\n
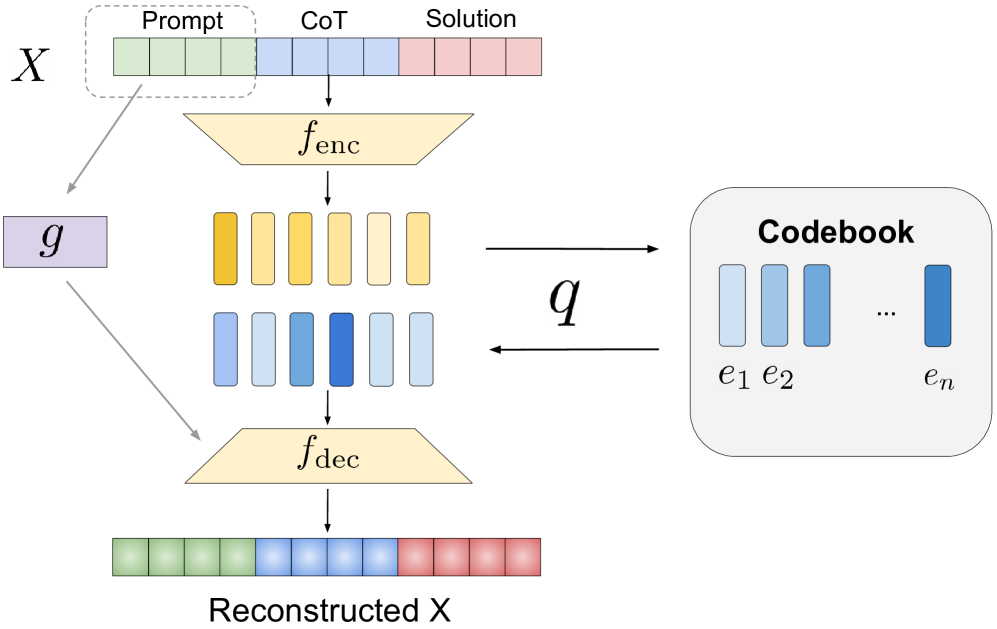
## Diagram: Sequence-to-Sequence Model with Codebook
### Overview
This diagram illustrates a sequence-to-sequence model architecture incorporating a codebook for representation learning. The model takes an input sequence *X*, encodes it, quantizes the encoded representation using a codebook, and then decodes it to reconstruct the original sequence. The diagram highlights the key components and data flow within this system.
### Components/Axes
The diagram consists of the following components:
* **Input Sequence X:** Represented as a segmented bar, divided into three sections labeled "Prompt", "CoT" (Chain of Thought), and "Solution".
* **Encoder (f<sub>enc</sub>):** A yellow trapezoid transforming the input sequence.
* **Quantization (q):** A process mapping the encoded representation to a codebook.
* **Codebook:** A gray rectangle containing a set of embeddings labeled *e<sub>1</sub>*, *e<sub>2</sub>*, ..., *e<sub>n</sub>*.
* **Decoder (f<sub>dec</sub>):** An orange trapezoid reconstructing the sequence.
* **Reconstructed X:** The output sequence, visually similar to the input *X*.
* **g:** A gray rectangle with an arrow pointing towards the encoder.
### Detailed Analysis or Content Details
The diagram depicts the following data flow:
1. **Input:** The input sequence *X* is divided into three segments: "Prompt", "CoT", and "Solution". The lengths of these segments appear roughly equal, though precise lengths are not specified.
2. **Encoding:** The input sequence *X* is passed through the encoder *f<sub>enc</sub>*, resulting in an intermediate representation consisting of two rows of yellow rectangles. The number of rectangles in each row is equal to the number of segments in *X*.
3. **Quantization:** The encoded representation is then quantized using the function *q*, which maps the encoded vectors to the nearest embedding in the codebook. The codebook contains *n* embeddings, labeled *e<sub>1</sub>* through *e<sub>n</sub>*.
4. **Decoding:** The quantized representation is passed through the decoder *f<sub>dec</sub>*, which reconstructs the original sequence.
5. **Output:** The reconstructed sequence, labeled "Reconstructed X", is visually similar to the original input *X*.
6. **Feedback Loop:** A feedback loop is present, indicated by the arrow from the gray rectangle labeled *g* to the encoder *f<sub>enc</sub>*. The purpose of this loop is not explicitly stated in the diagram.
### Key Observations
* The diagram emphasizes the use of a discrete codebook to represent the encoded information.
* The encoder and decoder are represented as simple trapezoids, suggesting they could be any type of sequence-to-sequence model (e.g., RNN, Transformer).
* The diagram does not provide any specific details about the quantization process *q* or the learning of the codebook embeddings.
* The feedback loop *g* suggests a potential for iterative refinement or learning.
### Interpretation
This diagram illustrates a method for learning discrete representations of sequential data. By quantizing the encoded representation using a codebook, the model can potentially learn more compact and interpretable representations. This approach is particularly relevant in the context of large language models, where discrete representations can be used to reduce computational cost and improve generalization. The "Prompt", "CoT", and "Solution" segments suggest the model is designed for tasks that involve reasoning or problem-solving, where the "CoT" segment represents the intermediate reasoning steps. The feedback loop *g* could represent a mechanism for refining the encoded representation based on the reconstruction error, potentially leading to improved performance. The diagram is a high-level overview and does not provide details on the specific implementation or training procedure.