TECHNICAL ASSET FINGERPRINT
a311bea2312de4ad4651e6db
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
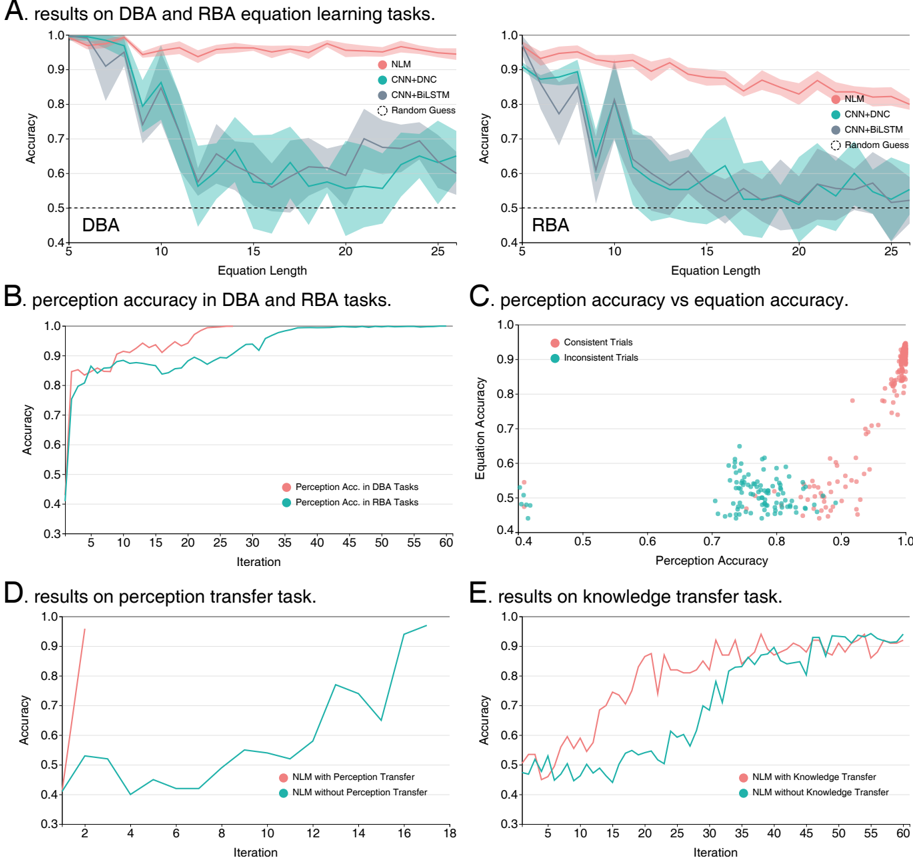
## Multi-Panel Chart: Results on Equation Learning and Transfer Tasks
### Overview
The image is a composite figure containing five panels (A-E) displaying performance metrics for different neural network models on symbolic equation learning tasks. The tasks involve "DBA" (likely Distributed Binary Arithmetic) and "RBA" (likely Recursive Binary Arithmetic). The charts compare model accuracy across equation lengths, training iterations, and transfer learning conditions.
### Components/Axes
The figure is divided into five distinct panels:
* **Panel A (Top Row):** Two line charts titled "results on DBA and RBA equation learning tasks."
* **Left Chart (DBA):** X-axis: "Equation Length" (5 to 25). Y-axis: "Accuracy" (0.4 to 1.0).
* **Right Chart (RBA):** X-axis: "Equation Length" (5 to 25). Y-axis: "Accuracy" (0.4 to 1.0).
* **Legend (Both):** Located in the top-right corner of each subplot. Contains four entries:
* `NLM` (Pink line with light pink shaded confidence interval)
* `CNN+DNC` (Teal line with light teal shaded confidence interval)
* `CNN+BiLSTM` (Gray line with light gray shaded confidence interval)
* `Random Guess` (Black dashed horizontal line at y=0.5)
* **Panel B (Middle Left):** Line chart titled "perception accuracy in DBA and RBA tasks."
* **X-axis:** "Iteration" (0 to 60).
* **Y-axis:** "Accuracy" (0.3 to 1.0).
* **Legend (Bottom Right):** Two entries:
* `Perception Acc. in DBA Tasks` (Pink line)
* `Perception Acc. in RBA Tasks` (Teal line)
* **Panel C (Middle Right):** Scatter plot titled "perception accuracy vs equation accuracy."
* **X-axis:** "Perception Accuracy" (0.4 to 1.0).
* **Y-axis:** "Equation Accuracy" (0.4 to 1.0).
* **Legend (Top Left):** Two entries:
* `Consistent Trials` (Pink dots)
* `Inconsistent Trials` (Teal dots)
* **Panel D (Bottom Left):** Line chart titled "results on perception transfer task."
* **X-axis:** "Iteration" (2 to 18).
* **Y-axis:** "Accuracy" (0.3 to 1.0).
* **Legend (Bottom Right):** Two entries:
* `NLM with Perception Transfer` (Pink line)
* `NLM without Perception Transfer` (Teal line)
* **Panel E (Bottom Right):** Line chart titled "results on knowledge transfer task."
