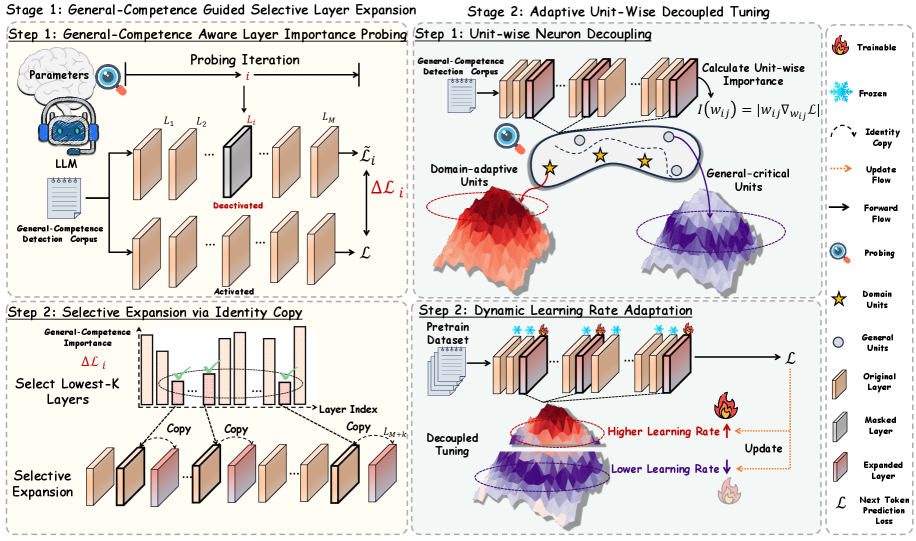
\n
## Diagram: General-Competence Guided Selective Layer Expansion & Adaptive Unit-Wise Decoupled Tuning
### Overview
This diagram illustrates a two-stage process for enhancing Large Language Models (LLMs). Stage 1 focuses on "General-Competence Guided Selective Layer Expansion," while Stage 2 details "Adaptive Unit-Wise Decoupled Tuning." The diagram uses a block-based structure with flow arrows to represent the process. It depicts the interaction between LLM layers, probing iterations, and the adaptation of learning rates.
### Components/Axes
The diagram is divided into two main stages, each with two steps. Key components include:
* **LLM:** Large Language Model.
* **Layers (L1 to LM):** Represented as rectangular blocks, indicating layers within the LLM.
* **Probing Iteration:** A feedback loop involving ΔL (change in loss) and ˜L (tilde L).
* **General-Competence Detection Corpus:** Used for probing and evaluation.
* **Domain-adaptive Units:** Represented by star shapes.
* **General-critical Units:** Represented by circle shapes.
* **Identity Copy:** A process of duplicating layers.
* **Selective Expansion:** Expanding the LLM by adding copied layers.
* **Pretrain Dataset:** Used for decoupled tuning.
* **Decoupled Tuning:** Adjusting parameters based on the dataset.
* **Learning Rate Adaptation:** Adjusting learning rates for different units.
* **Next Token Prediction Loss (L):** The loss function used for training.
The diagram uses arrows to indicate flow direction and relationships between components. A legend in the bottom-right corner defines the symbols used:
* Trainable (Red)
* Frozen (Grey)
* Identity Copy (Orange)
* Update Flow (Yellow)
* Forward Flow (Purple)
* Probing (Blue)
* Domain Units (Star)
* General Units (Circle)
* Original Layer (White)
* Masked Layer (Light Grey)
* Expanded Layer (Dark Grey)
### Detailed Analysis / Content Details
**Stage 1: General-Competence Guided Selective Layer Expansion**
* **Step 1: General-Competence Aware Layer Importance Probing:**
* Parameters are fed into the LLM.
* The LLM interacts with the "General-Competence Detection Corpus."
* A probing iteration calculates ΔL (change in loss) and ˜L (tilde L).
* The diagram shows deactivated layers.
* **Step 2: Selective Expansion via Identity Copy:**
* The "General-Competence Importance" is used to "Select Lowest-K Layers."
* These layers are then "Copied" using an "Identity Copy" process.
* The copied layers are added to the LLM, resulting in "Selective Expansion."
* A "Layer Index Copy_L1...LM-K" is indicated.
**Stage 2: Adaptive Unit-Wise Decoupled Tuning**
* **Step 1: Unit-wise Neuron Decoupling:**
* The "General-Competence Detection Corpus" is used again.
* The diagram shows "Domain-adaptive Units" (stars) and "General-critical Units" (circles) within the layers.
* Unit-wise importance is calculated: w(i) = [w(i)y w(i)f].
* Forward and Update flows are indicated with purple and yellow arrows respectively.
* **Step 2: Dynamic Learning Rate Adaptation:**
* A "Pretrain Dataset" is used for "Decoupled Tuning."
* The diagram shows "Higher Learning Rate" applied to some units and "Lower Learning Rate" applied to others.
* An "Update" process is applied, resulting in an "Expanded Layer."
* The "Next Token Prediction Loss (L)" is used to guide the update.
### Key Observations
* The diagram emphasizes a selective expansion approach, focusing on expanding only the most important layers based on general competence.
* The decoupling of units and dynamic learning rate adaptation suggest a fine-tuning strategy tailored to individual units within the LLM.
* The use of the "General-Competence Detection Corpus" throughout the process highlights the importance of evaluating the LLM's general capabilities.
* The diagram visually separates trainable (red) and frozen (grey) parameters, indicating which parts of the model are being updated during each stage.
### Interpretation
This diagram presents a method for efficiently scaling and improving LLMs. The two-stage process aims to address the limitations of traditional full fine-tuning by selectively expanding the model's capacity and adapting learning rates at the unit level. The use of a "General-Competence Detection Corpus" suggests a focus on maintaining and enhancing the LLM's broad capabilities while adapting to specific tasks. The decoupling of units and dynamic learning rates likely aim to prevent catastrophic forgetting and improve the model's generalization performance. The diagram suggests a sophisticated approach to LLM optimization that balances scalability, efficiency, and performance. The visual separation of trainable and frozen parameters is a key element, indicating a parameter-efficient fine-tuning strategy. The use of "Identity Copy" suggests a method for preserving the original knowledge of the LLM while adding new capacity.