## Bar Chart: Ablation study of meta-buffer
### Overview
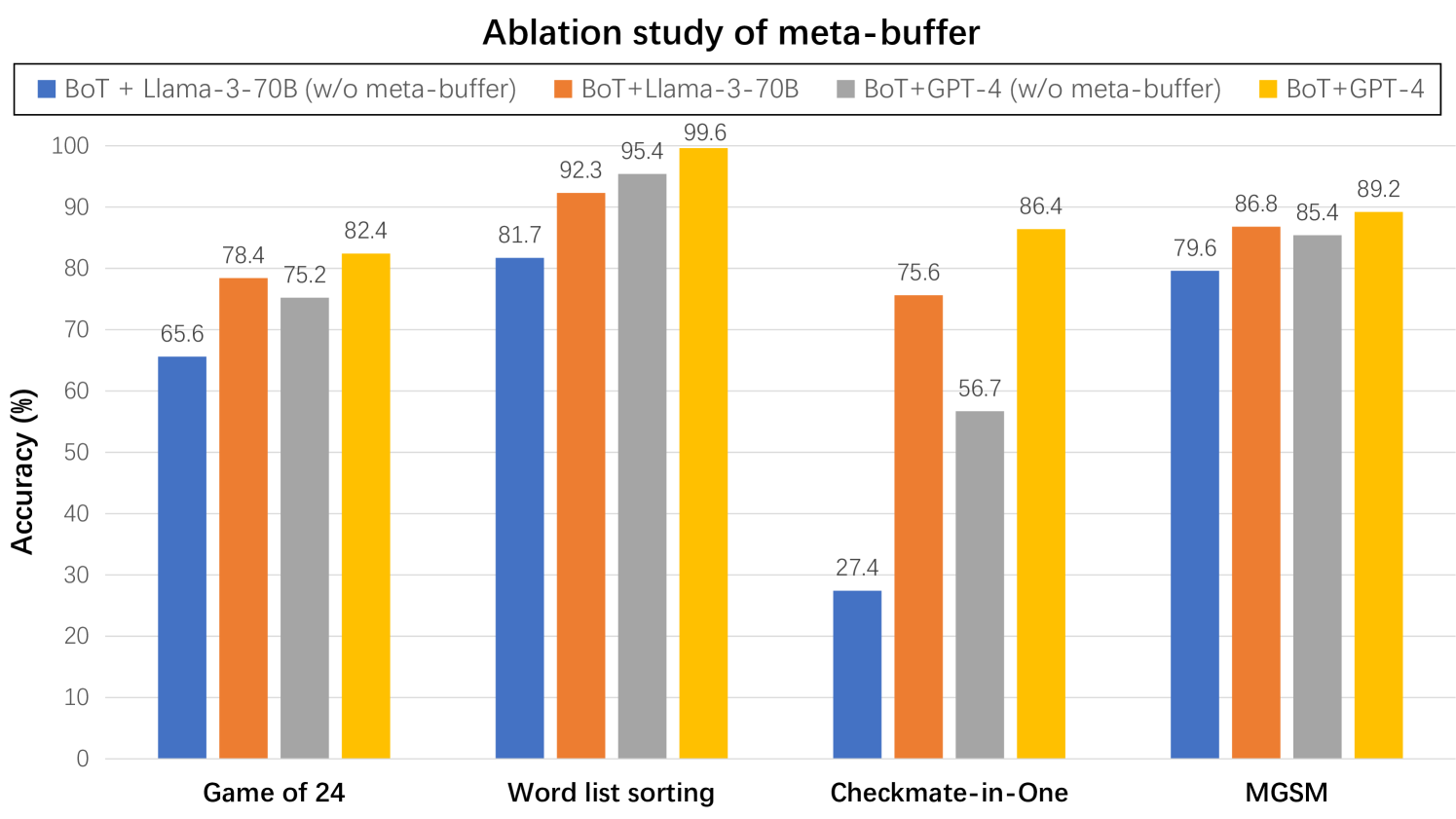
The image is a bar chart displaying the accuracy (%) of different models on four tasks: Game of 24, Word list sorting, Checkmate-in-One, and MGSM. The models compared are BoT + Llama-3-70B (with and without meta-buffer) and BoT + GPT-4 (with and without meta-buffer).
### Components/Axes
* **Title:** Ablation study of meta-buffer
* **X-axis:** Categorical axis representing the tasks: Game of 24, Word list sorting, Checkmate-in-One, MGSM.
* **Y-axis:** Numerical axis labeled "Accuracy (%)", ranging from 0 to 100 with increments of 10.
* **Legend:** Located at the top of the chart.
* Blue: BoT + Llama-3-70B (w/o meta-buffer)
* Orange: BoT + Llama-3-70B
* Gray: BoT + GPT-4 (w/o meta-buffer)
* Yellow: BoT + GPT-4
### Detailed Analysis
Here's a breakdown of the accuracy for each model on each task:
* **Game of 24:**
* BoT + Llama-3-70B (w/o meta-buffer) (Blue): 65.6%
* BoT + Llama-3-70B (Orange): 78.4%
* BoT + GPT-4 (w/o meta-buffer) (Gray): 75.2%
* BoT + GPT-4 (Yellow): 82.4%
* **Word list sorting:**
* BoT + Llama-3-70B (w/o meta-buffer) (Blue): 81.7%
* BoT + Llama-3-70B (Orange): 92.3%
* BoT + GPT-4 (w/o meta-buffer) (Gray): 95.4%
* BoT + GPT-4 (Yellow): 99.6%
* **Checkmate-in-One:**
* BoT + Llama-3-70B (w/o meta-buffer) (Blue): 27.4%
* BoT + Llama-3-70B (Orange): 75.6%
* BoT + GPT-4 (w/o meta-buffer) (Gray): 56.7%
* BoT + GPT-4 (Yellow): 86.4%
* **MGSM:**
* BoT + Llama-3-70B (w/o meta-buffer) (Blue): 79.6%
* BoT + Llama-3-70B (Orange): 86.8%
* BoT + GPT-4 (w/o meta-buffer) (Gray): 85.4%
* BoT + GPT-4 (Yellow): 89.2%
### Key Observations
* The "Word list sorting" task consistently shows the highest accuracy across all models.
* The "Checkmate-in-One" task has the lowest accuracy for BoT + Llama-3-70B (w/o meta-buffer) compared to other tasks and models.
* For all tasks, the models *with* meta-buffer (orange and yellow) outperform their counterparts *without* meta-buffer (blue and gray).
* BoT+GPT-4 (yellow) generally achieves the highest accuracy among the four models.
### Interpretation
The chart illustrates the impact of the meta-buffer on the performance of BoT models with different language models (Llama-3-70B and GPT-4) across various tasks. The consistent improvement in accuracy when using the meta-buffer suggests its effectiveness in enhancing the models' capabilities. The "Checkmate-in-One" task appears to be particularly challenging for the BoT + Llama-3-70B model without the meta-buffer, indicating a potential area for improvement. The superior performance of BoT + GPT-4 suggests that GPT-4 may be better suited for these tasks or that it benefits more from the meta-buffer.