TECHNICAL ASSET FINGERPRINT
a367e695baa3e8aa1077aa4f
Click to view fullscreen
Press ESC or click to close
FOUND IN PAPERS
EXPERT: healer-alpha-free VERSION 1
RUNTIME: free/openrouter/healer-alpha
INTEL_VERIFIED
\n
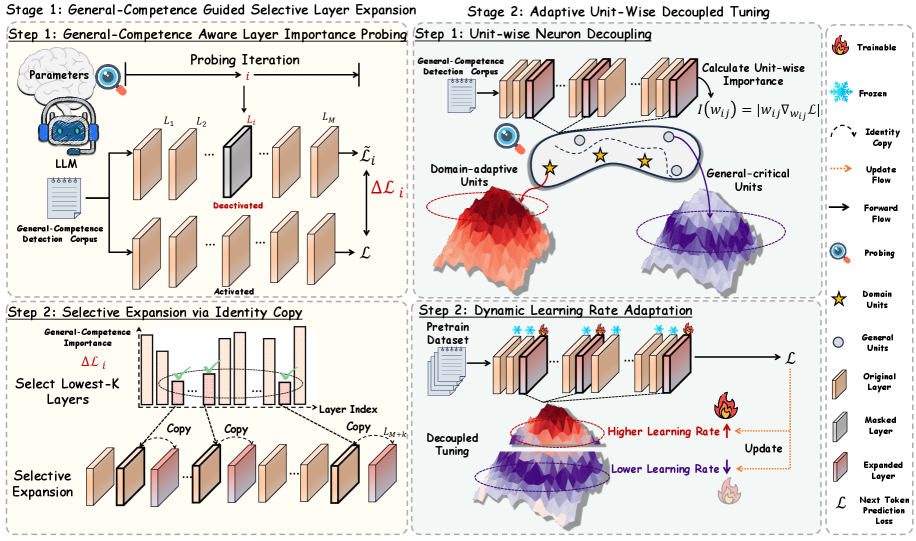
## Diagram: Two-Stage Framework for Efficient LLM Tuning
### Overview
The image is a technical diagram illustrating a two-stage framework for efficiently tuning Large Language Models (LLMs). The process aims to improve model performance on specific domains while preserving general capabilities. The diagram is divided into two main stages, each containing two steps, with a detailed legend on the right side.
### Components/Axes
The diagram is structured into four main quadrants, representing the sequential steps of the process.
**Legend (Right Side):**
* **Trainable:** Represented by a flame icon.
* **Frozen:** Represented by a snowflake icon.
* **Identity Copy:** Represented by a dashed arrow.
* **Update Flow:** Represented by an orange dotted arrow.
* **Forward Flow:** Represented by a solid black arrow.
* **Probing:** Represented by a magnifying glass icon.
* **Domain Units:** Represented by a yellow star.
* **General Units:** Represented by a white circle.
* **Original Layer:** A beige rectangle.
* **Masked Layer:** A grey rectangle.
* **Expanded Layer:** A pinkish-red rectangle.
* **Next Token Prediction Loss (ℒ):** The loss function symbol.
**Stage 1: General-Competence Guided Selective Layer Expansion**
* **Step 1: General-Competence Aware Layer Importance Probing**
* **Components:** An LLM icon, a "General-Competence Detection Corpus" document icon, and a series of model layers labeled L₁, L₂, ..., Lᵢ, ..., Lₘ.
* **Process:** The corpus is fed into the LLM. A "Probing Iteration" process evaluates each layer. Layer Lᵢ is shown as "Deactivated" (grey), while others are "Activated" (beige). The output is a change in loss (Δℒᵢ) for each layer.
* **Step 2: Selective Expansion via Identity Copy**
* **Components:** A bar chart titled "General-Competence Importance Δℒᵢ" with "Layer Index" on the x-axis. Below it, a series of layers undergoing "Selective Expansion."
* **Process:** The bar chart identifies the "Select Lowest-K Layers" (highlighted with a green oval). These selected layers are then duplicated ("Copy") to create new "Expanded Layers" (pinkish-red), resulting in a model with layers L₁, L₂, ..., Lₘ, Lₘ₊₁, ..., Lₘ₊ₖ.
