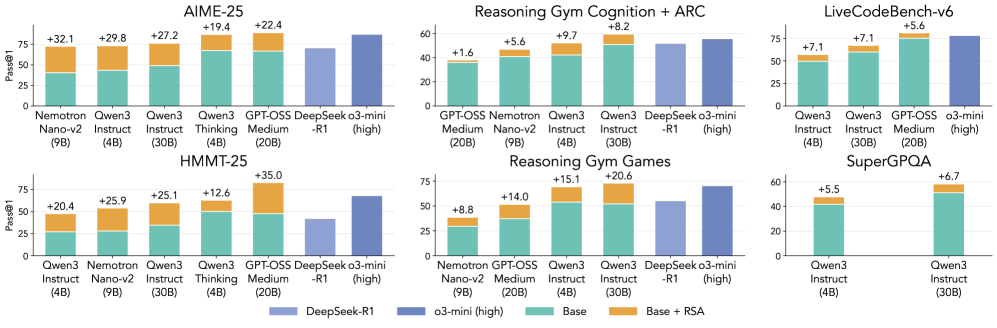
# Technical Data Extraction: AI Model Performance Benchmarks
This document provides a comprehensive extraction of data from a series of six bar charts comparing various AI models across different reasoning and coding benchmarks.
## 1. Global Metadata and Legend
* **Y-Axis Label:** `Pass@1` (Applies to all charts).
* **Y-Axis Scale:** Ranges from 0 to 75 or 100 depending on the sub-chart, with horizontal grid lines at intervals of 25.
* **Legend (Located at the bottom center):**
* **Light Blue (Solid):** `DeepSeek-R1`
* **Dark Blue (Solid):** `o3-mini (high)`
* **Teal (Bottom segment of stacked bar):** `Base`
* **Orange (Top segment of stacked bar):** `Base + RSA` (The number above these bars indicates the delta/improvement provided by RSA).
---
## 2. Benchmark Data Extraction
### Chart 1: AIME-25
| Model | Base | RSA Delta | Total |
| :--- | :--- | :--- | :--- |
| Nemotron Nano-v2 (9B) | ~40 | +32.1 | ~72.1 |
| Qwen3 Instruct (4B) | ~42 | +29.8 | ~71.8 |
| Qwen3 Instruct (30B) | ~48 | +27.2 | ~75.2 |
| Qwen3 Thinking (4B) | ~68 | +19.4 | ~87.4 |
| GPT-OSS Medium (20B) | ~67 | +22.4 | ~89.4 |
| DeepSeek-R1 | ~70 | N/A | ~70 |
| o3-mini (high) | ~85 | N/A | ~85 |
### Chart 2: Reasoning Gym Cognition + ARC
| Model | Base | RSA Delta | Total |
| :--- | :--- | :--- | :--- |
| GPT-OSS Medium (20B) | ~35 | +1.6 | ~36.6 |
| Nemotron Nano-v2 (9B) | ~40 | +5.6 | ~45.6 |
| Qwen3 Instruct (4B) | ~42 | +9.7 | ~51.7 |
| Qwen3 Instruct (30B) | ~50 | +8.2 | ~58.2 |
| DeepSeek-R1 | ~52 | N/A | ~52 |
| o3-mini (high) | ~55 | N/A | ~55 |
### Chart 3: LiveCodeBench-v6
| Model | Base | RSA Delta | Total |
| :--- | :--- | :--- | :--- |
| Qwen3 Instruct (4B) | ~49 | +7.1 | ~56.1 |
| Qwen3 Instruct (30B) | ~60 | +7.1 | ~67.1 |
| GPT-OSS Medium (20B) | ~75 | +5.6 | ~80.6 |
| o3-mini (high) | ~78 | N/A | ~78 |
### Chart 4: HMMT-25
| Model | Base | RSA Delta | Total |
| :--- | :--- | :--- | :--- |
| Qwen3 Instruct (4B) | ~27 | +20.4 | ~47.4 |
| Nemotron Nano-v2 (9B) | ~28 | +25.9 | ~53.9 |
| Qwen3 Instruct (30B) | ~34 | +25.1 | ~59.1 |
| Qwen3 Thinking (4B) | ~50 | +12.6 | ~62.6 |
| GPT-OSS Medium (20B) | ~48 | +35.0 | ~83.0 |
| DeepSeek-R1 | ~42 | N/A | ~42 |
| o3-mini (high) | ~68 | N/A | ~68 |
### Chart 5: Reasoning Gym Games
| Model | Base | RSA Delta | Total |
| :--- | :--- | :--- | :--- |
| Nemotron Nano-v2 (9B) | ~29 | +8.8 | ~37.8 |
| GPT-OSS Medium (20B) | ~37 | +14.0 | ~51.0 |
| Qwen3 Instruct (4B) | ~53 | +15.1 | ~68.1 |
| Qwen3 Instruct (30B) | ~52 | +20.6 | ~72.6 |
| DeepSeek-R1 | ~55 | N/A | ~55 |
| o3-mini (high) | ~70 | N/A | ~70 |
### Chart 6: SuperGPQA
| Model | Base | RSA Delta | Total |
| :--- | :--- | :--- | :--- |
| Qwen3 Instruct (4B) | ~41 | +5.5 | ~46.5 |
| Qwen3 Instruct (30B) | ~51 | +6.7 | ~57.7 |
---
## 3. Summary of Findings
The data demonstrates that the **RSA (Reasoning-Step Analysis/Augmentation)** technique consistently improves the `Pass@1` performance of "Base" models across all tested benchmarks. The most dramatic improvements are seen in the **AIME-25** and **HMMT-25** benchmarks, where RSA allows smaller models (like Nemotron 9B or Qwen3 4B) to approach or exceed the performance of much larger models like DeepSeek-R1. In several instances (AIME-25, HMMT-25), the `Base + RSA` configuration for GPT-OSS Medium (20B) outperforms the `o3-mini (high)` model.