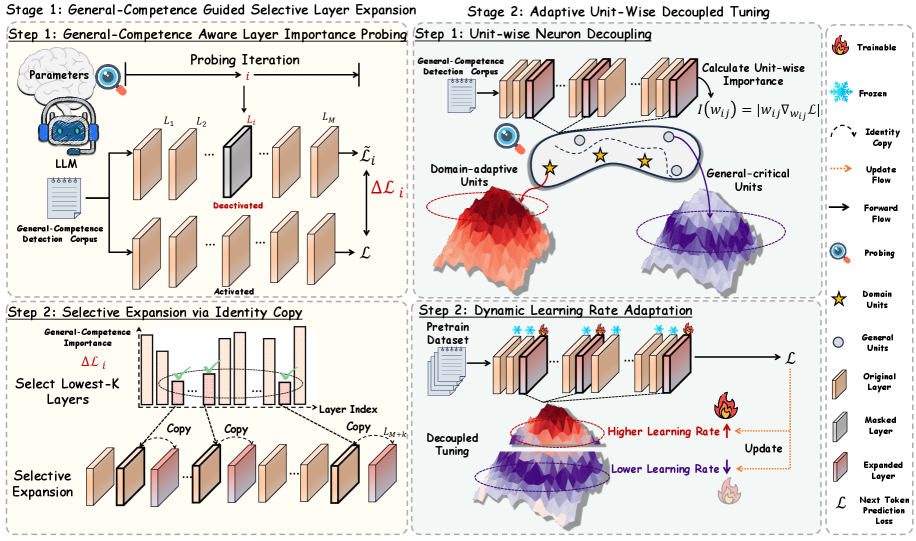
## Diagram: General-Competence Guided Selective Layer Expansion and Adaptive Unit-Wise Decoupled Tuning
### Overview
The image presents a two-stage diagram illustrating a method for selective layer expansion and adaptive unit-wise decoupled tuning in a neural network. Stage 1 focuses on identifying important layers and expanding them, while Stage 2 focuses on decoupling and tuning individual units.
### Components/Axes
**Stage 1: General-Competence Guided Selective Layer Expansion**
* **Step 1: General-Competence Aware Layer Importance Probing:**
* **Parameters:** Represented by a brain icon.
* **LLM:** A cartoon avatar wearing a VR headset.
* **General-Competence Detection Corpus:** Represented by a document icon with scribbles.
* **Probing Iteration:** Denoted by 'i'.
* **Layers:** L1, L2, Li, LM, represented as stacked blocks. One layer (Li) is shown as "Deactivated" (greyed out), while another is "Activated".
* **ΔLi:** Change in loss.
* **L:** Loss.
* **Step 2: Selective Expansion via Identity Copy:**
* **General-Competence Importance:** Y-axis of a bar graph.
* **ΔLi:** Change in loss.
* **Select Lowest-K Layers:** Text label.
* **Layer Index:** X-axis of the bar graph.
* **Copy:** Arrows indicating copying of layers.
* **Selective Expansion:** Expanded layers.
* **L(M+k):** Label indicating the copied layer.
**Stage 2: Adaptive Unit-Wise Decoupled Tuning**
* **Step 1: Unit-wise Neuron Decoupling:**
* **General-Competence Detection Corpus:** Represented by a document icon with scribbles.
* **Domain-adaptive Units:** Units highlighted with a star icon.
* **General-critical Units:** Units highlighted with a circle icon.
* **Calculate Unit-wise Importance:** I(wij) = |wij∇wijL|
* Two 3D surface plots, one labeled "Domain-adaptive Units" (red/orange) and the other "General-critical Units" (purple/blue).
* **Step 2: Dynamic Learning Rate Adaptation:**
* **Pretrain Dataset:** Represented by a document icon.
* **Decoupled Tuning:** Text label.
* **Higher Learning Rate:** Indicated by an upward-pointing arrow and a flame icon.
* **Lower Learning Rate:** Indicated by a downward-pointing arrow and a flame icon.
* **Update:** Text label with an arrow.
* Two 3D surface plots, one showing "Higher Learning Rate" (red/orange) and the other "Lower Learning Rate" (purple/blue).
**Legend (Right Side)**
* **Trainable:** Flame icon.
* **Frozen:** Snowflake icon.
* **Identity Copy:** Dashed arrow.
* **Update Flow:** Dotted arrow.
* **Forward Flow:** Solid arrow.
* **Probing:** Magnifying glass icon.
* **Domain Units:** Star icon.
* **General Units:** Circle icon.
* **Original Layer:** Light brown rectangle.
* **Masked Layer:** Grey rectangle.
* **Expanded Layer:** Red rectangle.
* **L:** Next Token Prediction Loss.
### Detailed Analysis
**Stage 1:**
* The process starts with "Parameters" and "General-Competence Detection Corpus" feeding into an LLM.
* The LLM probes the layers (L1 to LM) to determine their importance.
* The probing iteration is denoted by 'i'.
* Layers are either "Deactivated" or "Activated" based on the probing.
* The "Selective Expansion via Identity Copy" step involves selecting the lowest-K layers based on their importance (ΔLi).
* These selected layers are then copied and expanded.
**Stage 2:**
* The "Unit-wise Neuron Decoupling" step involves calculating the importance of individual units within the layers.
* The formula for calculating unit-wise importance is given as I(wij) = |wij∇wijL|.
* The "Dynamic Learning Rate Adaptation" step adjusts the learning rate for each unit based on its importance.
* Units with higher importance receive a higher learning rate, while units with lower importance receive a lower learning rate.
### Key Observations
* The diagram highlights a two-stage process for optimizing neural networks.
* Stage 1 focuses on identifying and expanding important layers, while Stage 2 focuses on decoupling and tuning individual units.
* The use of visual cues, such as icons and arrows, helps to illustrate the flow of information and the different steps involved in the process.
* The 3D surface plots in Stage 2 provide a visual representation of the learning rate adaptation process.
### Interpretation
The diagram illustrates a method for improving the efficiency and effectiveness of neural network training. By selectively expanding important layers and adaptively tuning individual units, the network can learn more quickly and achieve better performance. The method leverages the concept of "General-Competence" to guide the selection and tuning process, ensuring that the network is optimized for a specific task or domain. The use of decoupled tuning allows for more fine-grained control over the learning process, enabling the network to adapt to the specific characteristics of the data. The diagram suggests a sophisticated approach to neural network optimization that combines layer-level and unit-level techniques.