**Stage 2: Adaptive Unit-Wise Decoupled Tuning**
* **Step 1: Unit-wise Neuron Decoupling**
* **Components:** A "General-Competence Detection Corpus," a neural network visualization, and two 3D surface plots.
* **Process:** The corpus is used to "Calculate Unit-wise Importance" using the formula I(wᵢⱼ) = |wᵢⱼ ∇wᵢⱼ ℒ|. This process decouples neurons into "Domain-adaptive Units" (associated with a red/orange surface plot) and "General-critical Units" (associated with a purple/blue surface plot).
* **Step 2: Dynamic Learning Rate Adaptation**
* **Components:** A "Pretrain Dataset," a neural network with mixed frozen (snowflake) and trainable (flame) units, and the two surface plots from the previous step.
* **Process:** During "Decoupled Tuning," different learning rates are applied. "Domain-adaptive Units" (red/orange plot) receive a "Higher Learning Rate ↑," while "General-critical Units" (purple/blue plot) receive a "Lower Learning Rate ↓." The process is guided by the Next Token Prediction Loss (ℒ).
### Detailed Analysis
The diagram meticulously details a pipeline for parameter-efficient fine-tuning.
**Stage 1 Analysis:**
1. **Probing:** The system first identifies which layers in the pre-trained LLM are least important for maintaining general competence (low Δℒᵢ). This is a diagnostic step.
2. **Expansion:** It then selectively adds capacity (new layers) only after these identified low-importance layers. The "Identity Copy" suggests the new layers are initialized as copies of existing ones, providing a scaffold for specialization.
**Stage 2 Analysis:**
1. **Decoupling:** Within each layer, individual neurons (units) are classified based on their importance for the general task. This creates a fine-grained, unit-level mask.
2. **Adaptive Tuning:** The core innovation is applying different optimization dynamics. Neurons deemed critical for general knowledge are updated slowly (low learning rate) to prevent catastrophic forgetting. Neurons identified as adaptable to the new domain are updated aggressively (high learning rate) to quickly acquire new skills.
### Key Observations
* **Spatial Grounding:** The legend is positioned on the far right, vertically aligned with the main diagram. The two stages are clearly separated by a vertical dashed line. Within each stage, the two steps are arranged top-to-bottom.
* **Visual Metaphors:** The use of fire (trainable) and ice (frozen) is a clear visual metaphor. The 3D surface plots effectively visualize the concept of different "optimization landscapes" for domain-adaptive vs. general-critical units.
* **Flow Clarity:** The diagram uses a combination of solid, dashed, and dotted arrows to distinguish between forward pass, copying operations, and update flows, making the process logic easy to follow.
* **Color Consistency:** Colors are used consistently: beige for original/frozen components, grey for masked/deactivated, pinkish-red for expanded/trainable, and the red/orange vs. purple/blue dichotomy for domain vs. general units.
### Interpretation
This diagram presents a sophisticated, multi-faceted approach to solving a core challenge in LLM adaptation: **balancing specialization with generalization.**
The framework's logic is Peircean in its investigative approach:
1. **Abduction (Inference to the Best Explanation):** It hypothesizes that not all model components are equally valuable for general knowledge. By probing with a general-competence corpus, it abduces which layers are "weakest" in this regard and thus best candidates for expansion and specialization.
2. **Induction (Pattern Recognition):** It induces, at a finer granularity, that within any layer, some neurons are more critical for general tasks than others. This pattern is used to create the unit-wise decoupling.
3. **Deduction (Applying the Rule):** The deduced rule is: "If a unit is general-critical, update it slowly; if it is domain-adaptive, update it quickly." This rule is then applied during the tuning stage.
The **notable innovation** is the move from layer-level to neuron-level (unit-wise) control. This allows for a much more surgical and efficient tuning process than methods that freeze or adapt entire layers uniformly. The "Selective Expansion" in Stage 1 is also notable—it doesn't just tune existing parameters but intelligently adds new capacity where it's most likely to be beneficial, guided by the initial probing.
In essence, the diagram illustrates a method to make LLM tuning both **more effective** (by aggressively learning new domain patterns) and **more efficient** (by only modifying the most relevant parameters and adding capacity judiciously), while actively protecting the model's foundational general abilities.
DECODING INTELLIGENCE...