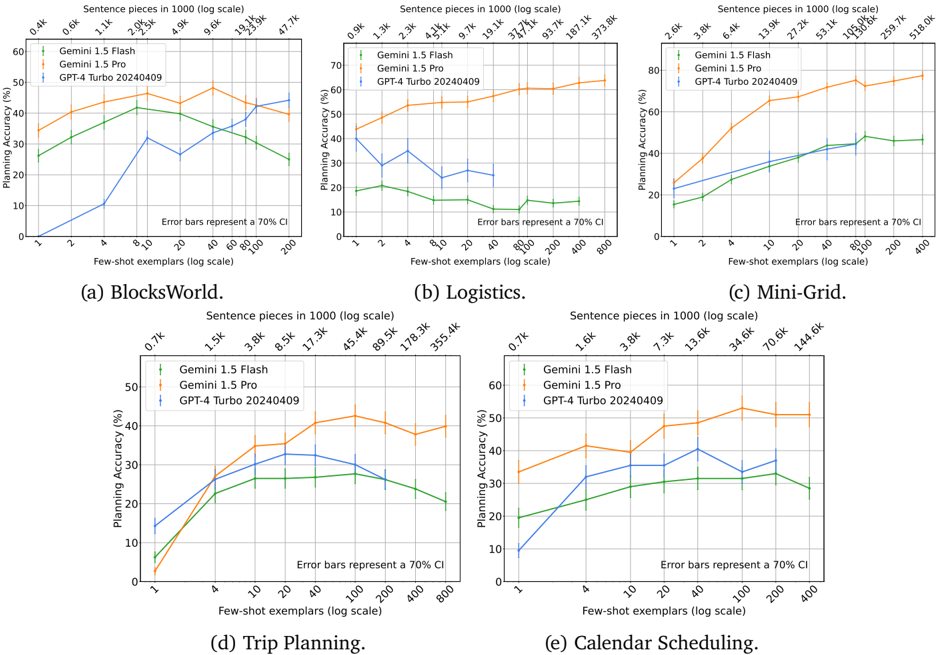
## Line Charts: Planning Accuracy vs Few-Shot Exemplars Across Tasks
### Overview
The image contains five line charts comparing the planning accuracy of three AI models (Gemini 1.5 Flash, Gemini 1.5 Pro, GPT-4 Turbo 20240409) across different tasks (BlocksWorld, Logistics, Mini-Grid, Trip Planning, Calendar Scheduling). Each chart plots accuracy (%) against few-shot exemplars (log scale) with 70% confidence interval error bars.
### Components/Axes
- **X-axis**: "Few-shot exemplars (log scale)" ranging from 1 to 800 exemplars (logarithmic scale)
- **Y-axis**: "Planning Accuracy (%)" ranging from 0% to 80% (linear scale)
- **Legends**: Positioned in top-left corner of each chart, with:
- Green line: Gemini 1.5 Flash
- Orange line: Gemini 1.5 Pro
- Blue line: GPT-4 Turbo 20240409
- **Error Bars**: Represent 70% confidence intervals (CI)
### Detailed Analysis
#### (a) BlocksWorld
- **Trend**: Gemini 1.5 Pro (orange) maintains highest accuracy (35-45%), followed by Gemini 1.5 Flash (green: 25-40%), with GPT-4 Turbo (blue) showing erratic performance (10-35%).
- **Key Data Points**:
- At 10 exemplars: Gemini 1.5 Pro ≈40%, Gemini 1.5 Flash ≈35%, GPT-4 Turbo ≈30%
- At 200 exemplars: Gemini 1.5 Pro ≈45%, Gemini 1.5 Flash ≈30%, GPT-4 Turbo ≈40%
#### (b) Logistics
- **Trend**: Gemini 1.5 Pro dominates (50-70%), Gemini 1.5 Flash (15-25%), GPT-4 Turbo (20-40%).
- **Key Data Points**:
- At 10 exemplars: Gemini 1.5 Pro ≈55%, Gemini 1.5 Flash ≈20%, GPT-4 Turbo ≈30%
- At 200 exemplars: Gemini 1.5 Pro ≈65%, Gemini 1.5 Flash ≈15%, GPT-4 Turbo ≈45%
#### (c) Mini-Grid
- **Trend**: Gemini 1.5 Pro (60-80%), Gemini 1.5 Flash (30-50%), GPT-4 Turbo (40-60%).
- **Key Data Points**:
- At 10 exemplars: Gemini 1.5 Pro ≈60%, Gemini 1.5 Flash ≈30%, GPT-4 Turbo ≈40%
- At 200 exemplars: Gemini 1.5 Pro ≈75%, Gemini 1.5 Flash ≈45%, GPT-4 Turbo ≈55%
#### (d) Trip Planning
- **Trend**: Gemini 1.5 Pro (30-50%), Gemini 1.5 Flash (20-40%), GPT-4 Turbo (25-45%).
- **Key Data Points**:
- At 10 exemplars: Gemini 1.5 Pro ≈35%, Gemini 1.5 Flash ≈25%, GPT-4 Turbo ≈30%
- At 200 exemplars: Gemini 1.5 Pro ≈45%, Gemini 1.5 Flash ≈35%, GPT-4 Turbo ≈40%
#### (e) Calendar Scheduling
- **Trend**: Gemini 1.5 Pro (40-60%), Gemini 1.5 Flash (20-40%), GPT-4 Turbo (30-50%).
- **Key Data Points**:
- At 10 exemplars: Gemini 1.5 Pro ≈40%, Gemini 1.5 Flash ≈20%, GPT-4 Turbo ≈30%
- At 200 exemplars: Gemini 1.5 Pro ≈55%, Gemini 1.5 Flash ≈35%, GPT-4 Turbo ≈45%
### Key Observations
1. **Model Performance**: Gemini 1.5 Pro consistently outperforms other models across all tasks and exemplar counts.
2. **Task Complexity**: Logistics and Mini-Grid show highest absolute accuracy, while BlocksWorld and Trip Planning have lower baselines.
3. **Error Bar Variability**: GPT-4 Turbo exhibits larger error bars (wider 70% CI), indicating less reliable performance.
4. **Scaling Behavior**: All models show improved performance with more exemplars, but diminishing returns after ~100 exemplars.
### Interpretation
The data demonstrates that Gemini 1.5 Pro exhibits superior few-shot learning capabilities across diverse planning tasks, maintaining higher accuracy and reliability (narrower error bars) compared to other models. The Logistics and Mini-Grid tasks appear more amenable to AI planning, achieving >60% accuracy even with minimal exemplars. GPT-4 Turbo's performance is inconsistent, suggesting potential task-specific limitations or training data gaps. The logarithmic scaling of exemplars highlights that most gains occur in the early stages of few-shot learning, with diminishing returns at higher exemplar counts. This pattern suggests that task-specific fine-tuning or hybrid approaches might be necessary for optimal performance in complex planning scenarios.