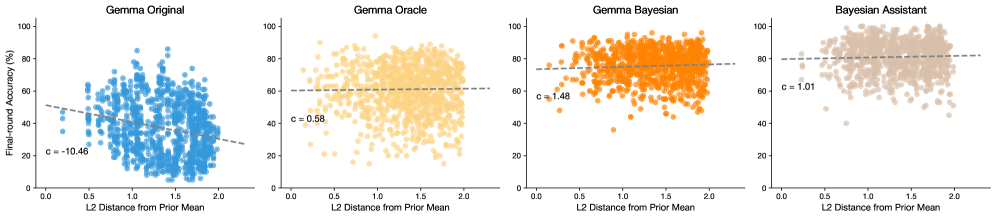
## Scatter Plot: Final-round Accuracy vs. L2 Distance from Prior Mean for Different Models
### Overview
The image presents four scatter plots, each displaying the relationship between "Final-round Accuracy (%)" and "L2 Distance from Prior Mean" for different models: "Gemma Original", "Gemma Oracle", "Gemma Bayesian", and "Bayesian Assistant". Each plot includes a dashed gray line indicating a linear trend, along with a 'c' value representing the slope of that line.
### Components/Axes
* **X-axis (Horizontal):** "L2 Distance from Prior Mean". The scale ranges from 0.0 to 2.0 in all four plots.
* **Y-axis (Vertical):** "Final-round Accuracy (%)". The scale ranges from 0 to 100 in all four plots.
* **Titles:** Each plot has a title indicating the model being analyzed: "Gemma Original", "Gemma Oracle", "Gemma Bayesian", and "Bayesian Assistant".
* **Data Points:** Each plot contains numerous data points representing individual observations.
* Gemma Original: Blue data points.
* Gemma Oracle: Yellow data points.
* Gemma Bayesian: Orange data points.
* Bayesian Assistant: Tan data points.
* **Trend Line:** A dashed gray line is present in each plot, indicating the general trend of the data.
* **'c' Value:** Each plot displays a 'c' value, representing the slope of the trend line.
### Detailed Analysis
**1. Gemma Original (Top-Left)**
* Data points are blue.
* Trend: The data points are scattered, but there is a slight downward trend.
* 'c' Value: c = -10.46
* Accuracy ranges from approximately 20% to 80%.
* L2 Distance ranges from 0 to 2.
**2. Gemma Oracle (Top-Middle)**
* Data points are yellow.
* Trend: The data points are scattered, with no clear trend.
* 'c' Value: c = 0.58
* Accuracy ranges from approximately 20% to 100%.
* L2 Distance ranges from 0 to 2.
**3. Gemma Bayesian (Top-Right)**
* Data points are orange.
* Trend: The data points are scattered, with no clear trend.
* 'c' Value: c = 1.48
* Accuracy ranges from approximately 50% to 100%.
* L2 Distance ranges from 0 to 2.
**4. Bayesian Assistant (Top-Right)**
* Data points are tan.
* Trend: The data points are scattered, with no clear trend.
* 'c' Value: c = 1.01
* Accuracy ranges from approximately 50% to 100%.
* L2 Distance ranges from 0 to 2.
### Key Observations
* The "Gemma Original" model shows a slight negative correlation between L2 Distance and Final-round Accuracy.
* The "Gemma Oracle", "Gemma Bayesian", and "Bayesian Assistant" models show no clear correlation between L2 Distance and Final-round Accuracy.
* The "Gemma Original" model has a lower range of accuracy compared to the other three models.
### Interpretation
The plots compare the performance of different models ("Gemma Original", "Gemma Oracle", "Gemma Bayesian", and "Bayesian Assistant") in relation to the L2 distance from the prior mean. The 'c' value indicates the slope of the linear trend line, providing insight into how accuracy changes with increasing L2 distance.
The negative 'c' value for "Gemma Original" suggests that as the L2 distance from the prior mean increases, the final-round accuracy tends to decrease slightly. In contrast, the other three models show a slightly positive or near-zero correlation, indicating that accuracy is not strongly affected by the L2 distance from the prior mean.
The data suggests that the "Gemma Original" model might be more sensitive to deviations from the prior mean compared to the other models. The "Gemma Oracle", "Gemma Bayesian", and "Bayesian Assistant" models appear to maintain a relatively stable level of accuracy regardless of the L2 distance.