TECHNICAL ASSET FINGERPRINT
a11bf197ad828dd9756b91f3
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
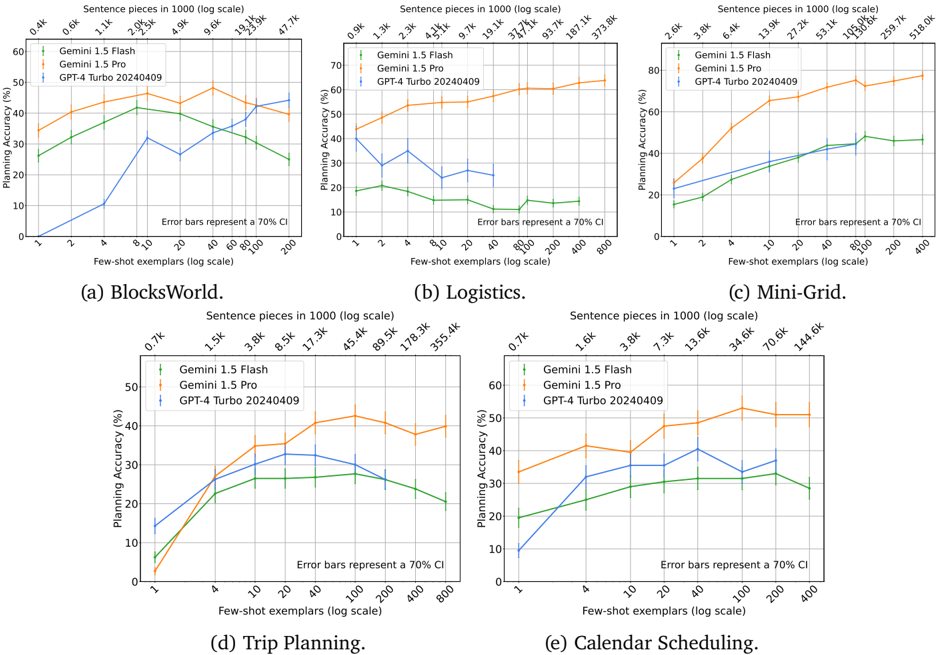
## Line Charts: Planning Accuracy vs. Few-Shot Exemplars for Three AI Models
### Overview
The image contains five line charts, labeled (a) through (e), comparing the "Planning Accuracy (%)" of three large language models across five different planning tasks. The models are Gemini 1.5 Flash (green line), Gemini 1.5 Pro (orange line), and GPT-4 Turbo 20240409 (blue line). Each chart plots accuracy against the number of "Few-shot exemplars" on a logarithmic scale (bottom x-axis). A secondary top x-axis shows the corresponding "Sentence pieces in 1000 (log scale)". Error bars represent a 70% confidence interval (CI).
### Components/Axes
* **Common Elements (All Charts):**
* **Y-axis:** "Planning Accuracy (%)". Scale ranges from 0 to 60 or 70, depending on the chart.
* **Bottom X-axis:** "Few-shot exemplars (log scale)". Values are powers of 2 (e.g., 1, 2, 4, 8, 10, 20, 40, 80, 100, 200, 400, 800).
* **Top X-axis:** "Sentence pieces in 1000 (log scale)". Values are specific to each task and increase with the number of exemplars.
* **Legend:** Located in the top-left corner of each chart. Lists the three models with corresponding line colors and markers:
* Green line with circle markers: `Gemini 1.5 Flash`
* Orange line with circle markers: `Gemini 1.5 Pro`
* Blue line with circle markers: `GPT-4 Turbo 20240409`
* **Annotation:** Text in the bottom-right corner of each chart: "Error bars represent a 70% CI".
* **Individual Chart Titles (Subplot Labels):**
* (a) BlocksWorld.
* (b) Logistics.
* (c) Mini-Grid.
* (d) Trip Planning.
* (e) Calendar Scheduling.
### Detailed Analysis
#### (a) BlocksWorld
* **Trend Verification:**
* **Gemini 1.5 Pro (Orange):** Slopes upward, peaks around 40-80 exemplars, then slightly declines.
* **Gemini 1.5 Flash (Green):** Slopes upward to a peak at ~20 exemplars, then declines sharply.
* **GPT-4 Turbo (Blue):** Slopes upward, with a notable dip at 10 exemplars, then continues rising.
* **Data Points (Approximate Accuracy %):**
* **@1 Exemplar:** Pro ~35%, Flash ~25%, GPT-4 ~0%.
* **@Peak (Pro):** ~48% at 40 exemplars.
* **@Peak (Flash):** ~42% at 20 exemplars.
* **@800 Exemplars:** Pro ~42%, Flash ~25%, GPT-4 ~40%.
* **Top X-axis (Sentence pieces):** Ranges from 0.4k (at 1 exemplar) to 42.7k (at 800 exemplars).
#### (b) Logistics
* **Trend Verification:**
* **Gemini 1.5 Pro (Orange):** Strong, consistent upward trend.
* **Gemini 1.5 Flash (Green):** Relatively flat, low performance with slight fluctuations.
* **GPT-4 Turbo (Blue):** Erratic. Rises to a peak at 4 exemplars, then declines and fluctuates.
* **Data Points (Approximate Accuracy %):**
* **@1 Exemplar:** Pro ~42%, Flash ~18%, GPT-4 ~20%.
* **@Peak (Pro):** ~65% at 800 exemplars.
