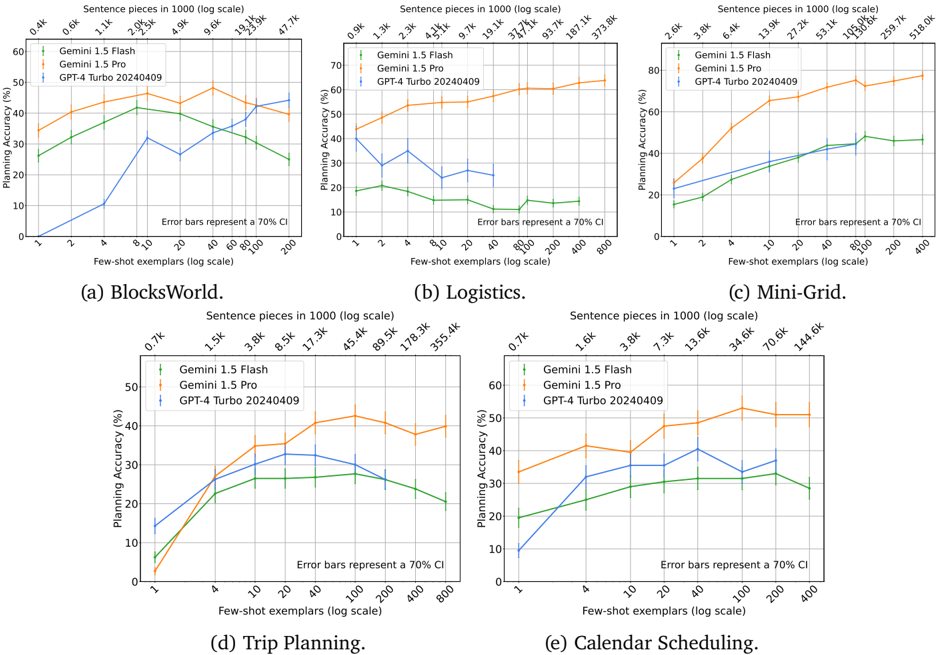
## Charts: Planning Accuracy vs. Few-shot Exemplars
### Overview
The image presents five charts comparing the planning accuracy of different language models (Gemini 1.5 Flash, Gemini 1.5 Pro, and GPT-4 Turbo 20240409) across five different environments: BlocksWorld, Logistics, Mini-Grid, Trip Planning, and Calendar Scheduling. The x-axis of each chart represents the number of few-shot exemplars (on a logarithmic scale), and the y-axis represents the planning accuracy (in percentage). Error bars representing a 70% confidence interval are also shown. The top of each chart displays the sentence pieces in 1000 (log scale).
### Components/Axes
* **X-axis (all charts):** Few-shot exemplars (log scale). Markers are at 2, 4, 8, 16, 32, 64, 128, 256, 512, 1024, 2048.
* **Y-axis (all charts):** Planning Accuracy (%). Scale ranges from approximately 10% to 60%.
* **Models (all charts):**
* Gemini 1.5 Flash (represented by a green line)
* Gemini 1.5 Pro (represented by a blue line)
* GPT-4 Turbo 20240409 (represented by an orange line)
* **Error Bars (all charts):** Represent a 70% confidence interval.
* **Sentence Pieces (all charts):** Displayed at the top of each chart, in 1000 (log scale).
* **Chart Titles:** (a) BlocksWorld, (b) Logistics, (c) Mini-Grid, (d) Trip Planning, (e) Calendar Scheduling.
### Detailed Analysis or Content Details
**Chart (a) BlocksWorld:**
* **Gemini 1.5 Flash (Green):** Starts at approximately 12% accuracy with 2 exemplars, rises to around 45% at 16 exemplars, plateaus around 45-50% from 32 to 2048 exemplars.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 15% accuracy with 2 exemplars, rises to around 55% at 16 exemplars, and plateaus around 55-60% from 32 to 2048 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 18% accuracy with 2 exemplars, rises to around 40% at 16 exemplars, and plateaus around 40-45% from 32 to 2048 exemplars.
