TECHNICAL ASSET FINGERPRINT
a1369a14d2e4eaa50f4bfd08
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
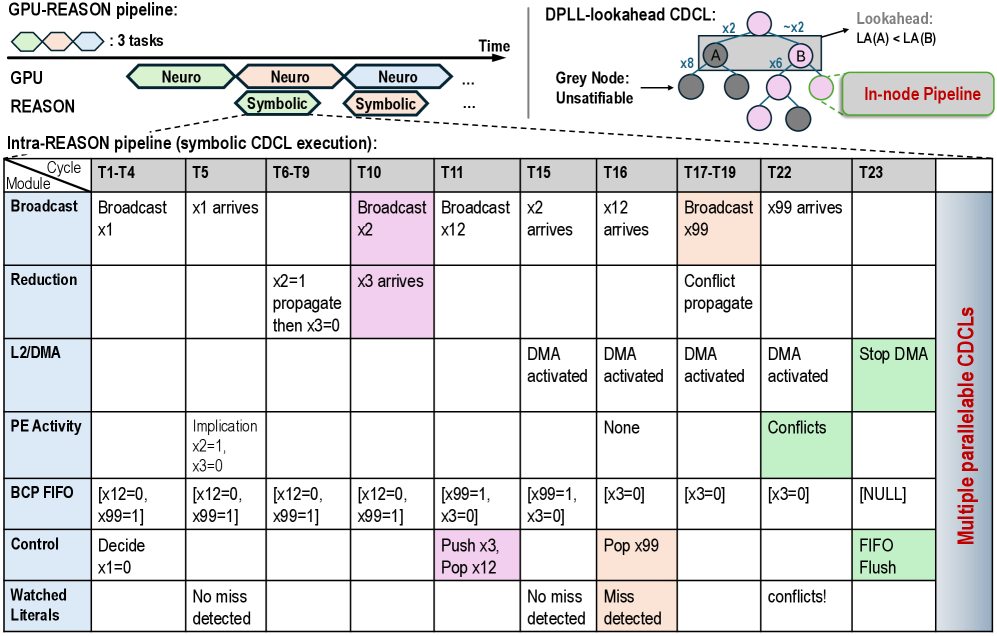
## Diagram: GPU-REASON and Intra-REASON Pipeline for Symbolic CDCL Execution
### Overview
This image is a technical diagram illustrating a two-level pipeline architecture for a system named "REASON." The top section depicts a high-level "GPU-REASON pipeline" that interleaves "Neuro" and "Symbolic" tasks over time. The bottom section provides a detailed timing diagram for the "Intra-REASON pipeline," specifically focusing on the execution of a symbolic CDCL (Conflict-Driven Clause Learning) solver. The diagram uses color-coding, tables, and flowcharts to explain the parallel and pipelined operations.
### Components/Axes
**Top Section - GPU-REASON Pipeline:**
* **Timeline:** A horizontal arrow labeled "Time" indicates the progression of tasks.
* **Tasks:** Three interlocking hexagons represent "3 tasks."
* **Pipeline Stages:** Two rows labeled "GPU" and "REASON."
* The "GPU" row contains a sequence of green hexagons labeled "Neuro."
* The "REASON" row contains a sequence of orange hexagons labeled "Symbolic," which are staggered to overlap with the "Neuro" tasks.
* **DPLL-lookahead CDCL Diagram (Top Right):**
* A small flowchart showing nodes (circles) connected by arrows.
* **Labels:** "Lookahead: LA(A) < LA(B)", "x2", "~x2", "x8", "x6".
* **Node Colors:** Grey nodes are labeled "Grey Node: Unsatifiable." Pink and light purple nodes are present.
* **Highlighted Region:** A green box labeled "In-node Pipeline" encloses two nodes (A and B).
**Bottom Section - Intra-REASON Pipeline (Symbolic CDCL Execution):**
This is a large table with the following structure:
* **Columns (Cycles):** T1-T4, T5, T6-T9, T10, T11, T15, T16, T17-T19, T22, T23.
* **Rows (Modules):**
1. **Broadcast**
2. **Reduction**
3. **L2/DMA**
4. **PE Activity**
5. **BCP FIFO**
6. **Control**
7. **Watched Literals**
* **Right-Side Label:** A vertical red label reads "Multiple parallel CDCLs," indicating the table represents one instance of several running in parallel.
* **Color-Coding:** Cells are shaded in light blue, pink, orange, and green to denote different types of operations or states.
### Detailed Analysis
**GPU-REASON Pipeline Flow:**
The diagram shows a pipelined execution where "Neuro" tasks (likely neural network inference) on the GPU are interleaved with "Symbolic" reasoning tasks. This suggests a heterogeneous computing approach where different hardware units handle specialized tasks in a coordinated, overlapping manner to maximize utilization.