* **@Peak (Flash):** ~20% at 2-4 exemplars.
* **@Peak (GPT-4):** ~35% at 4 exemplars.
* **@800 Exemplars:** Pro ~65%, Flash ~12%, GPT-4 ~15%.
* **Top X-axis (Sentence pieces):** Ranges from 0.9k to 373.8k.
#### (c) Mini-Grid
* **Trend Verification:**
* **Gemini 1.5 Pro (Orange):** Very strong, smooth upward trend, plateauing at high exemplar counts.
* **Gemini 1.5 Flash (Green):** Steady upward trend, plateauing around 40-80 exemplars.
* **GPT-4 Turbo (Blue):** Steady upward trend, closely follows Flash but slightly lower.
* **Data Points (Approximate Accuracy %):**
* **@1 Exemplar:** Pro ~25%, Flash ~15%, GPT-4 ~22%.
* **@Peak (Pro):** ~75% at 200-400 exemplars.
* **@Peak (Flash):** ~45% at 80-200 exemplars.
* **@400 Exemplars:** Pro ~75%, Flash ~45%, GPT-4 ~42%.
* **Top X-axis (Sentence pieces):** Ranges from 2.6k to 518.0k.
#### (d) Trip Planning
* **Trend Verification:**
* **Gemini 1.5 Pro (Orange):** Upward trend, peaks around 40-100 exemplars, then declines.
* **Gemini 1.5 Flash (Green):** Upward trend to a peak at 20-40 exemplars, then declines.
* **GPT-4 Turbo (Blue):** Upward trend, peaks around 20-40 exemplars, then declines.
* **Data Points (Approximate Accuracy %):**
* **@1 Exemplar:** Pro ~3%, Flash ~6%, GPT-4 ~14%.
* **@Peak (Pro):** ~42% at 40 exemplars.
* **@Peak (Flash):** ~27% at 20 exemplars.
* **@Peak (GPT-4):** ~32% at 20 exemplars.
* **@800 Exemplars:** Pro ~39%, Flash ~20%, GPT-4 ~20%.
* **Top X-axis (Sentence pieces):** Ranges from 0.7k to 355.4k.
#### (e) Calendar Scheduling
* **Trend Verification:**
* **Gemini 1.5 Pro (Orange):** Upward trend, peaks around 40-100 exemplars, then slightly declines.
* **Gemini 1.5 Flash (Green):** Gradual upward trend, peaks around 100-200 exemplars.
* **GPT-4 Turbo (Blue):** Upward trend to a peak at 20 exemplars, then declines.
* **Data Points (Approximate Accuracy %):**
* **@1 Exemplar:** Pro ~33%, Flash ~19%, GPT-4 ~9%.
* **@Peak (Pro):** ~53% at 40 exemplars.
* **@Peak (Flash):** ~34% at 100 exemplars.
* **@Peak (GPT-4):** ~40% at 20 exemplars.
* **@400 Exemplars:** Pro ~50%, Flash ~29%, GPT-4 ~30%.
* **Top X-axis (Sentence pieces):** Ranges from 0.7k to 144.6k.
### Key Observations
1. **Model Performance Hierarchy:** Gemini 1.5 Pro (orange) consistently achieves the highest or near-highest planning accuracy across all five tasks, especially as the number of exemplars increases.
2. **Task Difficulty:** The tasks show varying levels of difficulty. "Logistics" and "Mini-Grid" allow for higher peak accuracies (up to ~65% and ~75% respectively), while "BlocksWorld" and "Trip Planning" peak at lower accuracies (~48% and ~42%).
3. **Diminishing Returns:** For most models and tasks, accuracy improves with more few-shot exemplars but eventually plateaus or even declines, suggesting a point of diminishing returns or potential overfitting.
4. **Gemini 1.5 Flash Variability:** The performance of Gemini 1.5 Flash (green) is more variable. It performs relatively well in "BlocksWorld" and "Mini-Grid" but poorly in "Logistics". It often peaks at a lower number of exemplars than Pro.
5. **GPT-4 Turbo Performance:** GPT-4 Turbo (blue) is competitive, often performing similarly to or better than Gemini 1.5 Flash, but generally below Gemini 1.5 Pro. Its performance curve is sometimes less smooth (e.g., the dip in BlocksWorld).
### Interpretation
This set of charts provides a comparative benchmark of planning capabilities for three advanced AI models. The data suggests that **Gemini 1.5 Pro is the most robust and capable planner** among the three across diverse domains, benefiting significantly from increased context (more exemplars and sentence pieces). The consistent upward trend for Pro indicates it effectively utilizes in-context learning for planning tasks.
The **dual x-axes reveal a correlation**: tasks requiring more sentence pieces (context) to represent the same number of exemplars (like Logistics and Mini-Grid) also allow for higher potential accuracy, implying that the complexity of the planning problem and the model's capacity to handle long contexts are key factors.
The **performance gap between Pro and Flash** highlights differences within the same model family, likely due to model size and capacity. The **variability in Flash's and GPT-4 Turbo's performance** across tasks suggests their planning abilities are more sensitive to the specific structure and rules of the domain (e.g., the logistics task appears particularly challenging for Flash).
Overall, the charts demonstrate that state-of-the-art LLMs can perform structured planning tasks with moderate to good accuracy, and their performance is strongly influenced by both the model architecture and the amount of provided in-context examples. The results are a snapshot of model capabilities as of early 2024 (based on the GPT-4 Turbo date).
DECODING INTELLIGENCE...