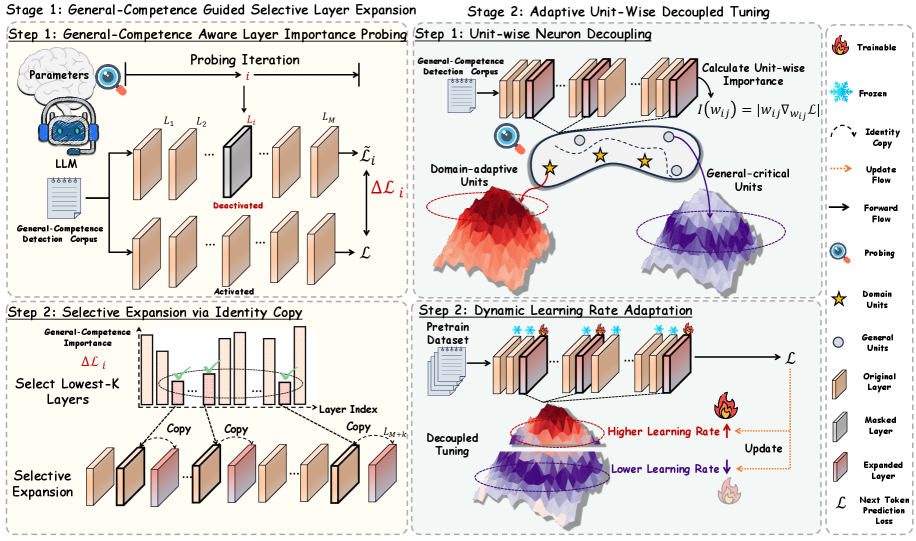
## Diagram: Two-Stage Adaptive Model Tuning Framework
### Overview
The diagram illustrates a two-stage framework for domain-adaptive model tuning. Stage 1 focuses on identifying and expanding general-competence layers, while Stage 2 involves decoupling unit-wise importance and dynamically adapting learning rates. Key components include layer importance probing, selective expansion, neuron decoupling, and learning rate adaptation.
### Components/Axes
#### Stage 1: General-Competence Aware Layer Importance Probing
- **Inputs**: Parameters, LLM, General-Competence Detection Corpus
- **Process**:
- Probing Iteration (`i`) evaluates layers (`L₁` to `Lₘ`) for general-competence importance (`ΔLᵢ`).
- Layers are marked as "Activated" or "Deactivated" based on importance scores.
- **Output**: Selective Expansion via Identity Copy (Step 2).
#### Stage 2: Adaptive Unit-Wise Decoupled Tuning
- **Substeps**:
1. **Unit-wise Neuron Decoupling**:
- Calculates unit-wise importance (`I(wᵢⱼ) = |wᵢⱼ∇ₐⱼL|`).
- Identifies "Domain-adaptive Units" (red mountain) and "General-critical Units" (purple mountain).
- Symbols:
- ⭐: Domain-adaptive units (trainable).
- ⚪: General-critical units (frozen).
2. **Dynamic Learning Rate Adaptation**:
- Pretrain dataset → Decoupled tuning.
- Learning rates: Higher for domain-adaptive units (↑), lower for general units (↓).
#### Legends (Right Panel)
- **Symbols**:
- 🔥: Trainable (Domain-adaptive units).
- ❄️: Frozen (General-critical units).
- ➡️: Update flow (forward flow).
- 🔍: Probing.
- 📄: General-competence detection corpus.
### Detailed Analysis
#### Stage 1: Layer Importance Probing
- **Flow**:
1. Parameters and LLM feed into probing iterations.
2. Layers (`L₁` to `Lₘ`) are evaluated for general-competence importance (`ΔLᵢ`).
3. Lowest-K layers (based on `ΔLᵢ`) are selected for expansion via identity copy.
#### Stage 2: Neuron Decoupling
- **Unit Importance**:
- Domain-adaptive units (red) have higher importance scores (`I(wᵢⱼ)`) and are marked as trainable (🔥).
- General-critical units (purple) are frozen (❄️) and have lower importance.
#### Stage 2: Learning Rate Adaptation
- **Rate Adjustment**:
- Domain-adaptive units receive higher learning rates (🔥).
- General units receive lower learning rates (↓).
### Key Observations
1. **Selective Expansion**: Only layers with low general-competence importance (`ΔLᵢ`) are expanded via identity copy.
2. **Decoupling**: Neuron importance is calculated independently of the original layer structure.
3. **Learning Rate Bias**: Domain-adaptive units are prioritized during tuning.
### Interpretation
This framework optimizes model adaptation by:
1. **Focusing on General Competence**: Identifying and expanding layers critical for general tasks.
2. **Decoupling Units**: Separating domain-specific and general units to avoid catastrophic forgetting.
3. **Dynamic Tuning**: Allocating computational resources (learning rates) to high-impact units.
The process suggests a balance between retaining general capabilities and adapting to new domains, with explicit mechanisms to prevent overfitting to domain-specific data.