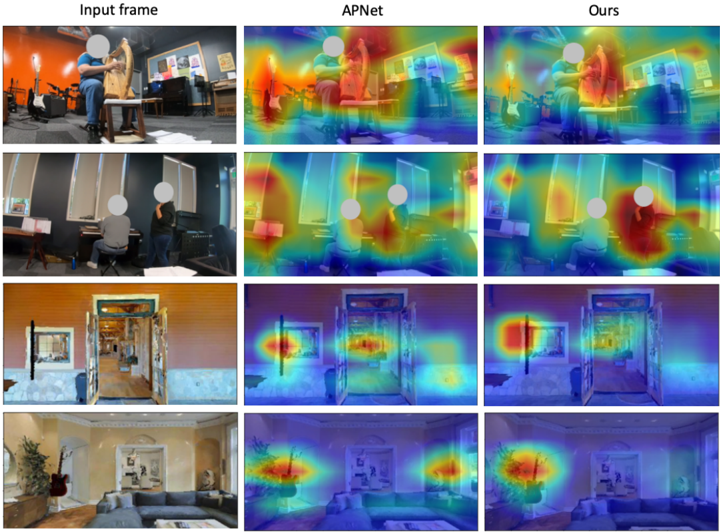
## Heatmap Comparison: APNet vs. Ours
### Overview
The image presents a comparative analysis of attention heatmaps generated by two models (APNet and "Ours") across four distinct scenes. Each row represents a unique environment, with the leftmost column showing the original input frame and the rightmost two columns displaying heatmaps generated by APNet and the proposed model ("Ours"). The heatmaps use a color gradient (blue to red) to indicate attention intensity, with red representing higher focus.
### Components/Axes
- **Columns**:
1. **Input Frame**: Original images of four scenes.
2. **APNet**: Attention heatmaps from the baseline model.
3. **Ours**: Attention heatmaps from the proposed model.
- **Rows**:
- Row 1: Person playing a harp in a music studio.
- Row 2: Two individuals at a desk in an office.
- Row 3: Doorway scene with a guitar visible.
- Row 4: Living room with a couch and guitar.
- **Color Scale**: Implied gradient from blue (low attention) to red (high attention), though no explicit legend is present.
### Detailed Analysis
#### Row 1 (Music Studio)
- **Input Frame**: A person seated playing a harp, with musical equipment in the background.
- **APNet**: Heatmap shows diffuse red areas around the harp and the player’s hands, with some focus on the background guitar.
- **Ours**: More concentrated red regions on the harp and the player’s hands, with reduced background noise.
#### Row 2 (Office Desk)
- **Input Frame**: Two individuals seated at a desk with computers and papers.
- **APNet**: Broad red areas covering both individuals and the desk, with some attention to the background window.
- **Ours**: Sharper focus on the person closest to the camera, with minimal attention to the second individual or background.
#### Row 3 (Doorway Scene)
- **Input Frame**: A doorway with a guitar leaning against a wall and a framed picture.
- **APNet**: Red areas highlight the doorway and the guitar, with some attention to the framed picture.
- **Ours**: Stronger focus on the guitar and doorway, with reduced emphasis on the framed picture.
#### Row 4 (Living Room)
- **Input Frame**: A couch, guitar, and decorative elements in a living room.
- **APNet**: Diffuse red areas around the guitar and couch, with some attention to the background.
- **Ours**: Concentrated red regions on the guitar and couch, with minimal background noise.
### Key Observations
1. **Focus Precision**: The "Ours" model consistently demonstrates sharper and more targeted attention compared to APNet, particularly in cluttered scenes (e.g., Row 2 and Row 4).
2. **Background Noise**: APNet exhibits broader attention spreads, including irrelevant background elements (e.g., framed pictures in Row 3), while "Ours" minimizes such distractions.
3. **Object Recognition**: Both models prioritize key objects (e.g., harp, guitar), but "Ours" shows stronger alignment with task-relevant regions.
### Interpretation
The heatmaps suggest that the proposed model ("Ours") improves attention mechanism efficiency by:
- **Reducing Overfitting**: Narrower focus on task-critical regions (e.g., the harp player’s hands in Row 1).
- **Enhancing Scene Understanding**: Better isolation of primary subjects (e.g., the guitar in Row 3) while ignoring peripheral details.
- **Task-Specific Optimization**: The ability to prioritize contextually relevant elements (e.g., the couch in Row 4) over generic background features.
This comparison highlights advancements in attention modeling, potentially leading to improved performance in applications like object detection, scene segmentation, or human activity recognition.