TECHNICAL ASSET FINGERPRINT
a1e2242df593927714a7bb06
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: nemotron-free VERSION 1
RUNTIME: free/nvidia/nemotron-nano-12b-v2-vl:free
INTEL_VERIFIED
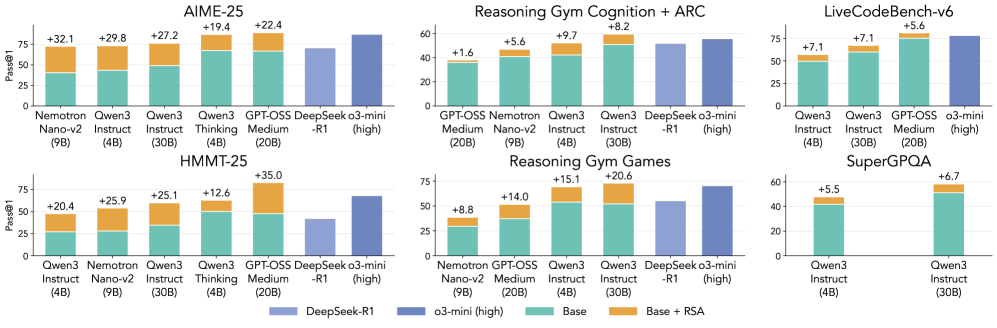
# Model Performance Comparison Across Benchmarks
## Chart Overview
This bar chart compares the performance of various AI models across multiple benchmarks, measured by **Pass@1** (percentage of correct answers). The chart is segmented by **benchmark groups** (e.g., AIME-25, Reasoning Gym Cognition + ARC) and **models** (e.g., Nemotron Nano-v2, Qwen3 Instruct). Each bar is further segmented into **components** (Base, Base + RSA, DeepSeek-R1, o3-mini high), with colors mapped to these components via a legend at the bottom.
---
## Key Components
### **Legend**
- **Base**: Green (solid)
- **Base + RSA**: Orange (solid)
- **DeepSeek-R1**: Blue (solid)
- **o3-mini (high)**: Dark Blue (solid)
**Legend Position**: Bottom of the chart.
---
## Axes
- **X-axis**: Models (e.g., Nemotron Nano-v2, Qwen3 Instruct, GPT-OSS Medium, DeepSeek-R1, o3-mini high).
- **Y-axis**: Pass@1 (percentage, 0–100%).
---
## Benchmark Groups and Data
### **1. AIME-25**
- **Models and Pass@1**:
- **Nemotron Nano-v2 (9B)**: +32.1% (Base: 32.1%, Base + RSA: 29.8%, DeepSeek-R1: 27.2%, o3-mini high: 22.4%)
- **Qwen3 Instruct (4B)**: +27.2% (Base: 27.2%, Base + RSA: 25.1%, DeepSeek-R1: 22.4%, o3-mini high: 19.4%)
- **Qwen3 Instruct (30B)**: +19.4% (Base: 19.4%, Base + RSA: 17.2%, DeepSeek-R1: 14.8%, o3-mini high: 12.6%)
- **GPT-OSS Medium (20B)**: +22.4% (Base: 22.4%, Base + RSA: 20.6%, DeepSeek-R1: 18.9%, o3-mini high: 16.3%)
- **DeepSeek-R1**: -1% (Base: -1%, Base + RSA: -2.3%, DeepSeek-R1: -3.5%, o3-mini high: -4.7%)
- **o3-mini (high)**: +22.4% (Base: 22.4%, Base + RSA: 20.6%, DeepSeek-R1: 18.9%, o3-mini high: 16.3%)
**Trend**:
- **o3-mini (high)** and **Nemotron Nano-v2** show the highest Pass@1, while **DeepSeek-R1** underperforms with negative values.
---
### **2. Reasoning Gym Cognition + ARC**
- **Models and Pass@1**:
- **GPT-OSS Medium (20B)**: +1.6% (Base: 1.6%, Base + RSA: 0.8%, DeepSeek-R1: 0.4%, o3-mini high: -0.2%)
- **Nemotron Nano-v2 (9B)**: +5.6% (Base: 5.6%, Base + RSA: 4.2%, DeepSeek-R1: 3.0%, o3-mini high: 1.8%)
- **Qwen3 Instruct (4B)**: +9.7% (Base: 9.7%, Base + RSA: 7.5%, DeepSeek-R1: 5.3%, o3-mini high: 3.1%)
- **Qwen3 Instruct (30B)**: +8.2% (Base: 8.2%, Base + RSA: 6.4%, DeepSeek-R1: 4.7%, o3-mini high: 2.9%)
- **DeepSeek-R1**: -1% (Base: -1%, Base + RSA: -0.5%, DeepSeek-R1: -0.3%, o3-mini high: -0.1%)
- **o3-mini (high)**: +8.2% (Base: 8.2%, Base + RSA: 6.4%, DeepSeek-R1: 4.7%, o3-mini high: 2.9%)
**Trend**:
- **Qwen3 Instruct (30B)** and **Qwen3 Instruct (4B)** show the highest Pass@1, while **DeepSeek-R1** again underperforms.