**Intra-REASON Pipeline Table - Cycle-by-Cycle Breakdown:**
| Module | T1-T4 | T5 | T6-T9 | T10 | T11 | T15 | T16 | T17-T19 | T22 | T23 |
| :----------- | :----------------------------- | :--------------------- | :----------------------------- | :------------- | :--------------------------- | :------------- | :------------- | :-------------------- | :------------- | :------------- |
| **Broadcast**| Broadcast x1 | x1 arrives | | **Broadcast x2** | Broadcast x12 | x2 arrives | x12 arrives | **Broadcast x99** | x99 arrives | |
| **Reduction**| | | x2=1 propagate then x3=0 | **x3 arrives** | | | | Conflict propagate | | |
| **L2/DMA** | | | | | | DMA activated | DMA activated | DMA activated | DMA activated | **Stop DMA** |
| **PE Activity**| | Implication x2=1, x3=0 | | | | None | | | **Conflicts** | |
| **BCP FIFO** | [x12=0, x99=1] | [x12=0, x99=1] | [x12=0, x99=1] | [x12=0, x99=1] | [x99=1, x3=0] | [x99=1, x3=0] | [x3=0] | [x3=0] | [x3=0] | [NULL] |
| **Control** | Decide x1=0 | | | | **Push x3, Pop x12** | | **Pop x99** | | | **FIFO Flush** |
|**Watched Literals**| | No miss detected | | | | No miss detected| Miss detected | | conflicts! | |
**Key Data Points & Trends from the Table:**
* **Broadcast Trend:** The broadcast module sequentially sends variables (x1, x2, x12, x99) into the pipeline. Their arrivals are staggered across cycles (x1 at T5, x2 at T15, x12 at T16, x99 at T22).
* **Reduction & Control Flow:** A reduction operation propagates an implication (x2=1 leads to x3=0) between T6-T9. The Control module later pushes x3 and pops x12 at T11, and pops x99 at T16.
* **Memory (L2/DMA) Activity:** DMA (Direct Memory Access) is activated from T15 to T22, suggesting data movement between processing elements and memory during this phase, and is explicitly stopped at T23.
* **Processing Element (PE) Activity:** The PE shows implication activity early on (T5), is idle ("None") at T16, and detects "Conflicts" at T22.
* **BCP FIFO State:** The Boolean Constraint Propagation FIFO holds a queue of literal assignments. Its state evolves from holding `[x12=0, x99=1]` to eventually being flushed to `[NULL]` at T23.
* **Watched Literals:** This mechanism, used for efficient clause monitoring, reports "No miss detected" at T5 and T15, a "Miss detected" at T16, and "conflicts!" at T22, aligning with the PE's conflict detection.
### Key Observations
1. **Pipelining and Parallelism:** The core theme is overlapping different phases of computation (Broadcast, Reduction, DMA, PE Activity) across cycles to achieve parallelism. The "Multiple parallel CDCLs" label confirms this is a scalable design.
2. **Color-Coded Semantics:** Pink cells (e.g., "Broadcast x2", "Push x3, Pop x12") seem to indicate control or data movement initiation. Orange cells (e.g., "Broadcast x99", "Miss detected") may highlight critical path or event-driven actions. Green cells (DMA rows, "Conflicts", "FIFO Flush") likely denote hardware-accelerated or terminal operations.
3. **Synchronization Points:** The pipeline shows clear synchronization. For example, the "Conflict propagate" in Reduction (T17-T19) and "Conflicts" in PE Activity (T22) are followed by a "FIFO Flush" in Control (T23), indicating a resolution or restart procedure.
4. **Data Flow:** The BCP FIFO acts as a central communication channel between modules, its contents changing as variables are decided, propagated, and popped.
### Interpretation
This diagram details the microarchitecture of a specialized hardware accelerator for symbolic reasoning, specifically for SAT solving using the CDCL algorithm. It demonstrates how a high-level neuro-symbolic pipeline (GPU-REASON) is supported by a deeply pipelined, parallel execution engine at the lower level (Intra-REASON).
The data suggests a system designed for high throughput. By having multiple CDCL instances run in parallel and by meticulously scheduling the stages of a single CDCL instance (broadcast, propagate, memory access, conflict analysis) to overlap, the architecture minimizes idle time for processing elements. The progression from "No miss detected" to "Miss detected" and finally to "conflicts!" in the Watched Literals module illustrates the solver's journey from propagation to encountering a contradiction, which is the core mechanism for guiding the search in CDCL.
The "DPLL-lookahead CDCL" inset hints that the system uses an advanced variant of CDCL with lookahead heuristics (comparing LA(A) and LA(B)) to make branching decisions, which is computationally expensive but can dramatically reduce the search space. The "In-node Pipeline" suggests that even within a single decision node, further pipelining occurs.
In essence, the image reveals a hardware-software co-design aimed at accelerating the symbolic reasoning component of AI systems, making it feasible to integrate deep logical inference with neural network processing in a unified, efficient pipeline.
DECODING INTELLIGENCE...