\n
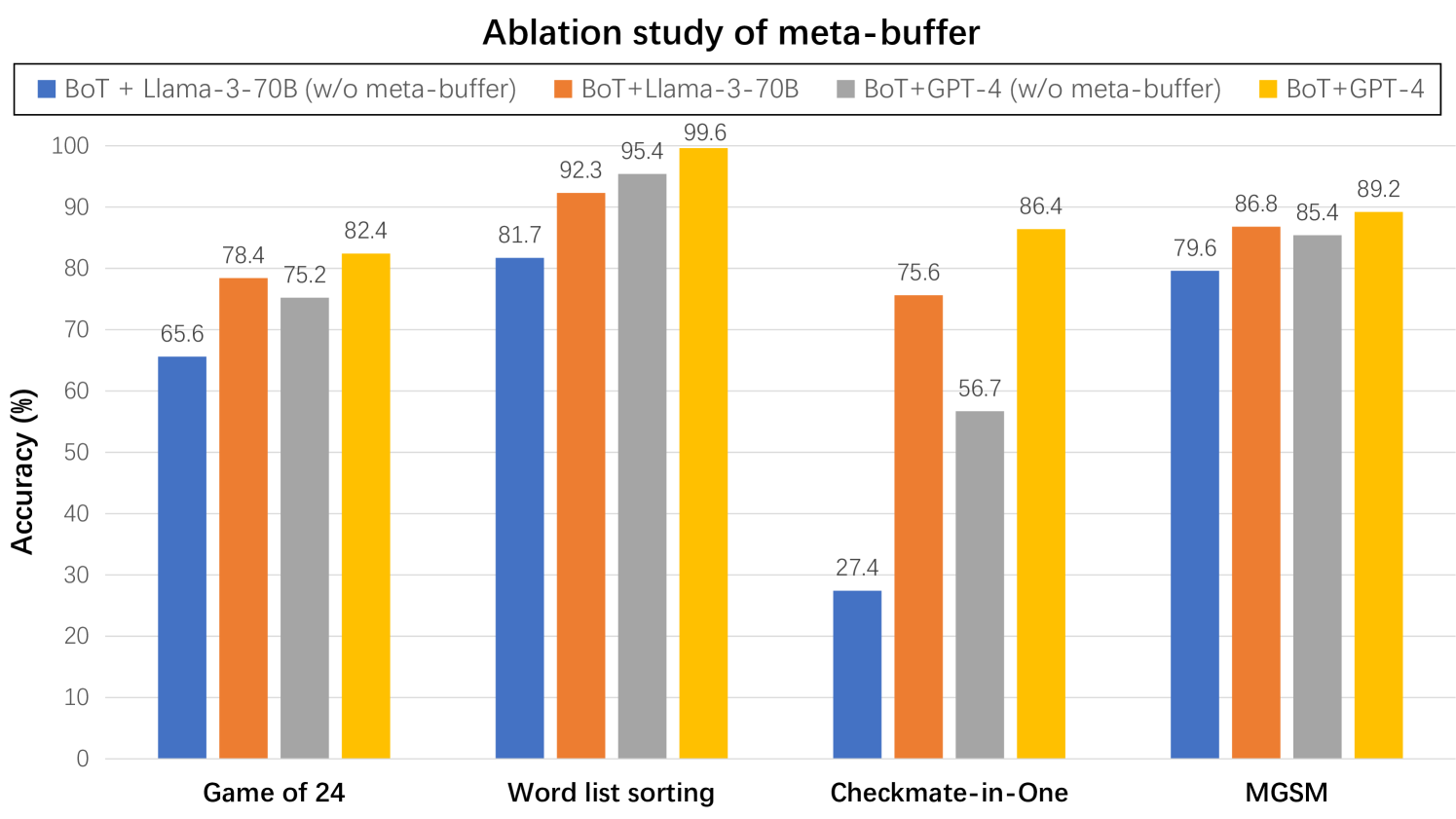
## Bar Chart: Ablation study of meta-buffer
### Overview
This bar chart presents a comparative analysis of the accuracy of different language model configurations on four distinct tasks: Game of 24, Word list sorting, Checkmate-in-One, and MGSM. The configurations include combinations of BoT (likely "Blend of Thoughts") with Llama-3-70B and GPT-4, both with and without a "meta-buffer." The chart aims to demonstrate the impact of the meta-buffer on the performance of these models.