* **X-axis:** "Iteration" (5 to 60).
* **Y-axis:** "Accuracy" (0.4 to 1.0).
* **Legend (Bottom Right):** Two entries:
* `NLM with Knowledge Transfer` (Pink line)
* `NLM without Knowledge Transfer` (Teal line)
### Detailed Analysis
**Panel A: Equation Learning Tasks**
* **Trend Verification:** For both DBA and RBA, the `NLM` (pink) line shows a slight, gradual decline in accuracy as equation length increases, remaining above 0.9. The `CNN+DNC` (teal) and `CNN+BiLSTM` (gray) lines show a sharp drop in accuracy between lengths 5 and 10, followed by a noisy, fluctuating plateau between approximately 0.55 and 0.75 for lengths 10-25. The `Random Guess` baseline is constant at 0.5.
* **Data Points (Approximate):**
* **DBA Chart:** At length 5, all models start near 1.0 accuracy. At length 25, `NLM` is ~0.95, `CNN+DNC` is ~0.65, `CNN+BiLSTM` is ~0.60.
* **RBA Chart:** Similar pattern. At length 25, `NLM` is ~0.85, `CNN+DNC` is ~0.55, `CNN+BiLSTM` is ~0.50.
**Panel B: Perception Accuracy**
* **Trend Verification:** Both lines show rapid initial learning. The `Perception Acc. in DBA Tasks` (pink) line rises quickly to ~0.9 by iteration 10 and approaches 1.0 by iteration 30. The `Perception Acc. in RBA Tasks` (teal) line follows a similar but slightly lower trajectory, reaching ~0.9 by iteration 20 and converging near 1.0 by iteration 50.
**Panel C: Perception vs. Equation Accuracy**
* **Data Distribution:** The scatter plot shows a positive correlation. `Consistent Trials` (pink) are clustered in the top-right quadrant, indicating high perception accuracy (>0.8) correlates with high equation accuracy (>0.7). `Inconsistent Trials` (teal) are clustered in the lower-middle region, with perception accuracy between 0.7-0.85 and equation accuracy between 0.45-0.65. There is a clear separation between the two clusters.
**Panel D: Perception Transfer Task**
* **Trend Verification:** The `NLM with Perception Transfer` (pink) line shows an extremely steep learning curve, reaching near 1.0 accuracy by iteration 3. The `NLM without Perception Transfer` (teal) line starts lower (~0.4), fluctuates, and shows a more gradual, step-wise increase, reaching ~0.95 by iteration 17.
**Panel E: Knowledge Transfer Task**
* **Trend Verification:** Both lines show learning over iterations. The `NLM with Knowledge Transfer` (pink) line starts higher (~0.5 vs ~0.45) and maintains a consistent lead of approximately 0.1-0.2 accuracy points throughout training. Both lines show significant fluctuation but trend upward, ending above 0.9 by iteration 60.
### Key Observations
1. **Model Superiority:** The `NLM` model significantly and consistently outperforms the `CNN+DNC` and `CNN+BiLSTM` architectures on the core equation learning task (Panel A), especially as problem complexity (equation length) increases.
2. **Perception is Foundational:** High perception accuracy is a prerequisite for high equation accuracy (Panel C). Trials where perception fails ("Inconsistent") lead to poor equation-solving performance.
3. **Transfer Learning Efficacy:** Both forms of transfer learning (perception and knowledge) provide a substantial boost. Perception transfer (Panel D) leads to almost immediate mastery, while knowledge transfer (Panel E) provides a consistent performance advantage throughout training.
4. **Task Difficulty:** The RBA task appears slightly more challenging than the DBA task, as evidenced by lower final accuracies in Panel A and a slower rise in perception accuracy in Panel B.
### Interpretation
This set of charts presents a Peircean investigation into the components of learning for symbolic reasoning. The data suggests a hierarchical model of skill acquisition:
1. **Perception First:** The system must first learn to accurately perceive or parse the input symbols (the "percept" in Peircean terms). Panel B shows this is a learnable skill, and Panel C proves its critical importance—without accurate perception, correct reasoning (equation accuracy) is impossible.
2. **Reasoning on a Foundation:** Once perception is reliable, the model can learn the underlying rules or "laws" of the equation system (the "interpretant"). The `NLM` architecture appears far more capable of this abstract rule-learning than the CNN-based hybrids, as it maintains high accuracy regardless of equation length (Panel A).
3. **Transfer as Efficient Learning:** The transfer learning results (Panels D & E) demonstrate that knowledge gained in one context (e.g., perception of basic symbols) can be efficiently applied to accelerate learning in a related, more complex context (solving full equations). This mirrors efficient cognitive learning, where prior knowledge scaffolds new learning.
**Notable Anomaly:** The `CNN+DNC` and `CNN+BiLSTM` models in Panel A show a dramatic performance collapse between equation lengths 5 and 10, after which they never recover to high accuracy. This suggests these architectures hit a fundamental capacity limit or fail to generalize the rule beyond very short sequences, unlike the `NLM`. The high variance (wide confidence intervals) in their performance also indicates instability in learning these tasks.
DECODING INTELLIGENCE...