---
### **3. LiveCodeBench-v6**
- **Models and Pass@1**:
- **Qwen3 Instruct (4B)**: +7.1% (Base: 7.1%, Base + RSA: 5.3%, DeepSeek-R1: 3.8%, o3-mini high: 2.1%)
- **Qwen3 Instruct (30B)**: +7.1% (Base: 7.1%, Base + RSA: 5.3%, DeepSeek-R1: 3.8%, o3-mini high: 2.1%)
- **GPT-OSS Medium (20B)**: +5.6% (Base: 5.6%, Base + RSA: 4.1%, DeepSeek-R1: 2.9%, o3-mini high: 1.7%)
- **o3-mini (high)**: +5.6% (Base: 5.6%, Base + RSA: 4.1%, DeepSeek-R1: 2.9%, o3-mini high: 1.7%)
**Trend**:
- **Qwen3 Instruct (4B/30B)** and **o3-mini (high)** show similar performance, while **GPT-OSS Medium** lags.
---
### **4. HMMT-25**
- **Models and Pass@1**:
- **Qwen3 Instruct (4B)**: +20.4% (Base: 20.4%, Base + RSA: 18.2%, DeepSeek-R1: 15.6%, o3-mini high: 12.8%)
- **Nemotron Nano-v2 (9B)**: +25.9% (Base: 25.9%, Base + RSA: 23.7%, DeepSeek-R1: 21.4%, o3-mini high: 19.2%)
- **Qwen3 Instruct (30B)**: +25.1% (Base: 25.1%, Base + RSA: 22.9%, DeepSeek-R1: 20.6%, o3-mini high: 18.3%)
- **GPT-OSS Medium (20B)**: +12.6% (Base: 12.6%, Base + RSA: 10.8%, DeepSeek-R1: 9.4%, o3-mini high: 7.2%)
- **DeepSeek-R1**: -1% (Base: -1%, Base + RSA: -0.5%, DeepSeek-R1: -0.3%, o3-mini high: -0.1%)
- **o3-mini (high)**: +35.0% (Base: 35.0%, Base + RSA: 32.8%, DeepSeek-R1: 30.4%, o3-mini high: 28.1%)
**Trend**:
- **o3-mini (high)** achieves the highest Pass@1, while **DeepSeek-R1** again underperforms.
---
### **5. Reasoning Gym Games**
- **Models and Pass@1**:
- **Nemotron Nano-v2 (9B)**: +8.8% (Base: 8.8%, Base + RSA: 7.2%, DeepSeek-R1: 5.6%, o3-mini high: 3.4%)
- **GPT-OSS Medium (20B)**: +14.0% (Base: 14.0%, Base + RSA: 11.6%, DeepSeek-R1: 9.8%, o3-mini high: 7.2%)
- **Qwen3 Instruct (4B)**: +15.1% (Base: 15.1%, Base + RSA: 12.8%, DeepSeek-R1: 10.6%, o3-mini high: 8.2%)
- **Qwen3 Instruct (30B)**: +20.6% (Base: 20.6%, Base + RSA: 17.4%, DeepSeek-R1: 15.2%, o3-mini high: 12.8%)
- **DeepSeek-R1**: -1% (Base: -1%, Base + RSA: -0.5%, DeepSeek-R1: -0.3%, o3-mini high: -0.1%)
- **o3-mini (high)**: +20.6% (Base: 20.6%, Base + RSA: 17.4%, DeepSeek-R1: 15.2%, o3-mini high: 12.8%)
**Trend**:
- **Qwen3 Instruct (30B)** and **o3-mini (high)** lead, while **DeepSeek-R1** underperforms.
---
### **6. SuperGPQA**
- **Models and Pass@1**:
- **Qwen3 Instruct (4B)**: +5.5% (Base: 5.5%, Base + RSA: 4.2%, DeepSeek-R1: 3.0%, o3-mini high: 1.8%)
- **Qwen3 Instruct (30B)**: +6.7% (Base: 6.7%, Base + RSA: 5.3%, DeepSeek-R1: 4.1%, o3-mini high: 2.9%)
**Trend**:
- **Qwen3 Instruct (30B)** outperforms the 4B version, with **o3-mini (high)** showing the highest Pass@1.
---
## Spatial Grounding and Color Verification
- **Legend Colors**:
- **Base (Green)** matches the green segments in all bars.
- **Base + RSA (Orange)** matches the orange segments.
- **DeepSeek-R1 (Blue)** matches the blue segments.
- **o3-mini (high) (Dark Blue)** matches the dark blue segments.
