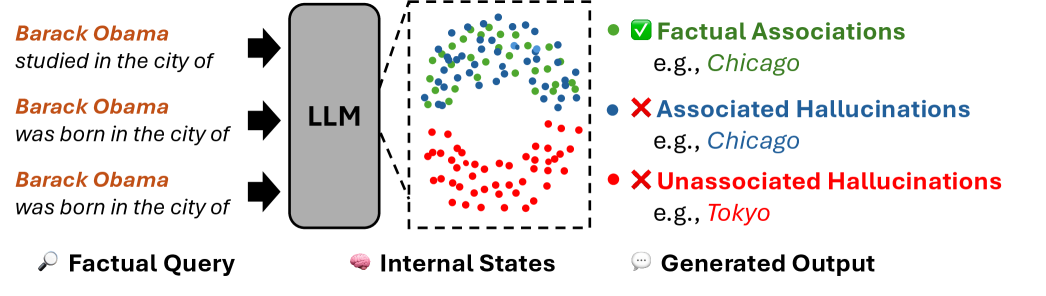
## Diagram: LLM Factual Query Processing and Hallucination Types
### Overview
The image is a conceptual diagram illustrating how a Large Language Model (LLM) processes factual queries and generates outputs, categorizing the outputs into factual associations and two types of hallucinations. It visually maps the flow from input queries through the model's internal states to the final generated text.
### Components/Axes
The diagram is organized into three distinct vertical sections, flowing from left to right:
1. **Left Section: Factual Query**
* **Label:** "Factual Query" (accompanied by a magnifying glass icon 🔍).
* **Content:** Three example text queries about Barack Obama, formatted with the subject in orange and the query in black:
* "Barack Obama studied in the city of"
* "Barack Obama was born in the city of"
* "Barack Obama was born in the city of" (a duplicate of the second query).
* **Flow:** Black arrows point from each query into the central "LLM" block.
2. **Central Section: Internal States**
* **Label:** "Internal States" (accompanied by a brain icon 🧠).
* **Component:** A large, gray, rounded rectangle labeled "LLM".
* **Visualization:** A dashed-line box to the right of the LLM contains a scatter plot representing the model's internal state space. The plot contains numerous colored dots:
* **Green dots:** Clustered densely in the upper portion.
* **Blue dots:** Scattered in the middle region, partially overlapping with green.
* **Red dots:** Clustered densely in the lower portion.
3. **Right Section: Generated Output**
* **Label:** "Generated Output" (accompanied by a speech bubble icon 💬).
* **Legend & Examples:** A key explains the color coding of the dots in the Internal States plot, with corresponding example outputs:
* **Green Circle (✅):** "Factual Associations" - Example: "e.g., *Chicago*" (in green text).
* **Blue Circle (❌):** "Associated Hallucinations" - Example: "e.g., *Chicago*" (in blue text).
* **Red Circle (❌):** "Unassociated Hallucinations" - Example: "e.g., *Tokyo*" (in red text).
### Detailed Analysis
The diagram establishes a clear visual metaphor for LLM behavior:
* **Input Processing:** Identical or similar factual queries ("born in the city of") are fed into the LLM.
* **Internal Representation:** The model's internal processing is represented as a high-dimensional state space (the scatter plot). The spatial clustering of colored dots suggests that different types of outputs originate from distinct regions or patterns of activation within the model.
* **Output Classification:** The legend explicitly defines three output categories based on their relationship to the input query and factual knowledge:
1. **Factual Associations (Green):** Correct, grounded information (e.g., answering "Chicago" to "born in the city of").
2. **Associated Hallucinations (Blue):** Plausible but incorrect information that is semantically related to the subject or query (e.g., also answering "Chicago" to "studied in the city of," which is factually incorrect for Obama).
3. **Unassociated Hallucinations (Red):** Information that is neither correct nor semantically related to the query (e.g., answering "Tokyo" to "born in the city of").
### Key Observations
1. **Duplicate Query:** The second and third input queries are identical ("Barack Obama was born in the city of"). This implies the diagram is illustrating that the *same* input can lead to different output types (green, blue, or red) depending on the internal state activated.
2. **Spatial Separation in Internal States:** The green (factual) and red (unassociated hallucination) clusters are visually distinct and separated, with the blue (associated hallucination) cluster occupying a middle ground. This suggests a potential topological structure in the model's knowledge representation.
3. **Color-Coded Consistency:** The color of the example text in the "Generated Output" section (green "Chicago", blue "Chicago", red "Tokyo") matches the color of the corresponding dot in the legend and the clusters in the Internal States plot.
### Interpretation
This diagram provides a Peircean investigative model for understanding LLM hallucinations. It moves beyond a simple "right vs. wrong" dichotomy by introducing a nuanced taxonomy based on the *source* of the error relative to the query's context.
* **What it demonstrates:** The core message is that hallucinations are not monolithic. "Associated Hallucinations" (blue) are particularly insidious because they stem from the model's correct associative knowledge (linking Obama to Chicago) but apply it to the wrong factual predicate (studied vs. born). This is distinct from "Unassociated Hallucinations" (red), which represent a more complete failure of grounding.
* **How elements relate:** The flow from Query → LLM → Internal States → Output argues that the origin of a hallucination can be traced to specific patterns of activation within the model. The clustering implies that interventions (like decoding strategies or probing) might target these distinct internal regions to suppress errors.
* **Notable implication:** The presence of the same example ("Chicago") for both a factual association and an associated hallucination is critical. It highlights that the *surface form* of an output is insufficient to judge its factuality; the underlying internal state and its relationship to the specific query are what determine correctness. This underscores the challenge of detecting and mitigating hallucinations in practice.