### Components/Axes
* **X-axis:** Represents the four tasks: "Game of 24", "Word list sorting", "Checkmate-in-One", and "MGSM".
* **Y-axis:** Represents "Accuracy (%)", ranging from 0 to 100.
* **Legend:** Located at the top-left corner, defines the four data series:
* Blue: BoT + Llama-3-70B (w/o meta-buffer)
* Red: BoT + Llama-3-70B (w/ meta-buffer)
* Orange: BoT + GPT-4 (w/o meta-buffer)
* Yellow: BoT + GPT-4 (w/ meta-buffer)
### Detailed Analysis
The chart consists of four groups of bars, one for each task. Within each group, there are four bars representing the accuracy of each model configuration.
**Game of 24:**
* BoT + Llama-3-70B (w/o meta-buffer): Approximately 65.6% accuracy.
* BoT + Llama-3-70B (w/ meta-buffer): Approximately 78.4% accuracy.
* BoT + GPT-4 (w/o meta-buffer): Approximately 75.2% accuracy.
* BoT + GPT-4 (w/ meta-buffer): Approximately 82.4% accuracy.
**Word list sorting:**
* BoT + Llama-3-70B (w/o meta-buffer): Approximately 81.7% accuracy.
* BoT + Llama-3-70B (w/ meta-buffer): Approximately 92.3% accuracy.
* BoT + GPT-4 (w/o meta-buffer): Approximately 95.4% accuracy.
* BoT + GPT-4 (w/ meta-buffer): Approximately 99.6% accuracy.
**Checkmate-in-One:**
* BoT + Llama-3-70B (w/o meta-buffer): Approximately 27.4% accuracy.
* BoT + Llama-3-70B (w/ meta-buffer): Approximately 56.7% accuracy.
* BoT + GPT-4 (w/o meta-buffer): Approximately 75.6% accuracy.
* BoT + GPT-4 (w/ meta-buffer): Approximately 86.4% accuracy.
**MGSM:**
* BoT + Llama-3-70B (w/o meta-buffer): Approximately 79.6% accuracy.
* BoT + Llama-3-70B (w/ meta-buffer): Approximately 86.8% accuracy.
* BoT + GPT-4 (w/o meta-buffer): Approximately 85.4% accuracy.
* BoT + GPT-4 (w/ meta-buffer): Approximately 89.2% accuracy.
### Key Observations
* The meta-buffer consistently improves the accuracy of both Llama-3-70B and GPT-4 across all four tasks.
* GPT-4 generally outperforms Llama-3-70B, regardless of the presence of the meta-buffer.
* The largest performance gains from the meta-buffer are observed in the "Word list sorting" and "Checkmate-in-One" tasks.
* The "Checkmate-in-One" task has the lowest overall accuracy scores, indicating it is the most challenging task for these models.
### Interpretation
The data strongly suggests that the meta-buffer is a beneficial component for improving the accuracy of these language models. The consistent performance gains across all tasks indicate that the meta-buffer provides a generalizable improvement, rather than being specific to a particular task. The larger gains observed in "Word list sorting" and "Checkmate-in-One" might indicate that these tasks benefit more from the additional contextual information or reasoning capabilities provided by the meta-buffer. The superior performance of GPT-4 suggests that larger and more capable models are better able to leverage the benefits of the meta-buffer. The relatively low accuracy on "Checkmate-in-One" could be due to the complexity of chess-related reasoning, or the limitations of the models in handling such specialized tasks. The chart provides empirical evidence supporting the integration of a meta-buffer into language model architectures to enhance their performance on a variety of tasks.