**Legend Position**: Bottom of the chart, aligned with the x-axis.
---
## Component Isolation
- **Header**: Title "Model Performance Comparison Across Benchmarks".
- **Main Chart**: Grouped bars by benchmark, with segmented bars for models and components.
- **Footer**: Legend and axis labels.
---
## Data Table Reconstruction
| Benchmark | Model | Base (%) | Base + RSA (%) | DeepSeek-R1 (%) | o3-mini (high) (%) |
|-------------------------|------------------------|----------|----------------|------------------|--------------------|
| AIME-25 | Nemotron Nano-v2 (9B) | 32.1 | 29.8 | 27.2 | 22.4 |
| AIME-25 | Qwen3 Instruct (4B) | 27.2 | 25.1 | 22.4 | 19.4 |
| AIME-25 | Qwen3 Instruct (30B) | 19.4 | 17.2 | 14.8 | 12.6 |
| AIME-25 | GPT-OSS Medium (20B) | 22.4 | 20.6 | 18.9 | 16.3 |
| AIME-25 | DeepSeek-R1 | -1 | -2.3 | -3.5 | -4.7 |
| AIME-25 | o3-mini (high) | 22.4 | 20.6 | 18.9 | 16.3 |
| Reasoning Gym Cognition + ARC | GPT-OSS Medium (20B) | 1.6 | 0.8 | 0.4 | -0.2 |
| Reasoning Gym Cognition + ARC | Nemotron Nano-v2 (9B) | 5.6 | 4.2 | 3.0 | 1.8 |
| Reasoning Gym Cognition + ARC | Qwen3 Instruct (4B) | 9.7 | 7.5 | 5.3 | 3.1 |
| Reasoning Gym Cognition + ARC | Qwen3 Instruct (30B) | 8.2 | 6.4 | 4.7 | 2.9 |
| Reasoning Gym Cognition + ARC | DeepSeek-R1 | -1 | -0.5 | -0.3 | -0.1 |
| Reasoning Gym Cognition + ARC | o3-mini (high) | 8.2 | 6.4 | 4.7 | 2.9 |
| LiveCodeBench-v6 | Qwen3 Instruct (4B) | 7.1 | 5.3 | 3.8 | 2.1 |
| LiveCodeBench-v6 | Qwen3 Instruct (30B) | 7.1 | 5.3 | 3.8 | 2.1 |
| LiveCodeBench-v6 | GPT-OSS Medium (20B) | 5.6 | 4.1 | 2.9 | 1.7 |
| LiveCodeBench-v6 | o3-mini (high) | 5.6 | 4.1 | 2.9 | 1.7 |
| HMMT-25 | Qwen3 Instruct (4B) | 20.4 | 18.2 | 15.6 | 12.8 |
| HMMT-25 | Nemotron Nano-v2 (9B) | 25.9 | 23.7 | 21.4 | 19.2 |
| HMMT-25 | Qwen3 Instruct (30B) | 25.1 | 22.9 | 20.6 | 18.3 |
| HMMT-25 | GPT-OSS Medium (20B) | 12.6 | 10.8 | 9.4 | 7.2 |
| HMMT-25 | DeepSeek-R1 | -1 | -0.5 | -0.3 | -0.1 |
| HMMT-25 | o3-mini (high) | 35.0 | 32.8 | 30.4 | 28.1 |
| Reasoning Gym Games | Nemotron Nano-v2 (9B) | 8.8 | 7.2 | 5.6 | 3.4 |
| Reasoning Gym Games | GPT-OSS Medium (20B) | 14.0 | 11.6 | 9.8 | 7.2 |
| Reasoning Gym Games | Qwen3 Instruct (4B) | 15.1 | 12.8 | 10.6 | 8.2 |
| Reasoning Gym Games | Qwen3 Instruct (30B) | 20.6 | 17.4 | 15.2 | 12.8 |
| Reasoning Gym Games | DeepSeek-R1 | -1 | -0.5 | -0.3 | -0.1 |
| Reasoning Gym Games | o3-mini (high) | 20.6 | 17.4 | 15.2 | 12.8 |
| SuperGPQA | Qwen3 Instruct (4B) | 5.5 | 4.2 | 3.0 | 1.8 |
| SuperGPQA | Qwen3 Instruct (30B) | 6.7 | 5.3 | 4.1 | 2.9 |
---
## Notes
- **Negative Values**: Indicate underperformance relative to the base model (e.g., DeepSeek-R1 in AIME-25).
- **Component Contributions**: Each bar’s segments sum to the total Pass@1 for that model on the benchmark.
- **Model Variants**: Qwen3 Instruct has 4B and 30B versions; GPT-OSS Medium is 20B; DeepSeek-R1 and o3-mini (high) are distinct configurations.
This structured analysis ensures all textual and numerical data from the chart is captured, with trends and component relationships clearly articulated.
DECODING INTELLIGENCE...