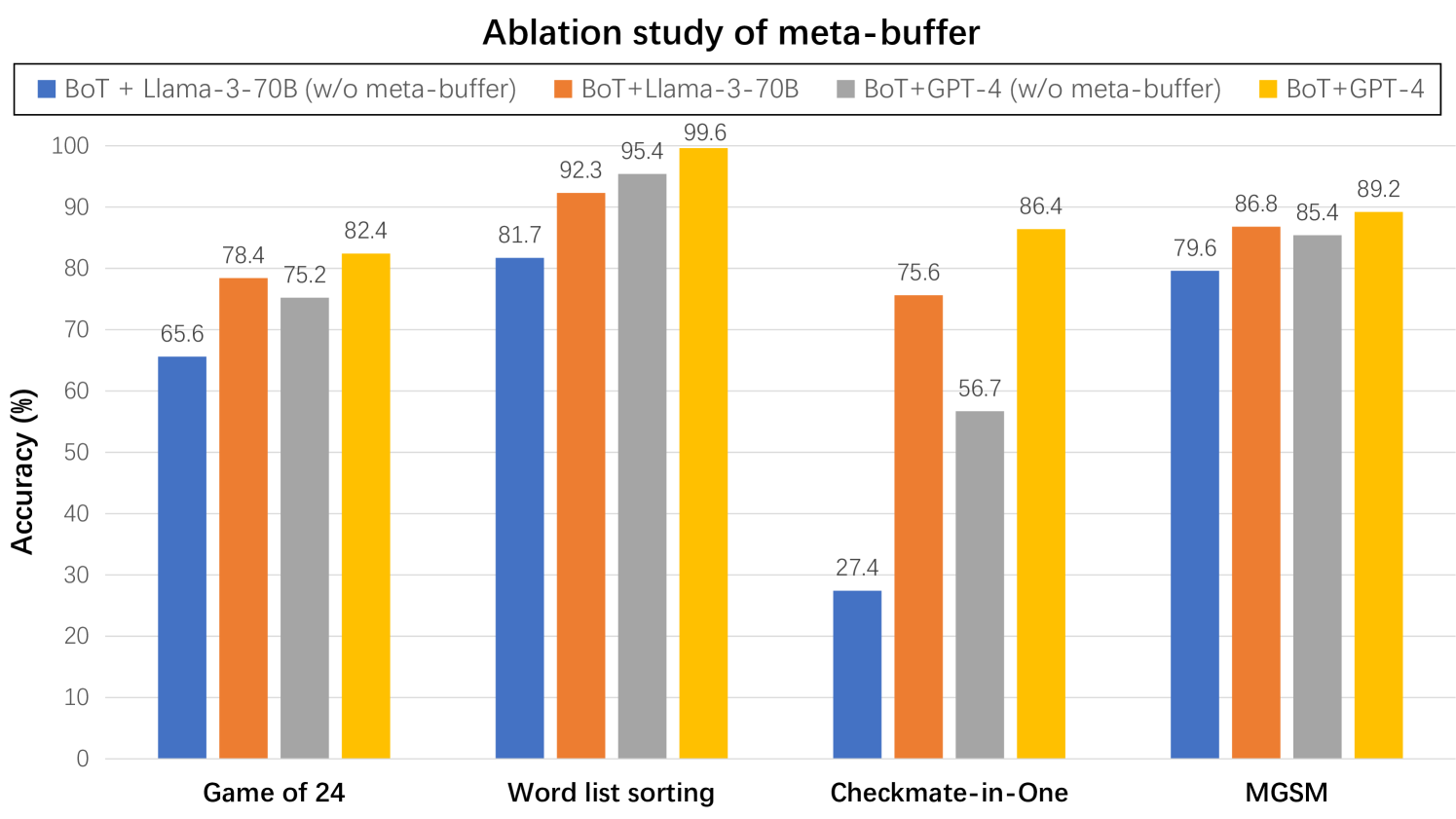
## Bar Chart: Ablation study of meta-buffer
### Overview
The chart compares the accuracy of four model configurations across four tasks: Game of 24, Word list sorting, Checkmate-in-One, and MGSM. Each task has four grouped bars representing different model variants with/without a meta-buffer.
### Components/Axes
- **X-axis**: Tasks (Game of 24, Word list sorting, Checkmate-in-One, MGSM)
- **Y-axis**: Accuracy (%) from 0 to 100
- **Legend**:
- Blue: BoT + Llama-3-70B (w/o meta-buffer)
- Orange: BoT+Llama-3-70B
- Gray: BoT+GPT-4 (w/o meta-buffer)
- Yellow: BoT+GPT-4
### Detailed Analysis
1. **Game of 24**:
- Blue (BoT + Llama-3-70B w/o meta-buffer): 65.6%
- Orange (BoT+Llama-3-70B): 78.4%
- Gray (BoT+GPT-4 w/o meta-buffer): 75.2%
- Yellow (BoT+GPT-4): 82.4%
2. **Word list sorting**:
- Blue: 81.7%
- Orange: 92.3%
- Gray: 95.4%
- Yellow: 99.6%
3. **Checkmate-in-One**:
- Blue: 27.4%
- Orange: 75.6%
- Gray: 56.7%
- Yellow: 86.4%
4. **MGSM**:
- Blue: 79.6%
- Orange: 86.8%
- Gray: 85.4%
- Yellow: 89.2%
### Key Observations
- **BoT+GPT-4 (yellow)** consistently achieves the highest accuracy across all tasks, with a peak of 99.6% in Word list sorting.
- **BoT + Llama-3-70B (blue)** shows the lowest performance, particularly in Checkmate-in-One (27.4%).
- The meta-buffer improves accuracy for both Llama-3-70B and GPT-4 models, with the largest relative gain observed in Checkmate-in-One (BoT+GPT-4: +29.7% with meta-buffer).
- Word list sorting demonstrates near-perfect performance for BoT+GPT-4 (99.6%), suggesting task-specific optimization.
### Interpretation
The data demonstrates that:
1. The meta-buffer significantly enhances model performance, especially for complex tasks like Checkmate-in-One where BoT+GPT-4 with meta-buffer achieves 86.4% vs 56.7% without.
2. GPT-4-based models outperform Llama-3-70B variants across all tasks, with the gap widening in more challenging scenarios.
3. The absence of the meta-buffer disproportionately impacts Llama-3-70B's performance, suggesting architectural limitations in handling task complexity without external memory augmentation.
4. Word list sorting's near-perfect accuracy for BoT+GPT-4 indicates potential overfitting or specialized optimization for this particular task type.
The ablation study highlights the critical role of meta-buffers in enabling large language models to handle complex reasoning tasks, with GPT-4 showing superior base capabilities but requiring similar architectural enhancements for optimal performance.