* Sentence Pieces: 0.4k, 1.1k, 2.6k, 4.9k, 9.3k, 19.5k, 47.7k
**Chart (b) Logistics:**
* **Gemini 1.5 Flash (Green):** Starts at approximately 10% accuracy with 2 exemplars, rises to around 30% at 64 exemplars, and plateaus around 30-35% from 128 to 2048 exemplars.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 15% accuracy with 2 exemplars, rises to around 50% at 128 exemplars, and plateaus around 50-55% from 256 to 2048 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 20% accuracy with 2 exemplars, rises to around 40% at 64 exemplars, and plateaus around 40-45% from 128 to 2048 exemplars.
* Sentence Pieces: 0.9k, 2.3k, 4.5k, 9.1k, 19.1k, 38.7k, 78.9k, 157k, 313.8k
**Chart (c) Mini-Grid:**
* **Gemini 1.5 Flash (Green):** Starts at approximately 15% accuracy with 2 exemplars, rises to around 40% at 32 exemplars, and plateaus around 40-45% from 64 to 2048 exemplars.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 20% accuracy with 2 exemplars, rises to around 55% at 64 exemplars, and plateaus around 55-60% from 128 to 2048 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 25% accuracy with 2 exemplars, rises to around 45% at 64 exemplars, and plateaus around 45-50% from 128 to 2048 exemplars.
* Sentence Pieces: 2.6k, 6.4k, 13.9k, 27.2k, 53.1k, 104.6k, 259.7k, 518.9k
**Chart (d) Trip Planning:**
* **Gemini 1.5 Flash (Green):** Starts at approximately 10% accuracy with 2 exemplars, rises to around 35% at 16 exemplars, and plateaus around 35-40% from 32 to 2048 exemplars.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 15% accuracy with 2 exemplars, rises to around 50% at 32 exemplars, and plateaus around 50-55% from 64 to 2048 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 20% accuracy with 2 exemplars, rises to around 40% at 32 exemplars, and plateaus around 40-45% from 64 to 2048 exemplars.
* Sentence Pieces: 0.7k, 1.5k, 3.8k, 8.5k, 17.3k, 45.4k, 89.9k, 178.2k
**Chart (e) Calendar Scheduling:**
* **Gemini 1.5 Flash (Green):** Starts at approximately 10% accuracy with 2 exemplars, rises to around 30% at 16 exemplars, and plateaus around 30-35% from 32 to 2048 exemplars.
* **Gemini 1.5 Pro (Blue):** Starts at approximately 15% accuracy with 2 exemplars, rises to around 45% at 32 exemplars, and plateaus around 45-50% from 64 to 2048 exemplars.
* **GPT-4 Turbo 20240409 (Orange):** Starts at approximately 20% accuracy with 2 exemplars, rises to around 40% at 32 exemplars, and plateaus around 40-45% from 64 to 2048 exemplars.
* Sentence Pieces: 0.7k, 1.6k, 3.8k, 7.3k, 13.6k, 34.6k, 70.4k, 144.6k
### Key Observations
* Gemini 1.5 Pro consistently outperforms both Gemini 1.5 Flash and GPT-4 Turbo 20240409 across all environments.
* GPT-4 Turbo 20240409 generally outperforms Gemini 1.5 Flash, especially at lower numbers of exemplars.
* In most environments, the accuracy plateaus after a certain number of exemplars (typically between 32 and 128), indicating diminishing returns from adding more examples.
* The impact of few-shot exemplars varies across environments. Some environments (e.g., Logistics, Mini-Grid) show a more significant improvement with increasing exemplars than others (e.g., BlocksWorld, Calendar Scheduling).
### Interpretation
The data suggests that Gemini 1.5 Pro is the most effective model for planning tasks across the tested environments, followed by GPT-4 Turbo 20240409 and then Gemini 1.5 Flash. The diminishing returns observed with increasing exemplars indicate that there's a limit to how much performance can be improved by simply providing more examples. The varying impact of exemplars across environments suggests that the complexity of the task and the nature of the environment play a role in how effectively few-shot learning can be applied. The sentence pieces data at the top of each chart may indicate the length of the input prompts or the complexity of the language used, but without further context, it's difficult to draw definitive conclusions about its relationship to planning accuracy. The error bars provide a measure of uncertainty, and it's important to consider these when interpreting the differences between models. Overall, the results highlight the importance of model selection and the potential benefits of few-shot learning for planning tasks.