TECHNICAL ASSET FINGERPRINT
a1c9b0deade0c6b53e0315d6
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
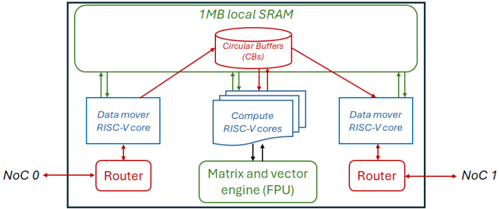
## System Architecture Diagram: Multi-Core RISC-V Processor with Shared Memory
### Overview
The image is a technical block diagram illustrating the architecture of a multi-core processing system. It depicts a centralized shared memory pool connected to multiple processing cores and external network interfaces via routers. The design emphasizes parallel data movement and computation with specialized hardware units.
### Components/Axes
The diagram is organized into several key functional blocks, connected by arrows indicating data flow directions.
**1. Top Region: Shared Memory**
* **Component:** A large rectangular block labeled **"1MB local SRAM"**.
* **Sub-component:** Inside the SRAM block, a cylindrical icon is labeled **"Circular Buffers (CBs)"**.
* **Connections:** Multiple bidirectional arrows connect the Circular Buffers to the processing cores below.
**2. Middle Region: Processing Cores**
* **Left Data Mover:** A rectangular block labeled **"Data mover RISC-V core"**. It has a bidirectional arrow connecting to the Circular Buffers above and a bidirectional arrow connecting to a Router below.
* **Center Compute Cluster:** A stack of three rectangular blocks, with the top one labeled **"Compute RISC-V cores"**. This cluster has multiple bidirectional arrows connecting to the Circular Buffers above and a bidirectional arrow connecting to the engine below.
* **Right Data Mover:** A rectangular block identical to the left one, labeled **"Data mover RISC-V core"**. It connects similarly to the Circular Buffers above and a Router below.
**3. Bottom Region: Accelerator and Network Interfaces**
* **Specialized Engine:** A rectangular block below the compute cores labeled **"Matrix and vector engine (FPU)"**. It has a bidirectional arrow connecting to the Compute RISC-V cores above.
* **Left Network Interface:** A rectangular block labeled **"Router"**. It has a bidirectional arrow connecting to the left Data mover core above and a bidirectional arrow pointing left to an external label **"NoC 0"**.
* **Right Network Interface:** A rectangular block labeled **"Router"**. It has a bidirectional arrow connecting to the right Data mover core above and a bidirectional arrow pointing right to an external label **"NoC 1"**.
**4. External Labels**
* **NoC 0:** Located to the far left, connected to the left Router.
* **NoC 1:** Located to the far right, connected to the right Router.
* "NoC" likely stands for Network-on-Chip.
### Detailed Analysis
The diagram defines a clear data flow and functional hierarchy:
* **Memory Hierarchy:** The **1MB local SRAM** acts as a shared, low-latency memory pool for all on-chip cores. The **Circular Buffers (CBs)** within it suggest a structured, queue-based mechanism for managing data streams between producers (e.g., data movers, network) and consumers (e.g., compute cores).
* **Processing Elements:**
* **Data Mover RISC-V Cores (2):** These are specialized cores positioned at the memory's periphery. Their primary role is to shuttle data between the external Network-on-Chip (NoC 0/1) and the internal Circular Buffers in SRAM, offloading this task from the compute cores.
* **Compute RISC-V Cores (3+):** A cluster of general-purpose cores located centrally. They fetch data from and write results back to the Circular Buffers in SRAM. They also offload specialized mathematical operations to the FPU.
* **Matrix and Vector Engine (FPU):** A dedicated hardware accelerator for floating-point, matrix, and vector operations, directly servicing the compute cores to accelerate linear algebra and signal processing workloads.
* **Communication Paths:**
* **Internal:** All communication with the shared SRAM is mediated through the Circular Buffers. The compute cores have a direct, dedicated link to the FPU.
* **External:** The system interfaces with the broader chip or system via two independent Network-on-Chip (NoC) links, each managed by a dedicated Router and serviced by its own Data Mover core. This allows for concurrent input and output data streams.
### Key Observations
1. **Symmetry and Specialization:** The architecture is symmetric around the central compute cluster, with dedicated data mover cores and routers for each external NoC link. This promotes balanced I/O bandwidth.
2. **Decoupled Data Movement:** The explicit separation of "Data mover" cores from "Compute" cores is a critical design choice. It allows computation and data transfer to overlap (hide latency), improving overall system throughput.
3. **Structured Communication:** The use of **Circular Buffers** in shared SRAM implies a producer-consumer model for data flow, which is efficient for streaming data processing and helps manage synchronization between cores.
4. **Scalability Hint:** The depiction of multiple stacked blocks for "Compute RISC-V cores" suggests the design is scalable, with the number of compute cores being a variable parameter.
### Interpretation
This diagram represents a **heterogeneous system-on-chip (SoC) architecture optimized for data-parallel, compute-intensive workloads** such as signal processing, machine learning inference, or scientific computing.
The design philosophy centers on **efficiency through specialization and parallelism**:
* **Peircean Investigation:** The sign (the diagram) represents an iconic architecture where form follows function. The spatial layout mirrors the data flow: external data enters from the sides (NoC), is staged in the top memory (SRAM/CBs), processed in the center (Compute cores + FPU), and results exit via the same side paths. This visual flow iconically represents the actual data processing pipeline.
* **Why it matters:** By offloading data movement to dedicated cores and complex math to a specialized FPU, the general-purpose compute cores are freed to focus on control logic and task scheduling. This leads to higher performance and energy efficiency compared to a homogeneous multi-core design for the target workloads.
* **Notable Anomaly/Strength:** The presence of **two independent NoC links with dedicated data movers** is a significant feature. It suggests the system is designed for high-throughput, full-duplex communication, possibly to handle simultaneous high-bandwidth input (e.g., sensor data) and output (e.g., processed results) streams without contention. This is a key indicator of its target application in real-time data processing systems.
DECODING INTELLIGENCE...