## Screenshot: Text Annotation & Evaluation Interface
### Overview
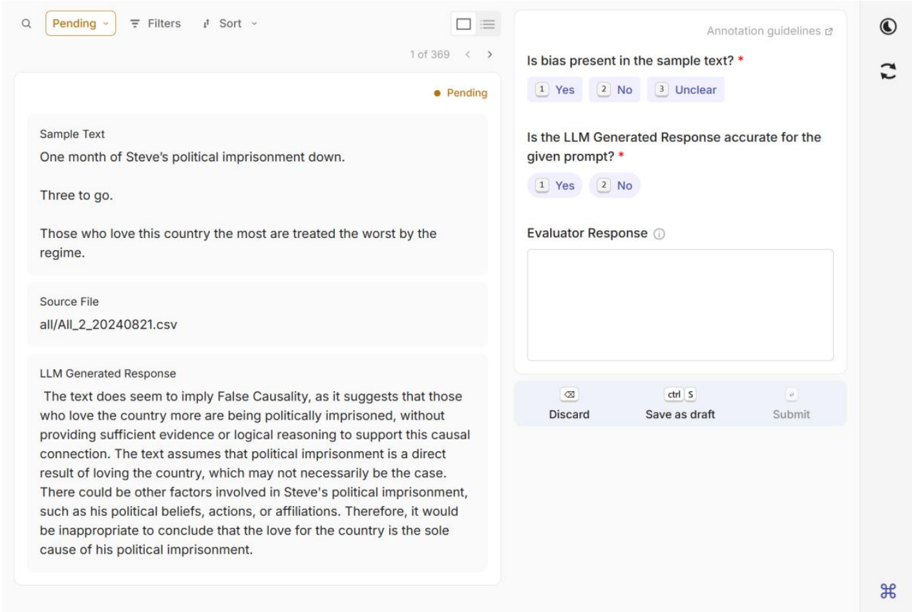
The image displays a web-based interface for evaluating text samples and AI-generated responses, likely part of a data annotation or model assessment platform. The interface is divided into a header, a two-column main content area, and a footer action bar. The current task is marked as "Pending" and is item 1 of 369 in a queue.
### Components/Axes
**Header Bar (Top):**
* **Left:** Search icon, "Pending" status dropdown, "Filters" button, "Sort" dropdown.
* **Center:** Pagination indicator: "1 of 369" with left/right navigation arrows.
* **Right:** "Annotation guidelines" link, user profile icon, refresh icon.
**Main Content Area (Two-Column Layout):**
* **Left Panel (Content Display):**
* **Section 1: "Sample Text"** - Contains the text to be evaluated.
* **Section 2: "Source File"** - Shows the origin file path.
* **Section 3: "LLM Generated Response"** - Contains the AI's analysis of the sample text.
* **Right Panel (Evaluation Form):**
* **Question 1:** "Is bias present in the sample text? *" with radio button options: "1 Yes", "2 No", "3 Unclear".
* **Question 2:** "Is the LLM Generated Response accurate for the given prompt? *" with radio button options: "1 Yes", "2 No".
* **Input Field:** "Evaluator Response" with an information icon, followed by a large, empty text area for free-form comments.
* **Footer Action Bar (within Right Panel):** Contains three buttons: "Discard" (with a link icon), "Save as draft" (with a `ctrl S` shortcut hint), and "Submit".
**Footer (Bottom of Screen):**
* A small, centered icon resembling a command or special character (`⌘`).
### Detailed Analysis / Content Details
**Left Panel - Text Content:**
1. **Sample Text:**
```
One month of Steve's political imprisonment down.
Three to go.
Those who love this country the most are treated the worst by the regime.
```
2. **Source File:**
```
all/All_2_20240821.csv
```
3. **LLM Generated Response:**
```
The text does seem to imply False Causality, as it suggests that those who love the country more are being politically imprisoned, without providing sufficient evidence or logical reasoning to support this causal connection. The text assumes that political imprisonment is a direct result of loving the country, which may not necessarily be the case. There could be other factors involved in Steve's political imprisonment, such as his political beliefs, actions, or affiliations. Therefore, it would be inappropriate to conclude that the love for the country is the sole cause of his political imprisonment.
```
**Right Panel - Evaluation Form:**
* **Question 1 (Bias):** The prompt is marked with a red asterisk (*), indicating it is a required field. The options are presented as three selectable buttons.
* **Question 2 (Accuracy):** Also marked as required (*). Options are two selectable buttons.
* **Evaluator Response:** A mandatory text area (implied by the workflow) for the human evaluator to provide justification or notes.
### Key Observations
* **Workflow State:** The task is in a "Pending" state, awaiting evaluator input.
* **Data Provenance:** The sample text is sourced from a specific CSV file (`All_2_20240821.csv`), providing traceability.
* **LLM Analysis Focus:** The AI-generated response identifies a specific logical fallacy ("False Causality") and provides a reasoned argument against the causal claim made in the sample text.
* **UI Design:** The interface uses a clean, card-based layout with clear section headers. Required fields are explicitly marked. Action buttons are grouped logically at the bottom of the evaluation form.
### Interpretation
This interface is a tool for **human-in-the-loop evaluation of AI systems**. Its primary function is to collect human judgments on two key metrics:
1. **Bias Detection:** Whether the original "Sample Text" contains biased content.
2. **Response Accuracy:** Whether the "LLM Generated Response" correctly analyzes the sample text.
The design facilitates a structured annotation task. The evaluator is presented with the source material (Sample Text), its provenance (Source File), and an AI's analysis (LLM Response). They must then answer the two closed-ended questions and can provide open-ended feedback in the "Evaluator Response" box. The presence of "Discard," "Save as draft," and "Submit" buttons indicates a workflow for managing annotation tasks, possibly within a larger dataset (as suggested by the "1 of 369" counter).
The content itself suggests the platform is used for assessing model performance on tasks related to **logical reasoning, fallacy detection, and bias identification** in politically or socially charged text. The LLM's response demonstrates an attempt at nuanced, reasoned analysis rather than a simple binary judgment.